神经网络初学者的炼丹参考手册
近期,AI in RTC 创新大赛(https://challenge.rtcdeveloper.com/ai-in-rtc/)现已开启报名,面向所有熟悉超分辨率模型的开发者,发起“超分辨率图像质量挑战”、“超分辨率算法性能挑战”。为了便于部分初学者在比赛中少走弯路,我们分享一些神经网络的入门知识点。
本文将概述一下训练神经网络的入门级知识点,从循环神经元的选择、激活函数、过拟合,到优化器的选择,并给出作者的个人建议。
1.循环神经单元的选择
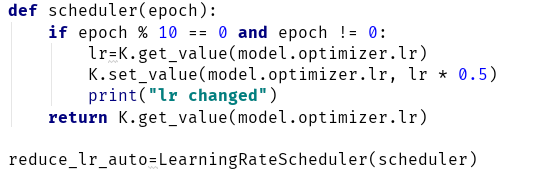
如果神经网络中需要用到循环神经单元,首先需要从多个现有模板里选择一个。单向循环神经单元现在主流的有RNN/LSTM/GRU,这几个循环神经单元综合来说性价比是RNN RNN是一个设计比较早的结构,缺点是每个时间步的输入的比重是一样的,如果输入的时间步过多,RNN会遗忘较早的信息。 GRU相当于是一个简化版的LSTM,GRU只有三个门,并且融合了细胞状态C和输出状态h,这样GRU的计算复杂度和模型体积大概只有LSTM的3/4,并且更容易训练。 除此之外,还有一个非主流的模型SRU,SRU使用大量哈达玛乘积代替了传统的矩阵点乘,并且当前时刻的输出已经不依赖之前时间步的输出,只依赖前一时刻的细胞状态。该模型的一大优点是可以对其进行并行化优化,提升其在GPU上的计算性能。相同hidden layer数量的SRU的模型体积和计算复杂度大概是GRU的1/2,但误差有所上升。SRU的详细介绍可以参考另外一篇征文。 主流激活函数有sigmoid/tanh/relu/leakyrelu/prelu等。 relu系列主要是为了解决深度神经网络中梯度消失的问题,实际上,在relu设计出来之前,深度神经网络还是很依赖pretraining+finetuning这种方法的,relu的作用我个人理解的是和droupout/L1 regularization的功能类似,即使得部分权重失活,达到稀疏网络的目的。 leakyrelu和prelu是relu的变种,这两个激活函数在输入为负的时候仍有输出,但负值输入会被乘上一个权重,leakyrelu需要手动设置这个权重,prelu则会通过训练得到整个权重。我个人的实验结果,性能上relu 个人推荐首选relu系列激活函数,因为它在大多数场景下都有较明显的优势。 过拟合近乎是训练网络时无法避免的问题,严重的过拟合会在训练集上跑出完美的结果,却完全无法在测试集上工作。总的来说,目前防止过拟合的手段都围绕着一个思想:稀疏网络。 常用的防止过拟合的方法主要有:dropout、regularization,上述的relu系列激活函数也算是一种方法。总体来说,防止过拟合的思路是使网络变得稀疏,稀疏可以简单理解为把一个大网络里所有权重共同协作的方式改为大网络里多个小网络并行计算,这种描述不太准确,但可以大概这么理解。dropout实现稀疏的方法比较直接,就是在训练的时候随机让一些权重失活,在使用网络时时恢复这些权重,并将输出除以(1-α),其中α是dropout的比例。regularization的中文翻译为“正则化”,这个不太好理解,可能把它理解为“限制”更好一些,它其实是针对权重加了一个限制。regularization分为L1 regularization和L2 regularization,L1 regularization是在反向传播误差时加上权重本身的一个一阶范数,它的作用是,使得最终训练出网络的权重有更多的0值,实现了稀疏网络的目的;L2 regularization是在权重上加了权重本身的二阶范数,这使得最终训练出网络的权重都变小并趋近于0,但不等于0,也实现了稀疏网络的目的。 关于为什么稀疏的网络可以防止过拟合,我的理解是,一个大网络里其实有好多权重是没什么用的,但这些权重计算出的信息会去很好的拟合训练集,但会在验证集和测试集上引入噪声,因此,通过稀疏网络,使得这些“无用权重”扮演的角色变小,网络就能更好的拟合从来没见过的测试集。 优化器是训练网络时的梯度下降的方法,目前主流优化器有SGD、Adagrad、Adadelta、RMSprop、Adam、NAdam这几种。 其中,SGD的全称是stochastic gradient descent,它的思想是每次只训练少量样本进行梯度下降,优点是相比之前的BGD(Batch gradient descent)占用内存少一些,能够进行大数据量的训练,缺点是因为每次只用少量样本,可能loss是震荡下降的,因此SGD很依赖于部分超参的设置,如学习率在什么时候衰减对SGD来说是非常重要的,可以暂时这么说,如果SGD的超参设置的非常完美,那它就能训练出最佳的模型,但一般来说这个是很难的。 Adagrad的最大特点在于它通过累计计算过去的梯度(就是导数),给不同参数不同的学习率,但这个优化器的一个最大的问题是,累计的梯度越大,学习率越小,很容易出现在训练未结束时学习率就下降到非常低的问题。 Adadelta则修正了Adagrad的学习率下降过早的问题,它通过指数加权平均方法计算过去N个梯度值,不再是从第一次训练一直开始累积梯度,这样就从一定程度上避免了上述问题。此外,Adadelta还可以自己计算学习率,因此不需要预设。 RMSprop可以看做Adadelta的一个超参特殊版,值得一提的是,RMSprop在训练循环神经网络时的表现不错。 Adam是目前最容易被选择的一个优化器,它可以看做是RMSprop+Momentum,Momentum可以计算过去训练的累计梯度,如果历史梯度下降方向和当前下降方向一致,学习率就会被加强,如果历史梯度下降方向和当前方向不一致,学习率就会被减弱。需要注意的是,Momentum累计梯度时累计的是梯度本身的值,而上面几个优化器本身累计梯度时累计的是梯度的平方,所以Momentum和优化器本身相当于是两个并行的控制函数,这两个函数的超参也是分别设置的。 NAdam相当于Adam+Nesterov,Nesterov相当于对Momentum又加了一个校正,理论上可以达到更好的效果,但问题是,施加这个校正需要重新计算一遍梯度下降,所以NAdam的计算量差不多是Adam的两倍,因此要慎用NAdam,除非不在意训练时间。 综上,Adam是万能公式,可以在训练循环神经网络时尝试RMSprop,尽量避免使用SGD,除非对自己的调参能力非常自信。此外,Adam这种带Momentum的优化器很容易在训练末期陷入抖动,无法下降到最优点,一种比较麻烦的处理方法是,先使用Adam训练,再换成SGD进行最后的收尾工作。 学习率最重要的是初始值设定和衰减方法,初始值设定根据不同种类的目标有所不同,个人建议对于一个新的模型,开始不要尝试太大的学习率,可以用小一点的学习率,如0.001试一下,训练完毕后,把误差下降曲线打印出来,观察loss曲线,理想的loss曲线应该是类似于y=1/x,如果曲线过于平滑,说明学习率太小,如果误差曲线下降的很快并伴随着上下波动,说明学习率过大。 衰减方法主要有按轮次衰减和根据loss衰减,以keras为例,如果按照10轮训练衰减一次,每次衰减一半,需要调用LearningRateSchedule(): 如果想根据监控验证集的loss调整学习率,需要调用ReduceLROnPlateau(),当连续n轮loss不下降,进行学习率的衰减。 以下总结仅供参考,不一定对每个task都起作用 (1)权重初始化:推荐orthogonal初始化,可以有效避免梯度消失或爆炸,原因可见这篇博文。 (2)Attention层:Attention层多用于语音识别或转化,Attention通过对每个timestep分配权重,设定了一个特定注意力区域,而不是把注意力都集中在最新时刻的输入。现在讲Attention的文章有很多,这里就不再赘述了。 (3)当多循环单元串联时,建议不要修改循环单元内部激活函数,避免梯度爆炸。这就带来一个问题,以GRU为例,输出状态h经过的是一个tanh。如果只单纯串联多个循环单元,整个网络没有relu来稀疏网络,导致网络性能下降。 个人建议多层串联循环网络架构如下:GRU-PRelu-TimeDistributed-tanh-GRU…,或者是GRU-PRelu-LayerNormalization-GRU…。这样做的原因是:加入Prelu用来稀疏网络,增强网络鲁棒性;加入TimeDistributed用来实现更复杂的类Attention的功能;最后的激活函数选择tanh是因为希望数据在输入下一个循环单元前范围限制在-1~1之间。LayerNormalization可以重置数据的分布,目的是和上述做法差不多的。 (4)Batch Normalization:该层可以将输入的批数据强行变成均值为0,方差为1的高斯分布。理论上Batch Normalization层带来的白化数据可以加速训练,但我实验下来在RNN系列上误差有所上升,且Batch Normalization性能依赖于batch size,对训练机器的性能有考验。个人推荐在RNN类的网络上还是使用LayerNormalization好一些。 (5)如果网络没有明显的过拟合,或者只过拟合了一丢丢,在回归问题上建议不要使用Regularization,Regularization可以较明显的泛化网络输出结果,使得模型在测试集上的表现也出现一定下降。 (6)结合CNN的循环单元,如果需要使用,建议把CNN搁到循环单元后面。这么做一是避免破坏原始输入数据的时域相关特性,二是参考了这篇文章里的实验结果。 (7)关于数据预处理:数据归一化在无特殊情况下都是建议做的。关于变化域的数据预处理,之前尝试过对信号进行PCA后输入到神经网络,但出现了部分白化后数据梯度爆炸的现象,而且PCA没有带来很明显的正向增益,却会引入一定复杂度,在数据预处理时,需要谨慎选用PCA,但PCA可以有效实现降维,当数据维数过大导致网络难以拟合时,PCA是一个不错的选择。 (8)Loss function的确定:对于回归问题来说,如果数据是归一化的,建议使用MAE或其近似变种就好,MSE可能会使其性能下降。分类问题暂时没有做过相关项目,就不写了。 (9)网络架构的优化:循环神经网络主要的模型体积和计算复杂度来源于那几个门控单元,其随着门控单元隐层数量平方级增加,除了剪枝等方法,一种简单的优化方法是,把大的循环单元拆分成多个小的循环单元,尽量减少大矩阵相乘的次数。但这样需要更多巧妙的小设计去弥补带来的误差,可以参考已有类似网络的设计,如Wavenet等。 文中所述不一定准确,如有不对的地方烦请联系我:https://rtcdeveloper.com/t/topic/14596 最后,AI in RTC 创新挑战赛正在报名正,欢迎熟悉超分辨率算法模型的高手们报名,现金大奖与 Offer 直通车等着你:https://challenge.rtcdeveloper.com/ai-in-rtc/
LSTM是为了解决上述RNN缺点而设计出来的,相比RNN,LSTM主要增加了4个门和1个细胞状态,用来控制哪些信息需要遗忘,哪些信息需要记住,但LSTM的缺点是模型比较复杂,权重很多,比较难训练且模型比较大。2.激活函数的选择
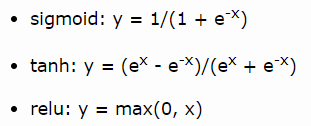
值得一提的是,循环神经单元门内的激活函数一般是sigmoid,输出的激活函数一般是tanh,这两个一般来说不建议修改,错误的修改容易引起梯度爆炸。3.过拟合及防止过拟合的手段
4.优化器的选择
5.学习率的设置
6.其余细节