稀疏LSTM硬件结构
本文介绍稀疏LSTM的硬件架构,一种是细粒度稀疏化,权重参数分布随机,另外一种是bank-balance稀疏化。
1. 文章结构
Long-short term memory,简称LSTM,被广泛的应用于语音识别、机器翻译、手写识别等。LSTM涉及到大量的矩阵乘法和向量乘法运算,会消耗大量的FPGA计算资源和带宽。为了实现硬件加速,提出了稀疏LSTM。核心是通过剪枝算法去除影响较小的权重,不断迭代训练以达到目标函数收敛。参与实际运算的权重数量大大缩减,这可以有效降低FPGA计算资源和缓解带宽以及存储。本博文结构如下:
1) Fine-grained稀疏压缩的硬件架构。权重稀疏化后,数据被大大压缩,但是也增加了有效数据分布不规律性,这些增加了硬件实现复杂性。
2) Bank-balanced稀疏化方法以及硬件架构。为了能够提高权重数据规律性,提出了bank-balanced稀疏化方式。
2. fine-grained稀疏化
首先要讲的是细粒度压缩架构。当对一个已经训练好的网络进行剪枝后,你会发现权重分布会变得十分随机。这不利于硬件加速的实现,因为FPGA更喜欢整齐划一的结构,这样便于并行化处理。比如对于下边左图,每一行有效权重数据个数不同,而我们在硬件中按照行(这是最容易的并行化方式)并行运算的时候,每一行计算的时间就不会相等,用时少的会等待用时长的,最终用时长的决定了计算的总时间。这样就产生了计算间歇,降低了计算利用率。左图的计算效率就只有60%((5+2+4+1)/20=60%)。
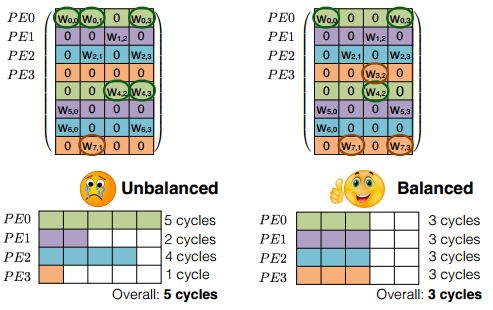
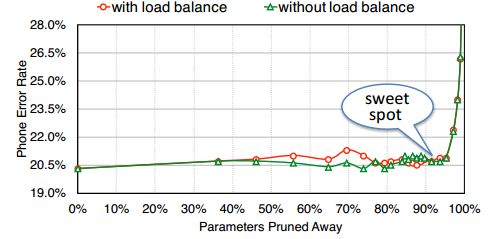
为了提升计算效率,降低等待时间,最理想情况是每行的有效权重数据相同,这样就不需要进行等待了。如右图,仅仅每行计算都需要三个时钟周期。计算效率100%。在进行训练的时候,就需要添加约束条件使得每行具有相同的有效权重数。从结果看出,这样处理在能够加速硬件的同时,还可以保持不变的精度。
模型数据训练是基于浮点数的,浮点运算非常消耗硬件资源,最好的办法就是进行量化,即将浮点转化为定点。量化基本观点就是将相互接近的数用一个数来表示,可以看做是一种聚类。假设参数集W,将其分成h类C。使用k-means聚类,就是最小化:

量化之后不仅减小了权重数据量,这对FPGA上缓存需求以及带宽都能有效缓解,而且还会降低浮点运算带来的巨大逻辑资源消耗。
LSTM中包含了矩阵乘向量,矩阵点乘等操作。进行了剪枝和量化后的权重数据大大减少,为了只传递有效权重,需要对权重数据进行稀疏编码。论文中采用这样的方式:一个有效数据外加两个指数,用于标识数据所在矩阵中的位置。一个指数是相对行号,相对行号表示下一个数据相对于前一个数据的行号距离。另外一个是列号,表示数据所在列坐标。这样在FPGA中就可以根据这两个指数回复权重的位置,并且取出向量中对应的数据。可以在矩阵行的基础上进行并行化设计,比如设计N个并行乘法阵列,每个阵列有3个乘法器,乘法器之间可以进行累加。假设矩阵每行3个有效数据,这样每个阵列就可以进行3次并行乘法运算,并能前向累加。

再来看整体架构,FPGA进行矩阵乘法,矩阵点乘,激活等加速操作,CPU进行指令、权重、输入数据调度。CPU通过PCIE和FPGA进行通信,将权重、指令、输入等数据发送到FPGA端,并且接收来自FPGA的处理结果。由于权重等数据很大,所以FPGA板卡上也配备了自己的DDR,用于存储这些数据。并且在FPGA芯片中也需要一定缓存用于存储权重数据(这部分数据很大,最好是片上可以放得下)、临时数据、结果等。通常都是FPGA计算量很大,而FPGA和DDR的带宽受到限制,所以一个有较大片上存储资源的FPGA更有利于深度学习的加速。
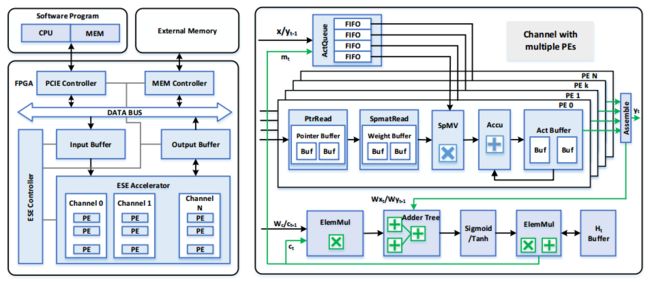
FPGA上的结构主要有:和CPU通信的PCIE控制,读写DDR的控制接口,输入输出缓存,加速计算单元,指令控制和调度。其中加速单元是核心模块,其中包括了稀疏矩阵乘法,累加,激活函数等操作模块。
稀疏矩阵乘法和点乘操作是最耗费计算资源和数据资源的,为了提高计算效率。论文中根据数据之间依赖关系建立了整个控制流程。设计的目标是尽量提高并行化,减少等待时间,使得计算和加载数据时间可以重叠。比如![]() 是相互独立的,就可以同时计算。而有些虽然相互独立,但是存储相互冲突,就只能顺序计算。比如
是相互独立的,就可以同时计算。而有些虽然相互独立,但是存储相互冲突,就只能顺序计算。比如![]()
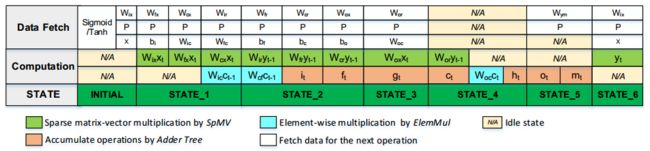
即使经过了剪枝和量化,权重参数也很多,片上有限的资源远远承受不了,所以这些数据都存放在DDR中。在需要的时候加载到片上,如果能够做好流水以及有较大带宽,是能够有较高计算效率的。
Activation vector queue:ActQueue包含很多FIFO,每个FIFO存储了向量数据,每个ActQueue被同一个通道的PE共享。每个FIFO对应一个PE。ActQueue用于提供给各个PE用的数据,这些数据在向量中并不是对齐的。如果某一行中有效权重数据少,那么其就需要等待其他PE完成。
3. bank-balance架构
提出bank-balanced结构是为了解决fine-grained结构中数据随机不对齐的问题。将权重矩阵每行分割成bank单元,让每个单元中的有效权重数据数量相等。对比fine-grained和coarse-grained稀疏化,fine-grained可以将参数压缩的很高,但是导致权重分布不均匀,而coarse-grained能够获得均匀的权重结构,但是精度下降很大。Bank-balanced结构既有分布均匀的权重,同时又能够保持精度。

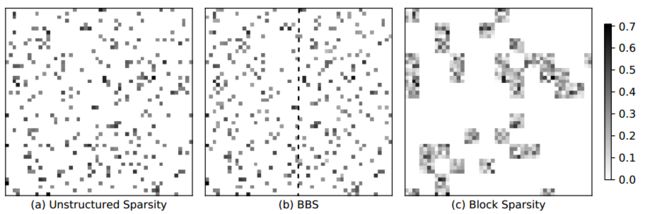
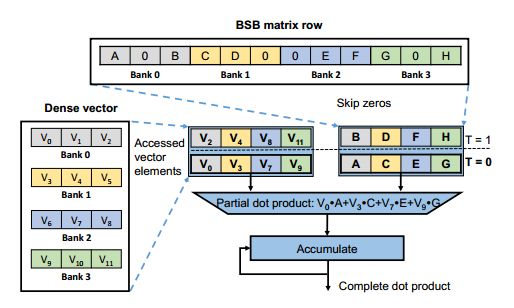
BBS结构有利于硬件加速,以为不仅仅可以增加行间并行度,还可以按照每行相同的bank数进行bank并行计算。而且每个bank数据量相同,那么计算的时候可以同时进行,没有等待时间。比如我们有一个矩阵按行分为4个bank,那么对应的向量也分成4个bank,bank间是并行计算的。Bank内会依次次取出有效的权重和对应的向量,进行乘法之后再累加。这种方式可以避免无规则的计算以及访问存储。
稀疏化后的矩阵是需要经过编码的,这样才能确定其在矩阵中位置。编码方式比较流行的有CSR,COO以及CSC等。但是他们一般都是用两个指数(比如行号和列号)来表示数据位置,这会额外增加数据负重。本论文中针对BBS结构设计了一种灵活简洁的编码:CBS。其由两行组成。第一行将数据重新排列,取出每个bank中第一个非零数据一次排列,然后再取出第二个bank中非零数据。第二行由数据所在的bank内位置决定。这个位置指标可以用于后边取得向量数据的bram地址。

整个硬件架构如下图:主要包括PCIE控制,DDR控制接口,指令控制,PE阵列,矩阵存储,向量存储,之后的点乘和累加等。再介绍一下指令类型:
1) load/store: 这两个指令用于从DDR中加载数据到片上或者从片上存储数据到DDR中。
2) computational指令:根据LSTM的运算模式分成了两种,一个是spMx指令,用于计算矩阵乘法,另外一个是EWOP,这个用于点乘,累加,三种激活。

4. 总结
总结一下,这篇文章我们主要介绍了针对LSTM实现硬件加速的方式:稀疏化。稀疏化会大大降低权重参数,降低计算量以及存储空间。同时比较了两种稀疏化方式(fine-grained和bank-balanced)的不同。介绍了LSTM硬件实现的基本架构和指令集。

1. Cao, S., et al., Efficient and Effective Sparse LSTM on FPGA with Bank-Balanced Sparsity, in Proceedings of the 2019 ACM/SIGDA International Symposium on Field-Programmable Gate Arrays - FPGA '19. 2019. p. 63-72.
2. Huizi Mao, S.H., Jeff Pool, Wenshuo Li, Xingyu Liu, Yu Wang, William J. Dally, Exploringthe Regularity of Sparse Structurein Convolutional Neural Networks. NIPS, 2017.
3. Song Han , J.K., Huizi Mao, Yiming Hu, Xin Li, Yubin Li, Dongliang Xie, Hong Luo, Song Yao, Yu Wang, Huazhong Yang and William J. Dally, ESE: Efficient Speech Recognition Engine with Sparse LSTM on FPGA, in Proceedings of the 2017 ACM/SIGDA International Symposium on Field-Programmable Gate Arrays - FPGA. 2017. p. 75-84.

