算法揭秘!阿里云推出高效病毒基因序列检索功能,它的底层逻辑原来是这样的...
简介: 作者:汉朝,阿里云数据库算法专家
1.背景介绍
2019年年底,中国的新兴的商业中心武汉,爆发了一种新型的冠状病毒,在流行的两个多月中,在中国造成了3300多人死亡,8万2千多人感染。随着疫情的进一步蔓延,目前已经横跨了109个国家,造成了80多万人感染,4万多人失去了生命。到目前为止,疫情使得50多个国家停摆,全世界范围内造成了数千亿美元的经济损失。阿里云提供高效基因序列检索助力冠状病毒序列分析用于疫情防治。
对于当下疫情,基因序列分析技术主要用在一下几个方面。
第一,用在新冠状病毒的溯源和分析,可以帮助人们找到病毒宿主,做好有效的防范。通过基因匹配技术,我们可以发现,蝙蝠和穿山甲身上的冠状病毒的RNA序列匹配度达到到了96%和99.7%,因此穿山甲和蝙蝠很可能是新型冠状病毒的宿主。
第二,通过基因序列分析,对基因序列进行功能区域划分,了解各个模块的功能,从而更好地分析出病毒的复制,传播的过程。找到关键节点,设计出相关的药物和疫苗。
第三,同时也可以检索到与冠状病毒相似的病毒基因序列,比方说SARS,MERS等病毒。从而可以借鉴相关的药物靶点的设计机制,更快更高效的设计出来相关的检测试剂盒,疫苗,以及相关的治疗药物。
但是,当前的的基因匹配算法太慢,因而迫切的需要高效的匹配算法来进行基因序列分析。阿里云AnalyticDB团队将基因序列片段转化成对应的1024维的向量特征。两个基因片段的匹配问题,转换成了两个向量的距离计算问题,从而大大的降低了计算开销,系统可以在毫秒级别就可以返还回来相关的基因片段,完成基因片段的初筛。
然后,使用基因相似计算的BLAST算法[6],完成基因相似度的精排,从而高效的完成基因序列的匹配计算。匹配算法由原来O(M+N)的算法复杂度,降低到了O(1)。同时,阿里云AnalyticDB提供了强大的机器学习分析工具,通过基因转向量技术,将局部的和疾病相关的关键的靶点基因片段转成特征向量,用于基因药物的设计,从而大大加速了基因分析过程。
2. 基因检索应用
2.1 基因检索功能
新冠状病毒的RNA序列可以表达一串核酸序列(又叫碱基序列)。RNA序列一共存在四种核苷酸,用A,C,G和T来表示,分别代表腺嘌呤,胞嘧啶,鸟嘌呤,胸腺嘧啶。每个字母代表一种碱基,他们无间隔的排列在一起。每一个物种的RNA序列是不一样的且有规律的。基因检索系统,可以通过输入一串病毒的基因片段,来查询相似的基因,用来对病毒RNA进行。
为了演示我们的基因片段检索的方法,我们从genbank下载了大量的病毒RNA的片段,和genbank内部的关于病毒的论文以及google scholar中相关病毒的论文导入到AnalyticDB基因检索数据库中。
基因检索的演示界面如图1,用户将冠状病毒的序列(COVID-19)上传到AnalyticDB基因检索工具中来。系统在几个毫秒就可以检索到相似的基因片段(当前系统只返回匹配度超过0.8的基因片段)。我们可以看到,穿山甲携带的冠状病毒(GD/P1L),蝙蝠携带的冠状病毒(RaTG13),以及SARS和MARS病毒被返回出来。其中GD/P1L的序列匹配度最高,有0.974,冠状病毒很可能是通过穿山甲传染到人的身上的。

图1.基因检索界面
众所周知,RNA片段非常相似,说明这两个RNA可能有相似的蛋白质表达和结构。通过基因检索工具,我们可以看到SARS和MARS与冠状病毒的匹配度0.8以上。说明可以将一些SARS或者MARS的研究成果用到新冠状病毒上面来。系统爬取了每种病毒的论文,通过文本分类的算法,将这些论文分成检测类,疫苗类和药物类。
我们点开SARS (如图2),就可以看到SARS检测类有七种方法,疫苗类有四种方法,药物类十种方法。可以看到,其中的对SARS有效的荧光定量PCR检测,现在正在应用于冠状病毒的检测。对于疫苗来说,基因疫苗的方法,以及诱导体内免疫疫苗的方法,也正在如火如荼的展开。对于药物,瑞德西韦,以及相关的干扰素也都用在新型冠状病毒的治疗上面。

图2.相关论文分类
图3展示了点开相关的干扰素的链接,可以看到相关的论文。当前系统调用了自动翻译软件,抽取了中文版的文件名的关键词,作为文件名,方便用户阅读。

图3. 点开干扰素的链接
2.2 应用架构总体设计
阿里云基因检索系统的总体架构如图4所示,AnalyticDB负责整个应用的全部的结构化数据(比方说,基因序列的长度,包含这个基因的论文名称,以及基因的种类,DNA或者RNA等,见图4查询返回结果部分)和基因序列产生的特征向量的存储和查询。在查询的时候,我们使用基因向量抽取模型,将基因转化成向量,在AnalyticDB库中进行粗排检索。在向量匹配的结果集中,我们使用经典的BLAST[7]算法进行精排,返回最相似的基因序列。
其中核心的是基因向量抽取模块包含将核苷酸序列转化成向量。我们目前抽取了各种病毒RNA的全部序列样本来进行训练,因此可以方便的对病毒RNA进行相似度的计算。当然,当前的向量抽取模型可以方便的扩展到其他物种基因上面来。基因向量抽取模型会在第三章进行详细介绍。
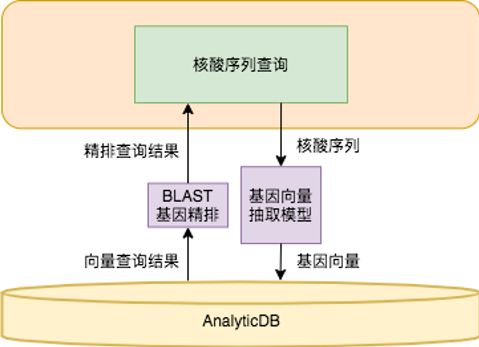
图4. 基因检索框架
3. 关键算法介绍
3.1 基因向量抽取算法
先介绍和基因抽取向量的最相关的词向量算法。
词向量1是一个非常成熟的技术,被广泛应用在机器翻译,阅读理解,语义分析等相关的领域,并取得了巨大的成功。词向量化采用了分布式语义的方法来表示一个词的含义,一个词的含义就是这个词所处的上下文语境。
举个例子,高中英语完形填空题,一篇短文空出10个空,根据空缺词的上下文语境选择合适的词。也就是说上下文语境已经能够准确的表达这个词。给出正确的选词,表明理解了空缺词的意思。因此,通过上下文词的关系,采用词向量算法,每个词可以生成一个向量。通过计算两个词之间向量的相似度,从而得到两个词的相似度。比方说,“勺子”和“碗”相似度很高,因为他们总是出现在吃饭的场景中。
同样的因为基因序列的排列是有一定的规律的,并且每一部分的基因序列所表达的功能和含义是不一样的。因此,我们可以将很长的基因序列划分成小的单元片段(也就是“词”)进行研究。并且这些词也是有上下语境的,因为这些词相互连接相互作用共同完成相对应的功能,形成合理的表达。因此上,生物科学家们8[10]采用词向量的算法对基因序列单元进行向量化。两个基因单元相似度很高,说明这两个基因单元总是在一起,共同来表达完成相应的功能。
总结来说,向量抽取的具体做法主要分成三步:
首先,我们要先解决如何在氨基酸序列中定义出一个一个的词出来,生物信息学中用K-mers[3]来分析氨基酸序列。k-mer是指将核酸序列分成包含k个碱基的字符串,即从一段连续的核酸序列中迭代地选取长度为K个碱基的序列,若核酸序列长度为L,k-mer长度为K,那么可以得到L-K+1个k-mers。如图5所示,假设这里存在某序列长度为12,设定选取的k-mer长度为8,则得到(12-8+1=5)个5-mers。这些k-mer,就是氨基酸序列中的一个一个的“词”。
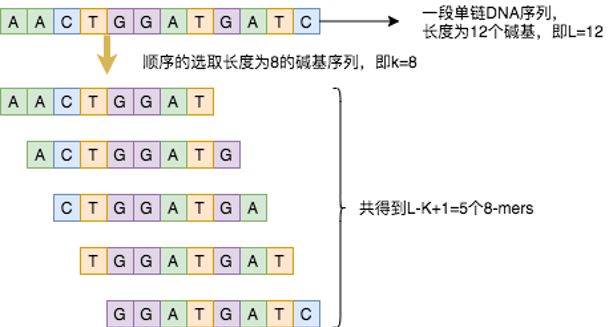
图5. 8-mer核酸序列图
其次,对于词向量算法来说,另一个重要的问题就是上下文的语境。我们会在氨基酸片段中选择一个长度为L的窗口,这个窗口内的氨基酸片段就认为在同一个语境之内。举个例子来说,我们选取了长度为10的窗口(CTGGATGA一段核酸序列),我们将其转换成5个5-mers:{AACTG, ACTGG, CTGGA, GGATG, GATGA}。对于其中的一个5-mer {CTGGA},那么和其相关连的5-mers就是{AACTG, ACTGG, GGATG, GATGA},这四个5-mers就是当前5-mer {CTGGA} 的上下文的语境。我们套用词向量空间的训练模型,对已有的生物的基因的k-mers进行训练,就可以将一个k-mer(基因序列中的一个“词”)转换成1024维的向量。
再次,类似于词向量模型,k-mer向量模型也拥有着和词向量模型相似的数理计算的性质。

公式一表明核苷酸序列ACGAT的向量减去GAT序列的向量和AC的序列的向量的距离是非常近的。
公式二表明核苷酸序列AC的向量加上ATC序列的向量和ACATC的序列的向量的距离也是很近的。因此,根据这些数理特征,当我们要计算一个长的氨基酸序列的向量的时候,我们将这个序列中的每一段的k-mer序列进行累加,最后进行归一化就可以得到整个氨基酸序列的向量。当然,进一步为了提升精度,我们可以将基因片段看做一个文本, 然后使用doc2vec4将整个序列转换成向量进行计算。
为了进一步验证算法的性能,我们计算了常用在基因检索库中的BLAST[6]算法的序列和基因转向量的l2距离序列的相似度,两个序列的斯皮尔曼等级相关系数[7]是0.839。 因此上,将DNA序列转换成向量用于相似基因片段的初筛是有效且可行的。
3.2 AnalyticDB向量版特性介绍
分析型数据库(AnalyticDB)是阿里云上的一种高并发低延时的PB级实时数据仓库,可以毫秒级针对万亿级数据进行即时的多维分析透视和业务探索。
AnalyticDB for MySQL 全面兼容MySQL协议以及SQL:2003 语法标准, AnalyticDB forPostgreSQL 支持标准 SQL:2003,高度兼容 Oracle 语法生态. 目前两款产品都包含向量检索功能, 可以支持图像, 推荐,声纹,核苷酸序列分析等相似性查询。目前AnalyticDB在真实应用场景中可以支持10亿级别的向量数据的查询, 100毫秒级别的响应时间. AnalyticDB已经在多个城市的安防项目中大规模部署。
在一般的包含向量检索的的应用系统中, 通常开发者会使用向量检索引擎(例如Faiss)来存储向量数据, 然后使用关系型数据库存储结构化数据. 在查询时也需要交替查询两个系统, 这种方案会有额外的开发工作并且性能也不是最优。
AnalyticDB支持结构化数据和非结构化数据(向量)的检索,仅仅使用SQL接口就可以快速的搭建起基因检索或者基因+结构化数据混合检索等功能。AnalyticDB的优化器在混合检索场景中会根据数据的分布和查询的条件选择最优的执行计划,在保证召回的同时,得到最优的性能。
RNA核酸序列检索, 可以通过一条SQL实现:
-- 查找RNA和提交的序列向量相近的基因序列。
select title, # 文章名
length, # 基因长度
type, # mRNA或DNA等
l2_distance(feature, array[-0.017,-0.032,...]::real[]) as distance # 向量距离
from demo.paper a, demo.dna_feature b
where a.id = b.id
order by distance; # 用向量相似度排序
其中表demo.paper中存储了上传的各个文章的基本信息,demo.dna_feature存储了各个物种的基因的序列所对应的向量。通过基因转向量模型,将要检索的基因转成向量[-0.017,-0.032,...],在阿里云AnalyticDB数据库中进行检索。
当然,当前系统也支持结构化信息+非结构化信息(核苷酸序列)混合检索。例如我们想查找和冠状病毒相关的类似基因片段。在这种情况下, 使用AnalyticDB我们只需要在SQL中增加 where title like'%COVID-19%' 就可以轻易实现。