深入理解词向量-词向量的可视化
1、概述
词向量是自然语言分词在词空间中的表示,词之间的距离代表了分词之间的相似性,我们可以使用gensim,tensorflow等框架非常方便的来实现词向量。但词向量在词空间的分布到底是什么样的,如何更好的理解词向量是一个非常重要的问题。本文将使用tensorbord以及相关的降维技术在三维空间中模拟词向量在高维空间的分布。
2、训练词向量
词向量的训练是一个无监督的学习过程,这并不是本文讨论的重点。这里只是简单描述一下基本理论。词的表述有两种基本方法:
- one-hot表示方法
- 词向量表示方法
One hot 用来表示词向量非常简单,但是却有很多问题。1、任意两个词之间都是孤立的,根本无法表示出在语义层面上词语词之间的相关信息,而这一点是致命的。2、我们的词汇表一般都非常大,比如达到百万级别,这样每个词都用百万维的向量来表示简直是内存的灾难。能不能把词向量的维度变小呢?
Dristributed representation可以解决One hot representation的问题,它的思路是通过训练,将每个词都映射到一个较短的词向量上来。所有的这些词向量就构成了向量空间,进而可以用普通的统计学的方法来研究词与词之间的关系。这个较短的词向量维度是多大呢?这个一般需要我们在训练时自己来指定。
词的分布式表示主要可以分为三类:基于矩阵的分布表示、基于聚类的分布表示和基于神经网络的分布表示
词向量的训练有两种方法:
- cbow
- skip-gram
2.1 cbow模型
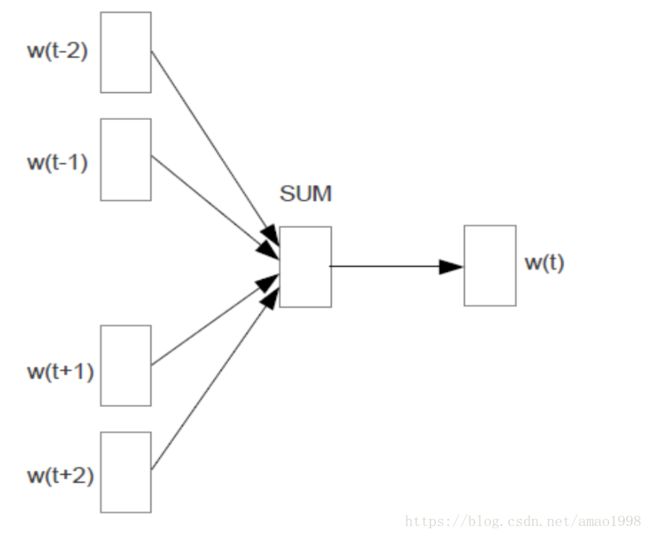
CBOW(Continuous Bag-of-Word Model)又称连续词袋模型,是一个三层神经网络。如下图所示,该模型的特点是输入已知上下文,输出对当前单词的预测。
2.1 skip-gram模型
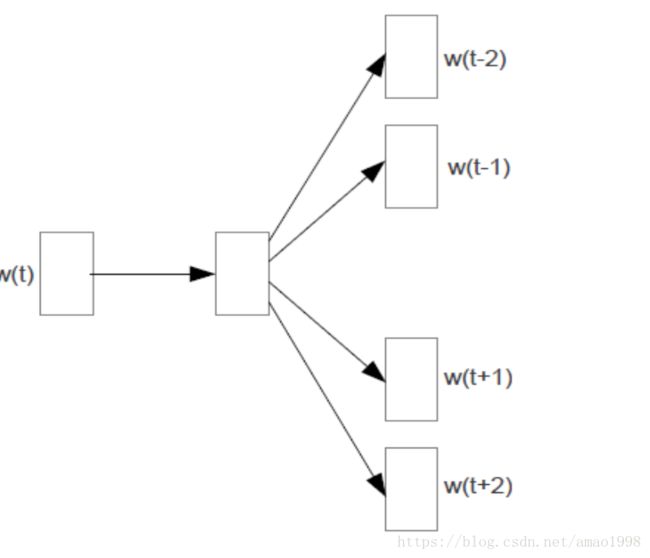
Skip-gram只是逆转了CBOW的因果关系而已,即已知当前词语,预测上下文。
3、词向量的可视化
这里我们使用一组已经训练好的词向量,直接在三维空间中进行可视化操作。主要使用到的语料是北师大训练好的一个300维的语料库,如下图所示:
可以使用此链接下载相关语料:https://github.com/embedding/chinese-word-vectors
3.1 语料结构
这是一个非常庞大的语料,由于语料已经丢失了上下文环境,所以无法进行迁移学习。下面主要分析语料的主要结构,以便于后续读取相关数据。这个语料大小接近3.5G,如下图所示:

语料的基本结构如下:

语料的第一行说明了整个语料包含的单词数量,以及每个单词表示的维度。在这里每一个单词都是由一个300为的向量来表示的。一共有1292607个单词。从第二行开始每一行代表一个单词,用空格隔开,上图中第二行代表单词“,”,后边是他的向量表示。整个语料的整体结构就是这样。这是一个标准的词向量表示文本,可以使用gensim等第三方类库直接读取,但由于本文的目的是为了充分理解词向量所以后面会采用,手动读取词向量的方式来处理语料。
3.2 读取语料
这里采用传统的读取文件的形式读取语料,为了降低计算机处理的数据量,这里我们只读取2000个单词,而不是整个语料。具体代码如下所示:
from tqdm import tqdm # progression bars
import numpy as np
with open('sgns.merge.word','r') as f:
header = f.readline()
vocab_size, vector_size = map(int, header.split())
words, embeddings = [], []
for line in tqdm(range(2000)):
word_list = f.readline().split(' ')
word = word_list[0]
vector = word_list[1:-1]
words.append(word)
embeddings.append(np.array(vector))
print(words[9:10])
print(embeddings[9:10])输出结果如下图所示:

3.3 为tensorboard生成数据
下面将这些变量保存到到tensorflow的variable中并保存模型,请参照下面代码:
import tensorflow as tf
from tensorflow.contrib.tensorboard.plugins import projector
import os
log_path = 'logs'
with tf.Session() as sess:
# tf.assign():这里是一个将具体数值(即,词向量矩阵)赋值给tf Variable的例子:
X = tf.Variable([0.0], name='embedding')
place = tf.placeholder(tf.float32, shape=[len(words), vector_size])
set_x = tf.assign(X, place, validate_shape=False)
sess.run(tf.global_variables_initializer())
sess.run(set_x, feed_dict={place: embeddings})
# 需要保存一个metadata文件,给词典里每一个词分配一个身份
with open(log_path + '/metadata.tsv', 'w') as f:
for word in tqdm(words):
f.write(word + '\n')
# 写 TensorFlow summary
summary_writer = tf.summary.FileWriter(log_path, sess.graph)
config = projector.ProjectorConfig()
embedding_conf = config.embeddings.add()
embedding_conf.tensor_name = 'embedding:0'
embedding_conf.metadata_path = os.path.join(log_path, 'metadata.tsv')
projector.visualize_embeddings(summary_writer, config)
# 保存模型
# word2vec参数的单词和词向量部分分别保存到了metadata和ckpt文件里面
saver = tf.train.Saver()
saver.save(sess, os.path.join(log_path, "model.ckpt"))生成文件如下图所示:

3.4 使用tensorboard观察数据
使用下面命令开启tensorboard,观察效果