Kaggle实战项目学习笔记01:房价预测案例
一些学习前的想法:
自己拿Kaggl上的金价数据做过简单的模型分析,发现SVM的表现效果非常不好,随机森林还行…想要重新把机器学习的部分再学习一遍,再学一学深度学习的部分。


如何确定用什么算法
没有任何的标签的时候,–clustering(无监督)
常用工具 sklearn
只需要造出XY后就可以自动fit
gensim
NumPy
pandas(数据清洗时频繁用到)
XGBoost
学习曲线
过拟合该怎么办?
增大样本量,增加正则化作用
经济金融实战案例

a.分类/回归器
1.Linear/nonLinear
y = α+β*Xi + 残差项
根据order norm 因子选取等等的不同产生各种变种:
LR LASSO…
b.决策树
类似于分治思想:
把数据集分成两组,通过entropy熵和informationGain信息增益来决定从哪个var开始搞分裂
不同数据点被完美区分开了吗?
不是:重复楼上两步
是的:打完收工
优势:
- 非黑盒
- 轻松去除无关attribute(gain = 0)
- test起来很块(O(depth))
量化交易目前还不能轻易使用深度学习(黑盒机制)
劣势:
- 只能线性分割数据
- 贪婪算法(可能找不到最好的树)(树枝中 谁在前谁在后的顺序改变会影响结果很大)
因此决策树是一个弱分类器。
把弱分类器ensemble集成为强分类器。
Bagging:类似于大多数人投票的方式
Random Forest:更加漂亮的bagging方式,多加了一层随机层
Boosting:把第一次学习时学的不好的地方多加一点权重,在下一次继续学习。
ensemble不是算法,只是一个算法框架。


房价预测案例
调用数据来自kaggle: house price 第一位
独热编码
当我们用numerical来表达categorical的时候,要注意,数字本身有大小的含义,所以乱用数字会给之后的模型学习带来麻烦。于是我们可以用one-hot的方法来表达category。
pandas自带的get_dummies方法,可以一键做到one-hot
标准化数据
这一步并不是必要。一般来说,regression分类器最好把源数据放在标准分布里,不要让数据间差距太大。
Ridge Regression
这里用Ridege Regression来跑的(对于多因子的数据集,这种模型可以方便的把所有的var都无脑放进去)
Stacking
把两种或多种模型的优点汲取
把最好的parameter拿出来,做成最终的model
一次正经的Ensemble是把几个model的预测结果作为新的input,再做一次预测,这里简单的直接平均化了。
模型进阶
Bagging
把很多的小分类器放在一起,每个train随机的一部分数据,然后把它们的最终结果综合起来(多数投票制)
Boosting
理论上稍微高级一些,也是揽来一把的分类器。但是把他们线性排列。下一个分类器把上一个分类器分类的不好的地方加上更高的权重,这样下一个分类器就能在这个部分学得更加“深刻”。
XGBoost
外号Kaggle神器。依旧是Boosting框架的模型,但是做了很多改进。
源代码:
import numpy as np
import pandas as pd
train_df = pd.read_csv('C:/documentstransfer/data analysis/house-prices-advanced-regression-techniques/train.csv',index_col=0)
test_df = pd.read_csv('C:/documentstransfer/data analysis/house-prices-advanced-regression-techniques/test.csv',index_col=0)
%matplotlib inline
prices = pd.DataFrame({"price":train_df["SalePrice"], "log(price + 1)":np.log1p(train_df["SalePrice"])})
prices.hist()
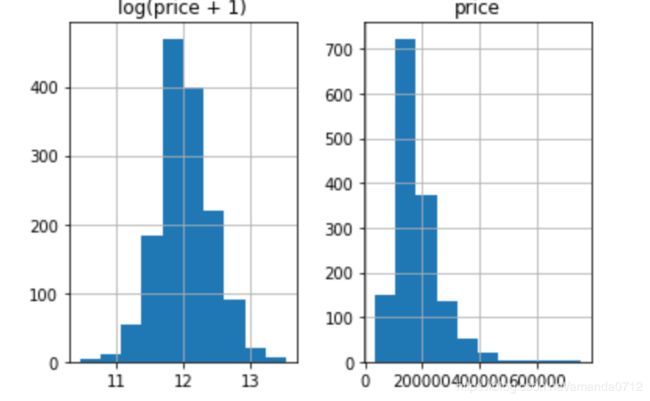
# 机器学习运用到了很多概率上的方法,数据集本身是偏着,所以结果也会偏,因此要对数据做一个标准化,使输出更符合正太分布
# 当然再现实中不能把测试集和训练集放在一起处理数据
# log(+1) 是为了防止出现price = 0的情况
# 最后计算结果时要把预测到的平滑数据变回去
y_train = np.log1p(train_df.pop('SalePrice')
all_df = pd.concat((train_df, test_df),axis=0)
# 变量转化/特征工程
# 读 data描述,其中有一个MSSubClass的特征,虽然用数字表示,但并没有数学意义上的大小关系比较
# 需要把他变成string
all_df['MSSubClass'] = all_df['MSSubClass'].astype(str)
# 一键one-hot
pd.get_dummies(all_df['MSSubClass'],
prefix='MSSubClass').head()
# 一共形成了12个分类的独热编码
# pandas 可以自动读取所有由分类表达的特征
all_dummy_df = pd.get_dummies(all_df)
all_dummy_df.head()
#先打印出来哪些数据缺失
all_dummy_df.isnull().sum().sort_values(ascending = False).head()
# 这里用平均值处理缺失值
mean_cols = all_dummy_df.mean()
all_dummy_df = all_dummy_df.fillna(mean_cols) # 填补空缺值
numeric_cols = all_df.columns[all_df.dtypes != 'object']
# 计算出每个numeric 的平均值和标准差,从而计算方程
numeric_col_means = all_dummy_df.loc[:,numeric_cols].mean()
numeric_col_std = all_dummy_df.loc[:,numeric_cols].std()
all_dummy_df.loc[:,numeric_cols] = (all_dummy_df.loc[:,numeric_cols] - numeric_col_means)/ numeric_col_std
dummy_train_df = all_dummy_df.loc[train_df.index]
dummy_test_df = all_dummy_df.loc[test_df.index]
from sklearn.linear_model import Ridge
from sklearn.model_selection import cross_val_score
# 这一步不是很必要,只是把DF转化成了Numpy Array,这跟sklearn更加配
X_train = dummy_train_df.values
X_test = dummy_test_df.values
# 用交叉验证测试模型选用哪一套
alphas = np.logspace(-3,2,50)
test_scores = []
for alpha in alphas:
clf = Ridge(alpha)
test_score = np.sqrt(-cross_val_score(clf,X_train,y_train,cv=10,scoring='neg_mean_squared_error'))
test_scores.append(np.mean(test_score))
import matplotlib.pyplot as plt
%matplotlib inline
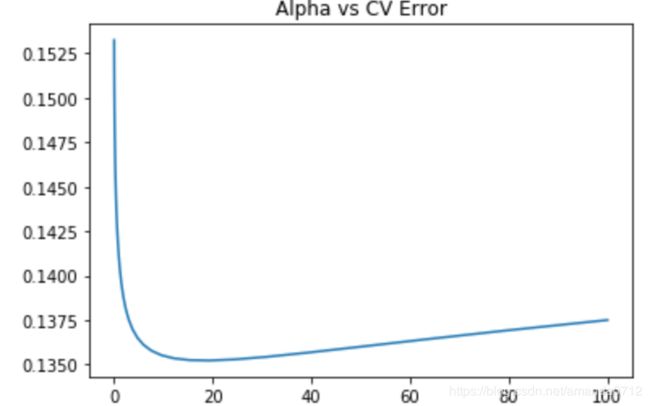
plt.plot(alphas, test_scores)
plt.title("Alpha vs CV Error")
# 可见,大概alpha=10-20时,score接近0.135
from sklearn.ensemble import RandomForestRegressor
max_features = [.1, .3, .5, .7, .9, .99] #从10%--99%
test_scores = []
for max_feat in max_features:
clf = RandomForestRegressor(n_estimators=200, max_features=max_feat)
test_score = np.sqrt(-cross_val_score(clf, X_train, y_train, cv=5, scoring='neg_mean_squared_error'))
test_scores.append(np.mean(test_score))
plt.plot(max_features, test_scores)
plt.title("Max Features vs CV Error")
# 大约再max features = 0.5时达到了最优值 大约为0.137-0.138
ridge = Ridge(alpha=15)
rf = RandomForestRegressor(n_estimators=500,max_features=0.5)
ridge.fit(X_train, y_train)
rf.fit(X_train,y_train)
# 因为最前面给label做了个log(1+x),于是这里需要把predict的值给exp回去,并且减掉那个“1”
# 所以就是我们的expm1()函数
y_ridge = np.expm1(ridge.predict(X_test))
y_rf = np.expm1(rf.predict(X_test))
y_final = (y_ridge + y_rf)/2
# 平均化预测结果
submission_df = pd.DataFrame(data = {'Id': test_df.index, 'SalePrice':y_final})
# 模型进阶
# bagging把很多的小分类器放在一起,每个train随机的一部分数据,然后把他们的最终结果综合起来(多数投票制)
from sklearn.ensemble import BaggingRegressor
from sklearn.model_selection import cross_val_score
# 在刚才的实验中,ridge(alpha=15)是最好的结果
from sklearn.linear_model import Ridge
ridge = Ridge(15)
Jupyter Notebook
房价预测案例(七月kaggle)
(自动保存)
Current Kernel Logo
Python 3
File
Edit
View
Insert
Cell
Kernel
Widgets
Help
import numpy as np
import pandas as pd
train_df = pd.read_csv('C:/documentstransfer/data analysis/house-prices-advanced-regression-techniques/train.csv',index_col=0)
test_df = pd.read_csv('C:/documentstransfer/data analysis/house-prices-advanced-regression-techniques/test.csv',index_col=0)
train_df
MSSubClass MSZoning LotFrontage LotArea Street Alley LotShape LandContour Utilities LotConfig ... PoolArea PoolQC Fence MiscFeature MiscVal MoSold YrSold SaleType SaleCondition SalePrice
Id
1 60 RL 65.0 8450 Pave NaN Reg Lvl AllPub Inside ... 0 NaN NaN NaN 0 2 2008 WD Normal 208500
2 20 RL 80.0 9600 Pave NaN Reg Lvl AllPub FR2 ... 0 NaN NaN NaN 0 5 2007 WD Normal 181500
3 60 RL 68.0 11250 Pave NaN IR1 Lvl AllPub Inside ... 0 NaN NaN NaN 0 9 2008 WD Normal 223500
4 70 RL 60.0 9550 Pave NaN IR1 Lvl AllPub Corner ... 0 NaN NaN NaN 0 2 2006 WD Abnorml 140000
5 60 RL 84.0 14260 Pave NaN IR1 Lvl AllPub FR2 ... 0 NaN NaN NaN 0 12 2008 WD Normal 250000
6 50 RL 85.0 14115 Pave NaN IR1 Lvl AllPub Inside ... 0 NaN MnPrv Shed 700 10 2009 WD Normal 143000
7 20 RL 75.0 10084 Pave NaN Reg Lvl AllPub Inside ... 0 NaN NaN NaN 0 8 2007 WD Normal 307000
8 60 RL NaN 10382 Pave NaN IR1 Lvl AllPub Corner ... 0 NaN NaN Shed 350 11 2009 WD Normal 200000
9 50 RM 51.0 6120 Pave NaN Reg Lvl AllPub Inside ... 0 NaN NaN NaN 0 4 2008 WD Abnorml 129900
10 190 RL 50.0 7420 Pave NaN Reg Lvl AllPub Corner ... 0 NaN NaN NaN 0 1 2008 WD Normal 118000
11 20 RL 70.0 11200 Pave NaN Reg Lvl AllPub Inside ... 0 NaN NaN NaN 0 2 2008 WD Normal 129500
12 60 RL 85.0 11924 Pave NaN IR1 Lvl AllPub Inside ... 0 NaN NaN NaN 0 7 2006 New Partial 345000
13 20 RL NaN 12968 Pave NaN IR2 Lvl AllPub Inside ... 0 NaN NaN NaN 0 9 2008 WD Normal 144000
14 20 RL 91.0 10652 Pave NaN IR1 Lvl AllPub Inside ... 0 NaN NaN NaN 0 8 2007 New Partial 279500
15 20 RL NaN 10920 Pave NaN IR1 Lvl AllPub Corner ... 0 NaN GdWo NaN 0 5 2008 WD Normal 157000
16 45 RM 51.0 6120 Pave NaN Reg Lvl AllPub Corner ... 0 NaN GdPrv NaN 0 7 2007 WD Normal 132000
17 20 RL NaN 11241 Pave NaN IR1 Lvl AllPub CulDSac ... 0 NaN NaN Shed 700 3 2010 WD Normal 149000
18 90 RL 72.0 10791 Pave NaN Reg Lvl AllPub Inside ... 0 NaN NaN Shed 500 10 2006 WD Normal 90000
19 20 RL 66.0 13695 Pave NaN Reg Lvl AllPub Inside ... 0 NaN NaN NaN 0 6 2008 WD Normal 159000
20 20 RL 70.0 7560 Pave NaN Reg Lvl AllPub Inside ... 0 NaN MnPrv NaN 0 5 2009 COD Abnorml 139000
21 60 RL 101.0 14215 Pave NaN IR1 Lvl AllPub Corner ... 0 NaN NaN NaN 0 11 2006 New Partial 325300
22 45 RM 57.0 7449 Pave Grvl Reg Bnk AllPub Inside ... 0 NaN GdPrv NaN 0 6 2007 WD Normal 139400
23 20 RL 75.0 9742 Pave NaN Reg Lvl AllPub Inside ... 0 NaN NaN NaN 0 9 2008 WD Normal 230000
24 120 RM 44.0 4224 Pave NaN Reg Lvl AllPub Inside ... 0 NaN NaN NaN 0 6 2007 WD Normal 129900
25 20 RL NaN 8246 Pave NaN IR1 Lvl AllPub Inside ... 0 NaN MnPrv NaN 0 5 2010 WD Normal 154000
26 20 RL 110.0 14230 Pave NaN Reg Lvl AllPub Corner ... 0 NaN NaN NaN 0 7 2009 WD Normal 256300
27 20 RL 60.0 7200 Pave NaN Reg Lvl AllPub Corner ... 0 NaN NaN NaN 0 5 2010 WD Normal 134800
28 20 RL 98.0 11478 Pave NaN Reg Lvl AllPub Inside ... 0 NaN NaN NaN 0 5 2010 WD Normal 306000
29 20 RL 47.0 16321 Pave NaN IR1 Lvl AllPub CulDSac ... 0 NaN NaN NaN 0 12 2006 WD Normal 207500
30 30 RM 60.0 6324 Pave NaN IR1 Lvl AllPub Inside ... 0 NaN NaN NaN 0 5 2008 WD Normal 68500
... ... ... ... ... ... ... ... ... ... ... ... ... ... ... ... ... ... ... ... ... ...
1431 60 RL 60.0 21930 Pave NaN IR3 Lvl AllPub Inside ... 0 NaN NaN NaN 0 7 2006 WD Normal 192140
1432 120 RL NaN 4928 Pave NaN IR1 Lvl AllPub Inside ... 0 NaN NaN NaN 0 10 2009 WD Normal 143750
1433 30 RL 60.0 10800 Pave Grvl Reg Lvl AllPub Inside ... 0 NaN NaN NaN 0 8 2007 WD Normal 64500
1434 60 RL 93.0 10261 Pave NaN IR1 Lvl AllPub Inside ... 0 NaN NaN NaN 0 5 2008 WD Normal 186500
1435 20 RL 80.0 17400 Pave NaN Reg Low AllPub Inside ... 0 NaN NaN NaN 0 5 2006 WD Normal 160000
1436 20 RL 80.0 8400 Pave NaN Reg Lvl AllPub Inside ... 0 NaN GdPrv NaN 0 7 2008 COD Abnorml 174000
1437 20 RL 60.0 9000 Pave NaN Reg Lvl AllPub FR2 ... 0 NaN GdWo NaN 0 5 2007 WD Normal 120500
1438 20 RL 96.0 12444 Pave NaN Reg Lvl AllPub FR2 ... 0 NaN NaN NaN 0 11 2008 New Partial 394617
1439 20 RM 90.0 7407 Pave NaN Reg Lvl AllPub Inside ... 0 NaN MnPrv NaN 0 4 2010 WD Normal 149700
1440 60 RL 80.0 11584 Pave NaN Reg Lvl AllPub Inside ... 0 NaN NaN NaN 0 11 2007 WD Normal 197000
1441 70 RL 79.0 11526 Pave NaN IR1 Bnk AllPub Inside ... 0 NaN NaN NaN 0 9 2008 WD Normal 191000
1442 120 RM NaN 4426 Pave NaN Reg Lvl AllPub Inside ... 0 NaN NaN NaN 0 5 2008 WD Normal 149300
1443 60 FV 85.0 11003 Pave NaN Reg Lvl AllPub Inside ... 0 NaN NaN NaN 0 4 2009 WD Normal 310000
1444 30 RL NaN 8854 Pave NaN Reg Lvl AllPub Inside ... 0 NaN NaN NaN 0 5 2009 WD Normal 121000
1445 20 RL 63.0 8500 Pave NaN Reg Lvl AllPub FR2 ... 0 NaN NaN NaN 0 11 2007 WD Normal 179600
1446 85 RL 70.0 8400 Pave NaN Reg Lvl AllPub Inside ... 0 NaN NaN NaN 0 5 2007 WD Normal 129000
1447 20 RL NaN 26142 Pave NaN IR1 Lvl AllPub CulDSac ... 0 NaN NaN NaN 0 4 2010 WD Normal 157900
1448 60 RL 80.0 10000 Pave NaN Reg Lvl AllPub Inside ... 0 NaN NaN NaN 0 12 2007 WD Normal 240000
1449 50 RL 70.0 11767 Pave NaN Reg Lvl AllPub Inside ... 0 NaN GdWo NaN 0 5 2007 WD Normal 112000
1450 180 RM 21.0 1533 Pave NaN Reg Lvl AllPub Inside ... 0 NaN NaN NaN 0 8 2006 WD Abnorml 92000
1451 90 RL 60.0 9000 Pave NaN Reg Lvl AllPub FR2 ... 0 NaN NaN NaN 0 9 2009 WD Normal 136000
1452 20 RL 78.0 9262 Pave NaN Reg Lvl AllPub Inside ... 0 NaN NaN NaN 0 5 2009 New Partial 287090
1453 180 RM 35.0 3675 Pave NaN Reg Lvl AllPub Inside ... 0 NaN NaN NaN 0 5 2006 WD Normal 145000
1454 20 RL 90.0 17217 Pave NaN Reg Lvl AllPub Inside ... 0 NaN NaN NaN 0 7 2006 WD Abnorml 84500
1455 20 FV 62.0 7500 Pave Pave Reg Lvl AllPub Inside ... 0 NaN NaN NaN 0 10 2009 WD Normal 185000
1456 60 RL 62.0 7917 Pave NaN Reg Lvl AllPub Inside ... 0 NaN NaN NaN 0 8 2007 WD Normal 175000
1457 20 RL 85.0 13175 Pave NaN Reg Lvl AllPub Inside ... 0 NaN MnPrv NaN 0 2 2010 WD Normal 210000
1458 70 RL 66.0 9042 Pave NaN Reg Lvl AllPub Inside ... 0 NaN GdPrv Shed 2500 5 2010 WD Normal 266500
1459 20 RL 68.0 9717 Pave NaN Reg Lvl AllPub Inside ... 0 NaN NaN NaN 0 4 2010 WD Normal 142125
1460 20 RL 75.0 9937 Pave NaN Reg Lvl AllPub Inside ... 0 NaN NaN NaN 0 6 2008 WD Normal 147500
1460 rows × 80 columns
# 处理数据(共有80个特征)
# 先把traindata,testdata 合并起来。这么做的目的时为了对数据预处理的时候更加方便。预处理完成后再分开
# 训练表多出一行sales price 测试集里没有
%matplotlib inline
prices = pd.DataFrame({"price":train_df["SalePrice"], "log(price + 1)":np.log1p(train_df["SalePrice"])})
prices.hist()
%matplotlib inline
prices = pd.DataFrame({"price":train_df["SalePrice"], "log(price + 1)":np.log1p(train_df["SalePrice"])})
prices.hist()
array([[,
]],
dtype=object)
# 机器学习运用到了很多概率上的方法,数据集本身是偏着,所以结果也会偏,因此要对数据做一个标准化,使输出更符合正太分布
# 当然再现实中不能把测试集和训练集放在一起处理数据
# log(+1) 是为了防止出现price = 0的情况
# 最后计算结果时要把预测到的平滑数据变回去
# 机器学习运用到了很多概率上的方法,数据集本身是偏着,所以结果也会偏,因此要对数据做一个标准化,使输出更符合正太分布
# 当然再现实中不能把测试集和训练集放在一起处理数据
# log(+1) 是为了防止出现price = 0的情况
# 最后计算结果时要把预测到的平滑数据变回去
y_train = np.log1p(train_df.pop('SalePrice'))
y_train = np.log1p(train_df.pop('SalePrice'))
all_df = pd.concat((train_df, test_df),axis=0)
all_df = pd.concat((train_df, test_df),axis=0)
y_train
Id
1 12.247699
2 12.109016
3 12.317171
4 11.849405
5 12.429220
6 11.870607
7 12.634606
8 12.206078
9 11.774528
10 11.678448
11 11.771444
12 12.751303
13 11.877576
14 12.540761
15 11.964007
16 11.790565
17 11.911708
18 11.407576
19 11.976666
20 11.842236
21 12.692506
22 11.845110
23 12.345839
24 11.774528
25 11.944714
26 12.454108
27 11.811555
28 12.631344
29 12.242891
30 11.134604
...
1431 12.165985
1432 11.875838
1433 11.074436
1434 12.136192
1435 11.982935
1436 12.066816
1437 11.699413
1438 12.885673
1439 11.916395
1440 12.190964
1441 12.160034
1442 11.913720
1443 12.644331
1444 11.703554
1445 12.098493
1446 11.767575
1447 11.969724
1448 12.388398
1449 11.626263
1450 11.429555
1451 11.820418
1452 12.567555
1453 11.884496
1454 11.344519
1455 12.128117
1456 12.072547
1457 12.254868
1458 12.493133
1459 11.864469
1460 11.901590
Name: SalePrice, Length: 1460, dtype: float64
all_df
MSSubClass MSZoning LotFrontage LotArea Street Alley LotShape LandContour Utilities LotConfig ... ScreenPorch PoolArea PoolQC Fence MiscFeature MiscVal MoSold YrSold SaleType SaleCondition
Id
1 60 RL 65.0 8450 Pave NaN Reg Lvl AllPub Inside ... 0 0 NaN NaN NaN 0 2 2008 WD Normal
2 20 RL 80.0 9600 Pave NaN Reg Lvl AllPub FR2 ... 0 0 NaN NaN NaN 0 5 2007 WD Normal
3 60 RL 68.0 11250 Pave NaN IR1 Lvl AllPub Inside ... 0 0 NaN NaN NaN 0 9 2008 WD Normal
4 70 RL 60.0 9550 Pave NaN IR1 Lvl AllPub Corner ... 0 0 NaN NaN NaN 0 2 2006 WD Abnorml
5 60 RL 84.0 14260 Pave NaN IR1 Lvl AllPub FR2 ... 0 0 NaN NaN NaN 0 12 2008 WD Normal
6 50 RL 85.0 14115 Pave NaN IR1 Lvl AllPub Inside ... 0 0 NaN MnPrv Shed 700 10 2009 WD Normal
7 20 RL 75.0 10084 Pave NaN Reg Lvl AllPub Inside ... 0 0 NaN NaN NaN 0 8 2007 WD Normal
8 60 RL NaN 10382 Pave NaN IR1 Lvl AllPub Corner ... 0 0 NaN NaN Shed 350 11 2009 WD Normal
9 50 RM 51.0 6120 Pave NaN Reg Lvl AllPub Inside ... 0 0 NaN NaN NaN 0 4 2008 WD Abnorml
10 190 RL 50.0 7420 Pave NaN Reg Lvl AllPub Corner ... 0 0 NaN NaN NaN 0 1 2008 WD Normal
11 20 RL 70.0 11200 Pave NaN Reg Lvl AllPub Inside ... 0 0 NaN NaN NaN 0 2 2008 WD Normal
12 60 RL 85.0 11924 Pave NaN IR1 Lvl AllPub Inside ... 0 0 NaN NaN NaN 0 7 2006 New Partial
13 20 RL NaN 12968 Pave NaN IR2 Lvl AllPub Inside ... 176 0 NaN NaN NaN 0 9 2008 WD Normal
14 20 RL 91.0 10652 Pave NaN IR1 Lvl AllPub Inside ... 0 0 NaN NaN NaN 0 8 2007 New Partial
15 20 RL NaN 10920 Pave NaN IR1 Lvl AllPub Corner ... 0 0 NaN GdWo NaN 0 5 2008 WD Normal
16 45 RM 51.0 6120 Pave NaN Reg Lvl AllPub Corner ... 0 0 NaN GdPrv NaN 0 7 2007 WD Normal
17 20 RL NaN 11241 Pave NaN IR1 Lvl AllPub CulDSac ... 0 0 NaN NaN Shed 700 3 2010 WD Normal
18 90 RL 72.0 10791 Pave NaN Reg Lvl AllPub Inside ... 0 0 NaN NaN Shed 500 10 2006 WD Normal
19 20 RL 66.0 13695 Pave NaN Reg Lvl AllPub Inside ... 0 0 NaN NaN NaN 0 6 2008 WD Normal
20 20 RL 70.0 7560 Pave NaN Reg Lvl AllPub Inside ... 0 0 NaN MnPrv NaN 0 5 2009 COD Abnorml
21 60 RL 101.0 14215 Pave NaN IR1 Lvl AllPub Corner ... 0 0 NaN NaN NaN 0 11 2006 New Partial
22 45 RM 57.0 7449 Pave Grvl Reg Bnk AllPub Inside ... 0 0 NaN GdPrv NaN 0 6 2007 WD Normal
23 20 RL 75.0 9742 Pave NaN Reg Lvl AllPub Inside ... 0 0 NaN NaN NaN 0 9 2008 WD Normal
24 120 RM 44.0 4224 Pave NaN Reg Lvl AllPub Inside ... 0 0 NaN NaN NaN 0 6 2007 WD Normal
25 20 RL NaN 8246 Pave NaN IR1 Lvl AllPub Inside ... 0 0 NaN MnPrv NaN 0 5 2010 WD Normal
26 20 RL 110.0 14230 Pave NaN Reg Lvl AllPub Corner ... 0 0 NaN NaN NaN 0 7 2009 WD Normal
27 20 RL 60.0 7200 Pave NaN Reg Lvl AllPub Corner ... 0 0 NaN NaN NaN 0 5 2010 WD Normal
28 20 RL 98.0 11478 Pave NaN Reg Lvl AllPub Inside ... 0 0 NaN NaN NaN 0 5 2010 WD Normal
29 20 RL 47.0 16321 Pave NaN IR1 Lvl AllPub CulDSac ... 0 0 NaN NaN NaN 0 12 2006 WD Normal
30 30 RM 60.0 6324 Pave NaN IR1 Lvl AllPub Inside ... 0 0 NaN NaN NaN 0 5 2008 WD Normal
... ... ... ... ... ... ... ... ... ... ... ... ... ... ... ... ... ... ... ... ... ...
2890 30 RM 50.0 7030 Pave NaN Reg Lvl AllPub Inside ... 0 0 NaN MnPrv NaN 0 3 2006 WD Normal
2891 50 RM 75.0 9060 Pave NaN Reg Lvl AllPub Inside ... 0 0 NaN NaN NaN 0 4 2006 WD Normal
2892 30 C (all) 69.0 12366 Pave NaN Reg Lvl AllPub Inside ... 0 0 NaN NaN NaN 0 10 2006 WD Abnorml
2893 190 C (all) 50.0 9000 Pave NaN Reg Lvl AllPub Inside ... 0 0 NaN NaN NaN 0 10 2006 WD Abnorml
2894 50 C (all) 60.0 8520 Grvl NaN Reg Bnk AllPub Inside ... 0 0 NaN NaN NaN 0 4 2006 WD Normal
2895 120 RM 41.0 5748 Pave NaN IR1 HLS AllPub Inside ... 153 0 NaN NaN NaN 0 2 2006 New Partial
2896 120 RM 44.0 3842 Pave NaN IR1 HLS AllPub Inside ... 155 0 NaN NaN NaN 0 12 2006 WD Normal
2897 20 RL 69.0 23580 Pave NaN IR1 Lvl AllPub Inside ... 0 0 NaN NaN NaN 0 9 2006 WD Normal
2898 90 RL 65.0 8385 Pave NaN Reg Lvl AllPub Inside ... 0 0 NaN NaN NaN 0 10 2006 WD Normal
2899 20 RL 70.0 9116 Pave NaN Reg Lvl AllPub Corner ... 0 0 NaN NaN NaN 0 5 2006 WD Normal
2900 80 RL 140.0 11080 Pave NaN Reg Lvl AllPub Corner ... 0 0 NaN NaN NaN 0 5 2006 WD Normal
2901 20 RL NaN 50102 Pave NaN IR1 Low AllPub Inside ... 138 0 NaN NaN NaN 0 3 2006 WD Alloca
2902 20 RL NaN 8098 Pave NaN IR1 Lvl AllPub Inside ... 0 0 NaN NaN NaN 0 10 2006 WD Normal
2903 20 RL 95.0 13618 Pave NaN Reg Lvl AllPub Corner ... 0 0 NaN NaN NaN 0 11 2006 New Partial
2904 20 RL 88.0 11577 Pave NaN Reg Lvl AllPub Inside ... 0 0 NaN NaN NaN 0 9 2006 New Partial
2905 20 NaN 125.0 31250 Pave NaN Reg Lvl AllPub Inside ... 0 0 NaN NaN NaN 0 5 2006 WD Normal
2906 90 RM 78.0 7020 Pave NaN Reg Lvl AllPub Inside ... 0 0 NaN NaN NaN 0 11 2006 WD Normal
2907 160 RM 41.0 2665 Pave NaN Reg Lvl AllPub Inside ... 0 0 NaN NaN NaN 0 5 2006 WD Normal
2908 20 RL 58.0 10172 Pave NaN IR1 Lvl AllPub Inside ... 0 0 NaN NaN NaN 0 10 2006 WD Normal
2909 90 RL NaN 11836 Pave NaN IR1 Lvl AllPub Corner ... 0 0 NaN NaN NaN 0 3 2006 WD Normal
2910 180 RM 21.0 1470 Pave NaN Reg Lvl AllPub Inside ... 0 0 NaN NaN NaN 0 4 2006 WD Normal
2911 160 RM 21.0 1484 Pave NaN Reg Lvl AllPub Inside ... 0 0 NaN NaN NaN 0 5 2006 WD Normal
2912 20 RL 80.0 13384 Pave NaN Reg Lvl AllPub Inside ... 0 0 NaN NaN NaN 0 5 2006 WD Normal
2913 160 RM 21.0 1533 Pave NaN Reg Lvl AllPub Inside ... 0 0 NaN NaN NaN 0 12 2006 WD Abnorml
2914 160 RM 21.0 1526 Pave NaN Reg Lvl AllPub Inside ... 0 0 NaN GdPrv NaN 0 6 2006 WD Normal
2915 160 RM 21.0 1936 Pave NaN Reg Lvl AllPub Inside ... 0 0 NaN NaN NaN 0 6 2006 WD Normal
2916 160 RM 21.0 1894 Pave NaN Reg Lvl AllPub Inside ... 0 0 NaN NaN NaN 0 4 2006 WD Abnorml
2917 20 RL 160.0 20000 Pave NaN Reg Lvl AllPub Inside ... 0 0 NaN NaN NaN 0 9 2006 WD Abnorml
2918 85 RL 62.0 10441 Pave NaN Reg Lvl AllPub Inside ... 0 0 NaN MnPrv Shed 700 7 2006 WD Normal
2919 60 RL 74.0 9627 Pave NaN Reg Lvl AllPub Inside ... 0 0 NaN NaN NaN 0 11 2006 WD Normal
2919 rows × 79 columns
all_df.shape
(2919, 79)
y_train.shape
(1460,)
# 变量转化/特征工程
# 读 data描述,其中有一个MSSubClass的特征,虽然用数字表示,但并没有数学意义上的大小关系比较
# 需要把他变成string
# 变量转化/特征工程
# 读 data描述,其中有一个MSSubClass的特征,虽然用数字表示,但并没有数学意义上的大小关系比较
# 需要把他变成string
all_df['MSSubClass'].dtypes #检查一下确实是int类型
dtype('int64')
all_df['MSSubClass'] = all_df['MSSubClass'].astype(str)
all_df['MSSubClass'] = all_df['MSSubClass'].astype(str)
all_df['MSSubClass'].value_counts() #这里显示的int64是指统计的个数是int类型
20 1079
60 575
50 287
120 182
30 139
160 128
70 128
80 118
90 109
190 61
85 48
75 23
45 18
180 17
40 6
150 1
Name: MSSubClass, dtype: int64
all_df['MSSubClass'].dtypes
dtype('O')
# 一键one-hot
pd.get_dummies(all_df['MSSubClass'],
prefix='MSSubClass').head()
# 一共形成了12个分类的独热编码
# 一键one-hot
pd.get_dummies(all_df['MSSubClass'],
prefix='MSSubClass').head()
# 一共形成了12个分类的独热编码
MSSubClass_120 MSSubClass_150 MSSubClass_160 MSSubClass_180 MSSubClass_190 MSSubClass_20 MSSubClass_30 MSSubClass_40 MSSubClass_45 MSSubClass_50 MSSubClass_60 MSSubClass_70 MSSubClass_75 MSSubClass_80 MSSubClass_85 MSSubClass_90
Id
1 0 0 0 0 0 0 0 0 0 0 1 0 0 0 0 0
2 0 0 0 0 0 1 0 0 0 0 0 0 0 0 0 0
3 0 0 0 0 0 0 0 0 0 0 1 0 0 0 0 0
4 0 0 0 0 0 0 0 0 0 0 0 1 0 0 0 0
5 0 0 0 0 0 0 0 0 0 0 1 0 0 0 0 0
# pandas 可以自动读取所有由分类表达的特征
all_dummy_df = pd.get_dummies(all_df)
all_dummy_df.head()
# pandas 可以自动读取所有由分类表达的特征
all_dummy_df = pd.get_dummies(all_df)
all_dummy_df.head()
LotFrontage LotArea OverallQual OverallCond YearBuilt YearRemodAdd MasVnrArea BsmtFinSF1 BsmtFinSF2 BsmtUnfSF ... SaleType_ConLw SaleType_New SaleType_Oth SaleType_WD SaleCondition_Abnorml SaleCondition_AdjLand SaleCondition_Alloca SaleCondition_Family SaleCondition_Normal SaleCondition_Partial
Id
1 65.0 8450 7 5 2003 2003 196.0 706.0 0.0 150.0 ... 0 0 0 1 0 0 0 0 1 0
2 80.0 9600 6 8 1976 1976 0.0 978.0 0.0 284.0 ... 0 0 0 1 0 0 0 0 1 0
3 68.0 11250 7 5 2001 2002 162.0 486.0 0.0 434.0 ... 0 0 0 1 0 0 0 0 1 0
4 60.0 9550 7 5 1915 1970 0.0 216.0 0.0 540.0 ... 0 0 0 1 1 0 0 0 0 0
5 84.0 14260 8 5 2000 2000 350.0 655.0 0.0 490.0 ... 0 0 0 1 0 0 0 0 1 0
5 rows × 303 columns
# 处理好numerical变量
# 有一些数据是缺失的
#先打印出来哪些数据缺失
all_dummy_df.isnull().sum().sort_values(ascending = False).head()
#先打印出来哪些数据缺失
all_dummy_df.isnull().sum().sort_values(ascending = False).head()
LotFrontage 486
GarageYrBlt 159
MasVnrArea 23
BsmtHalfBath 2
BsmtFullBath 2
dtype: int64
# 这里用平均值处理缺失值
# 这里用平均值处理缺失值
mean_cols = all_dummy_df.mean() #
mean_cols = all_dummy_df.mean() #
mean_cols.head(10)
LotFrontage 69.305795
LotArea 10168.114080
OverallQual 6.089072
OverallCond 5.564577
YearBuilt 1971.312778
YearRemodAdd 1984.264474
MasVnrArea 102.201312
BsmtFinSF1 441.423235
BsmtFinSF2 49.582248
BsmtUnfSF 560.772104
dtype: float64
all_dummy_df = all_dummy_df.fillna(mean_cols) # 填补空缺值
all_dummy_df = all_dummy_df.fillna(mean_cols) # 填补空缺值
all_dummy_df.isnull().sum().sum()
0
numeric_cols = all_df.columns[all_df.dtypes != 'object']
numeric_cols = all_df.columns[all_df.dtypes != 'object']
numeric_cols
Index(['LotFrontage', 'LotArea', 'OverallQual', 'OverallCond', 'YearBuilt',
'YearRemodAdd', 'MasVnrArea', 'BsmtFinSF1', 'BsmtFinSF2', 'BsmtUnfSF',
'TotalBsmtSF', '1stFlrSF', '2ndFlrSF', 'LowQualFinSF', 'GrLivArea',
'BsmtFullBath', 'BsmtHalfBath', 'FullBath', 'HalfBath', 'BedroomAbvGr',
'KitchenAbvGr', 'TotRmsAbvGrd', 'Fireplaces', 'GarageYrBlt',
'GarageCars', 'GarageArea', 'WoodDeckSF', 'OpenPorchSF',
'EnclosedPorch', '3SsnPorch', 'ScreenPorch', 'PoolArea', 'MiscVal',
'MoSold', 'YrSold'],
dtype='object')
# 计算出每个numeric 的平均值和标准差,从而计算方程
# 计算出每个numeric 的平均值和标准差,从而计算方程
numeric_col_means = all_dummy_df.loc[:,numeric_cols].mean()
numeric_col_std = all_dummy_df.loc[:,numeric_cols].std()
all_dummy_df.loc[:,numeric_cols] = (all_dummy_df.loc[:,numeric_cols] - numeric_col_means)/ numeric_col_std
numeric_col_means = all_dummy_df.loc[:,numeric_cols].mean()
numeric_col_std = all_dummy_df.loc[:,numeric_cols].std()
all_dummy_df.loc[:,numeric_cols] = (all_dummy_df.loc[:,numeric_cols] - numeric_col_means)/ numeric_col_std
dummy_train_df = all_dummy_df.loc[train_df.index]
dummy_test_df = all_dummy_df.loc[test_df.index]
dummy_train_df = all_dummy_df.loc[train_df.index]
dummy_test_df = all_dummy_df.loc[test_df.index]
dummy_train_df.shape, dummy_test_df.shape
((1460, 303), (1459, 303))
from sklearn.linear_model import Ridge
from sklearn.model_selection import cross_val_score
from sklearn.linear_model import Ridge
from sklearn.model_selection import cross_val_score
# 这一步不是很必要,只是把DF转化成了Numpy Array,这跟sklearn更加配
X_train = dummy_train_df.values
X_test = dummy_test_df.values
# 这一步不是很必要,只是把DF转化成了Numpy Array,这跟sklearn更加配
X_train = dummy_train_df.values
X_test = dummy_test_df.values
X_train
array([[-0.20203292, -0.21784137, 0.6460727 , ..., 0. ,
1. , 0. ],
[ 0.5017845 , -0.07203174, -0.06317371, ..., 0. ,
1. , 0. ],
[-0.06126943, 0.13717338, 0.6460727 , ..., 0. ,
1. , 0. ],
...,
[-0.15511176, -0.14278111, 0.6460727 , ..., 0. ,
1. , 0. ],
[-0.06126943, -0.0571972 , -0.77242013, ..., 0. ,
1. , 0. ],
[ 0.2671787 , -0.02930318, -0.77242013, ..., 0. ,
1. , 0. ]])
X_test
array([[ 0.5017845 , 0.18433962, -0.77242013, ..., 0. ,
1. , 0. ],
[ 0.54870567, 0.51970176, -0.06317371, ..., 0. ,
1. , 0. ],
[ 0.22025754, 0.46429411, -0.77242013, ..., 0. ,
1. , 0. ],
...,
[ 4.25547741, 1.24659445, -0.77242013, ..., 0. ,
0. , 0. ],
[-0.3427964 , 0.03459947, -0.77242013, ..., 0. ,
1. , 0. ],
[ 0.22025754, -0.06860838, 0.6460727 , ..., 0. ,
1. , 0. ]])
# 用交叉验证测试模型选用哪一套
alphas = np.logspace(-3,2,50)
test_scores = []
for alpha in alphas:
clf = Ridge(alpha)
test_score = np.sqrt(-cross_val_score(clf,X_train,y_train,cv=10,scoring='neg_mean_squared_error'))
test_scores.append(np.mean(test_score))
# 用交叉验证测试模型选用哪一套
alphas = np.logspace(-3,2,50)
test_scores = []
for alpha in alphas:
clf = Ridge(alpha)
test_score = np.sqrt(-cross_val_score(clf,X_train,y_train,cv=10,scoring='neg_mean_squared_error'))
test_scores.append(np.mean(test_score))
alphas = np.logspace(-3,2,50)
alphas
array([1.00000000e-03, 1.26485522e-03, 1.59985872e-03, 2.02358965e-03,
2.55954792e-03, 3.23745754e-03, 4.09491506e-03, 5.17947468e-03,
6.55128557e-03, 8.28642773e-03, 1.04811313e-02, 1.32571137e-02,
1.67683294e-02, 2.12095089e-02, 2.68269580e-02, 3.39322177e-02,
4.29193426e-02, 5.42867544e-02, 6.86648845e-02, 8.68511374e-02,
1.09854114e-01, 1.38949549e-01, 1.75751062e-01, 2.22299648e-01,
2.81176870e-01, 3.55648031e-01, 4.49843267e-01, 5.68986603e-01,
7.19685673e-01, 9.10298178e-01, 1.15139540e+00, 1.45634848e+00,
1.84206997e+00, 2.32995181e+00, 2.94705170e+00, 3.72759372e+00,
4.71486636e+00, 5.96362332e+00, 7.54312006e+00, 9.54095476e+00,
1.20679264e+01, 1.52641797e+01, 1.93069773e+01, 2.44205309e+01,
3.08884360e+01, 3.90693994e+01, 4.94171336e+01, 6.25055193e+01,
7.90604321e+01, 1.00000000e+02])
import matplotlib.pyplot as plt
%matplotlib inline
plt.plot(alphas, test_scores)
plt.title("Alpha vs CV Error")
# 可见,大概alpha=10-20时,score接近0.135
import matplotlib.pyplot as plt
%matplotlib inline
plt.plot(alphas, test_scores)
plt.title("Alpha vs CV Error")
# 可见,大概alpha=10-20时,score接近0.135
from sklearn.ensemble import RandomForestRegressor
from sklearn.ensemble import RandomForestRegressor
max_features = [.1, .3, .5, .7, .9, .99] #从10%--99%
test_scores = []
for max_feat in max_features:
clf = RandomForestRegressor(n_estimators=200, max_features=max_feat)
test_score = np.sqrt(-cross_val_score(clf, X_train, y_train, cv=5, scoring='neg_mean_squared_error'))
test_scores.append(np.mean(test_score))
max_features = [.1, .3, .5, .7, .9, .99] #从10%--99%
test_scores = []
for max_feat in max_features:
clf = RandomForestRegressor(n_estimators=200, max_features=max_feat)
test_score = np.sqrt(-cross_val_score(clf, X_train, y_train, cv=5, scoring='neg_mean_squared_error'))
test_scores.append(np.mean(test_score))
plt.plot(max_features, test_scores)
plt.title("Max Features vs CV Error")
# 大约再max features = 0.5时达到了最优值 大约为0.137-0.138
plt.plot(max_features, test_scores)
plt.title("Max Features vs CV Error")
# 大约再max features = 0.5时达到了最优值 大约为0.137-0.138
Text(0.5, 1.0, 'Max Features vs CV Error')
ridge = Ridge(alpha=15)
rf = RandomForestRegressor(n_estimators=500,max_features=0.5)
ridge = Ridge(alpha=15)
rf = RandomForestRegressor(n_estimators=500,max_features=0.5)
ridge.fit(X_train, y_train)
rf.fit(X_train,y_train)
ridge.fit(X_train, y_train)
rf.fit(X_train,y_train)
RandomForestRegressor(bootstrap=True, criterion='mse', max_depth=None,
max_features=0.5, max_leaf_nodes=None,
min_impurity_decrease=0.0, min_impurity_split=None,
min_samples_leaf=1, min_samples_split=2,
min_weight_fraction_leaf=0.0, n_estimators=500,
n_jobs=None, oob_score=False, random_state=None,
verbose=0, warm_start=False)
# 因为最前面给label做了个log(1+x),于是这里需要把predict的值给exp回去,并且减掉那个“1”
# 所以就是我们的expm1()函数
y_ridge = np.expm1(ridge.predict(X_test))
y_rf = np.expm1(rf.predict(X_test))
# 因为最前面给label做了个log(1+x),于是这里需要把predict的值给exp回去,并且减掉那个“1”
# 所以就是我们的expm1()函数
y_ridge = np.expm1(ridge.predict(X_test))
y_rf = np.expm1(rf.predict(X_test))
y_final = (y_ridge + y_rf)/2
# 平均化预测结果
y_final = (y_ridge + y_rf)/2
# 平均化预测结果
---------------------------------------------------------------------------
NameError Traceback (most recent call last)
in
----> 1 y_final = (y_ridge + y_rf)/2
2 # 平均化预测结果
NameError: name 'y_ridge' is not defined
submission_df = pd.DataFrame(data = {'Id': test_df.index, 'SalePrice':y_final})
submission_df = pd.DataFrame(data = {'Id': test_df.index, 'SalePrice':y_final})
submission_df.head(10)
Id SalePrice
0 1461 120096.722931
1 1462 151145.918506
2 1463 173974.126235
3 1464 189173.021195
4 1465 195993.105095
5 1466 175762.380591
6 1467 177456.363959
7 1468 168769.622578
8 1469 185584.091288
9 1470 123031.041244
# 模型进阶
# bagging把很多的小分类器放在一起,每个train随机的一部分数据,然后把他们的最终结果综合起来(多数投票制)
# 模型进阶
# bagging把很多的小分类器放在一起,每个train随机的一部分数据,然后把他们的最终结果综合起来(多数投票制)
from sklearn.ensemble import BaggingRegressor
from sklearn.model_selection import cross_val_score
from sklearn.ensemble import BaggingRegressor
from sklearn.model_selection import cross_val_score
# 在刚才的实验中,ridge(alpha=15)是最好的结果
from sklearn.linear_model import Ridge
ridge = Ridge(15)
params = [1, 10, 15, 20, 25, 30, 40]
test_scores = []
for param in params:
clf = BaggingRegressor(n_estimators=param,
base_estimator=ridge)
test_score = np.sqrt(-cross_val_score(clf, X_train,y_train, cv=10, scoring='neg_mean_squared_error'))
test_scores.append(np.mean(test_score))
import matplotlib.pyplot as plt
%matplotlib inline
plt.plot(params, test_scores)
plt.title("n_estimator vs CV Error")
# 如果没有提前测试过ridge模型,可以用Bagging自带的Decision Tree模型。
# 代码一样的,把base_estimator删去即可
params = [10,15,20,25,30,40,50,60,70,100]
test_scores = []
for param in params:
clf = BaggingRegressor(n_estimators=param)
test_score = np.sqrt(-cross_val_score(clf,X_train,y_train,cv=10,scoring='neg_mean_squared_error'))
test_scores.append(np.mean(test_score))
plt.plot(params,test_scores)
plt.title("n_estimator vs CV Error")
# 结果显示单纯用DT效果不好,最好也就0.140
from sklearn.ensemble import AdaBoostRegressor
params = [10, 15, 20, 25, 30, 35, 40, 45, 50]
test_scores=[]
for param in params:
clf = BaggingRegressor(n_estimators=param,
base_estimator=ridge)
test_score = np.sqrt(-cross_val_score(clf,X_train,y_train,cv=10,scoring='neg_mean_squared_error'))
test_scores.append(np.mean(test_score))
plt.plot(params, test_scores)
plt.title("n_estimator vs CV Error in Boosting")
# 学习曲线不稳定,所以需要更多的参数调一遍,得到更稳定的学习曲线,cv= 可以调小一点,尽量得到U型曲线,取谷底。
# 结果也是在 25个小分类器的情况下 得到结果0.133
# 也可以不必输入base_estimator,使用adaboost自带的DT。
# XGBoost
from xgboost import XGBRegressor
params = [1,2,3,4,5,6]
test_scores = []
for param in params:
clf = XGBRegressor(max_depth=param)
test_score = np.sqrt(-cross_val_score(clf,X_train,y_train,cv=10,scoring='neg_mean_squared_error'))
test_scores.append(np.mean(test_score))
plt.plot(params, test_scores)
plt.title("max_depth vs CV Error")
# 深度为5的时候,错误率非常小
