遥感数据集
1. UC Merced Land-Use Data Set
图像像素大小为256*256,总包含21类场景图像,每一类有100张,共2100张。
http://weegee.vision.ucmerced.edu/datasets/landuse.html
2. WHU-RS19 Data Set
图像像素大小为600*600,总包含19类场景图像,每一类大概50张,共1005张。
https://download.csdn.net/download/u010656161/10153410
3. SIRI-WHU Data Set
图像像素大小为200*200,总包含12类场景图像,每一类有200张,共2400张。 4. RSSCN7 Data Set 图像像素大小为400*400,总包含7类场景图像,每一类有400张,共2800张。 5. RSC11 Data Set 图像像素大小为512*512,总包含11类场景图像,每一类大概100张,共1232张。 6. NWPU-RESISC45 Data Set http://www.escience.cn/people/JunweiHan/NWPU-RESISC45.html 7. Road and Building Detection Data Set https://www.cs.toronto.edu/~vmnih/data/ 8. DOTA: A Large-scale Dataset for Object Detection in Aerial Images http://captain.whu.edu.cn/DOTAweb/index.html 9. DeepGlobe卫星图像地表解析(道路提取、建筑物检测、地标分类)挑战赛 http://deepglobe.org/challenge.html
CVPR 2018挑战赛
网址:http://deepglobe.org/leaderboard.html
基于深度学习的影像地图道路提取
网络结构:D-LinkNet - LinkNet with Pretrained Encoder and Dilated Convolution for HighResolution Satellite Imagery Road Extraction
与Linknet的区别:增加了下图中的B部分,即扩张卷积层,通过多个卷积层信息的叠加,可以最大化地增大感受视野范围,同时利用ResNet34来替换掉18。
预测:由于实验需要的图片需要长与宽一致,因此在谷歌地图上找了256*256(论文声称支持1024*1024)的瓦片来进行实验,发现必须找到16级以上的瓦片才可以实现检测,可能训练数据集中需要道路的宽度具有一定的长度才可以。



基于SegNet和U-Net的遥感图像语义分割
Blog:https://blog.csdn.net/real_myth/article/details/79432456
GitHub:https://github.com/AstarLight/Satellite-Segmentation(Satellite_Image_Segmentation_BY_SegNet_UNet)
步骤:
- Segmented by SegNet
- Segmented by U-Net
- Model Emsamble:SegNet + U-Net
数据集
数据下载:https://pan.baidu.com/s/1i6oMukH(密码:yqj2)| https://pan.baidu.com/s/1FwHkvp2esvhyOx1eSZfkog(密码:fqnw)
|-test 测试图片 |-train SegNet训练集 |----label 标记图 |----src 遥感图 |-unet_buildings UNet训练集 |----label 标记图 |----src 遥感图
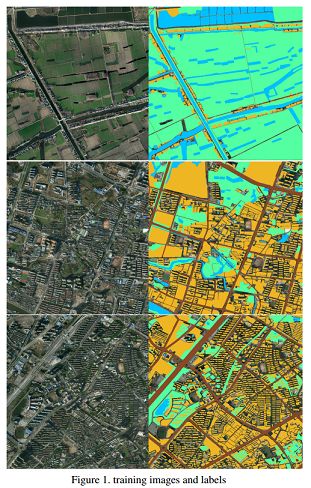
数据集来自CCF大数据比赛提供的数据(2015年中国南方某城市的高清遥感图像),是小数据集,里面包含了5张带标注的大尺寸RGB遥感图像(尺寸范围从3000×3000到6000×6000)
里面一共标注了4类物体:植被(标记1)、建筑(标记2)、水体(标记3)、道路(标记4)以及其他(标记0)。其中,耕地、林地、草地均归为植被类。更多数据介绍可以参看这里(https://www.datafountain.cn/#/competitions/270/data-intro)
训练图片及其标记图片可视化后的效果如下:蓝色-水体,黄色-房屋,绿色-植被,棕色-马路
问题:Label可视化 - 原始数据集里的训练集图片采用十六位的,图片浏览器显示全黑(一般图片浏览器无法显示16位图)
解决: 将深度16位的图片转为8位(比如,Matlab下:im2 = uint8(im1))
数据处理
原始图像:5张大尺寸的遥感图像(尺寸各不相同)
随机切割:随机生成x,y坐标,然后抠出该坐标下256*256的小图
# 执行切割 - UNet训练集 python ./unet/gen_dataset.py
数据增强(Keras自带的数据增广函数/):
- 原图和label图都需要旋转:90度、180度、270度
- 原图和label图都需要做沿y轴的镜像操作
- 原图做模糊操作
- 原图做光照调整操作
- 原图做增加噪声操作(高斯噪声、椒盐噪声)
# OpenCV编写的相应的增强函数
img_w = 256 img_h = 256 image_sets = ['1.png','2.png','3.png','4.png','5.png'] def gamma_transform(img, gamma): gamma_table = [np.power(x / 255.0, gamma) * 255.0 for x in range(256)] gamma_table = np.round(np.array(gamma_table)).astype(np.uint8) return cv2.LUT(img, gamma_table) def random_gamma_transform(img, gamma_vari): log_gamma_vari = np.log(gamma_vari) alpha = np.random.uniform(-log_gamma_vari, log_gamma_vari) gamma = np.exp(alpha) return gamma_transform(img, gamma) def rotate(xb,yb,angle): M_rotate = cv2.getRotationMatrix2D((img_w/2, img_h/2), angle, 1) xb = cv2.warpAffine(xb, M_rotate, (img_w, img_h)) yb = cv2.warpAffine(yb, M_rotate, (img_w, img_h)) return xb,yb def blur(img): img = cv2.blur(img, (3, 3)); return img def add_noise(img): for i in range(200): #添加点噪声 temp_x = np.random.randint(0,img.shape[0]) temp_y = np.random.randint(0,img.shape[1]) img[temp_x][temp_y] = 255 return img def data_augment(xb,yb): if np.random.random() < 0.25: xb,yb = rotate(xb,yb,90) if np.random.random() < 0.25: xb,yb = rotate(xb,yb,180) if np.random.random() < 0.25: xb,yb = rotate(xb,yb,270) if np.random.random() < 0.25: xb = cv2.flip(xb, 1) # flipcode>0:沿y轴翻转 yb = cv2.flip(yb, 1) if np.random.random() < 0.25: xb = random_gamma_transform(xb,1.0) if np.random.random() < 0.25: xb = blur(xb) if np.random.random() < 0.2: xb = add_noise(xb) return xb,yb def creat_dataset(image_num = 100000, mode = 'original'): print('creating dataset...') image_each = image_num / len(image_sets) g_count = 0 for i in tqdm(range(len(image_sets))): count = 0 src_img = cv2.imread('./data/src/' + image_sets[i]) # 3 channels label_img = cv2.imread('./data/label/' + image_sets[i],cv2.IMREAD_GRAYSCALE) # single channel X_height,X_width,_ = src_img.shape while count < image_each: random_width = random.randint(0, X_width - img_w - 1) random_height = random.randint(0, X_height - img_h - 1) src_roi = src_img[random_height: random_height + img_h, random_width: random_width + img_w,:] label_roi = label_img[random_height: random_height + img_h, random_width: random_width + img_w] if mode == 'augment': src_roi,label_roi = data_augment(src_roi,label_roi) visualize = np.zeros((256,256)).astype(np.uint8) visualize = label_roi *50 cv2.imwrite(('./aug/train/visualize/%d.png' % g_count),visualize) cv2.imwrite(('./aug/train/src/%d.png' % g_count),src_roi) cv2.imwrite(('./aug/train/label/%d.png' % g_count),label_roi) count += 1 g_count += 1
经过以上数据增强操作后,可得到了较大的训练集:100000张256*256的图片

卷积神经网络模型训练
图像语义分割任务-模型选择:FCN、U-Net、SegNet、DeepLab、RefineNet、Mask Rcnn、Hed Net
SegNet - 网络结构清晰易懂,训练快
# 执行训练 - 修改filepath为segnet训练集路径 python segnet_train.py --model segnet.h5 # --model后指定保存的模型名
网络结构定义:编码器-解码器(做语义分割时通常在末端加入CRF模块做后处理,旨在进一步精修边缘的分割结果)

def SegNet(): model = Sequential() #encoder model.add(Conv2D(64,(3,3),strides=(1,1),input_shape=(3,img_w,img_h),padding='same',activation='relu')) model.add(BatchNormalization()) model.add(Conv2D(64,(3,3),strides=(1,1),padding='same',activation='relu')) model.add(BatchNormalization()) model.add(MaxPooling2D(pool_size=(2,2))) #(128,128) model.add(Conv2D(128, (3, 3), strides=(1, 1), padding='same', activation='relu')) model.add(BatchNormalization()) model.add(Conv2D(128, (3, 3), strides=(1, 1), padding='same', activation='relu')) model.add(BatchNormalization()) model.add(MaxPooling2D(pool_size=(2, 2))) #(64,64) model.add(Conv2D(256, (3, 3), strides=(1, 1), padding='same', activation='relu')) model.add(BatchNormalization()) model.add(Conv2D(256, (3, 3), strides=(1, 1), padding='same', activation='relu')) model.add(BatchNormalization()) model.add(Conv2D(256, (3, 3), strides=(1, 1), padding='same', activation='relu')) model.add(BatchNormalization()) model.add(MaxPooling2D(pool_size=(2, 2))) #(32,32) model.add(Conv2D(512, (3, 3), strides=(1, 1), padding='same', activation='relu')) model.add(BatchNormalization()) model.add(Conv2D(512, (3, 3), strides=(1, 1), padding='same', activation='relu')) model.add(BatchNormalization()) model.add(Conv2D(512, (3, 3), strides=(1, 1), padding='same', activation='relu')) model.add(BatchNormalization()) model.add(MaxPooling2D(pool_size=(2, 2))) #(16,16) model.add(Conv2D(512, (3, 3), strides=(1, 1), padding='same', activation='relu')) model.add(BatchNormalization()) model.add(Conv2D(512, (3, 3), strides=(1, 1), padding='same', activation='relu')) model.add(BatchNormalization()) model.add(Conv2D(512, (3, 3), strides=(1, 1), padding='same', activation='relu')) model.add(BatchNormalization()) model.add(MaxPooling2D(pool_size=(2, 2))) #(8,8) #decoder model.add(UpSampling2D(size=(2,2))) #(16,16) model.add(Conv2D(512, (3, 3), strides=(1, 1), padding='same', activation='relu')) model.add(BatchNormalization()) model.add(Conv2D(512, (3, 3), strides=(1, 1), padding='same', activation='relu')) model.add(BatchNormalization()) model.add(Conv2D(512, (3, 3), strides=(1, 1), padding='same', activation='relu')) model.add(BatchNormalization()) model.add(UpSampling2D(size=(2, 2))) #(32,32) model.add(Conv2D(512, (3, 3), strides=(1, 1), padding='same', activation='relu')) model.add(BatchNormalization()) model.add(Conv2D(512, (3, 3), strides=(1, 1), padding='same', activation='relu')) model.add(BatchNormalization()) model.add(Conv2D(512, (3, 3), strides=(1, 1), padding='same', activation='relu')) model.add(BatchNormalization()) model.add(UpSampling2D(size=(2, 2))) #(64,64) model.add(Conv2D(256, (3, 3), strides=(1, 1), padding='same', activation='relu')) model.add(BatchNormalization()) model.add(Conv2D(256, (3, 3), strides=(1, 1), padding='same', activation='relu')) model.add(BatchNormalization()) model.add(Conv2D(256, (3, 3), strides=(1, 1), padding='same', activation='relu')) model.add(BatchNormalization()) model.add(UpSampling2D(size=(2, 2))) #(128,128) model.add(Conv2D(128, (3, 3), strides=(1, 1), padding='same', activation='relu')) model.add(BatchNormalization()) model.add(Conv2D(128, (3, 3), strides=(1, 1), padding='same', activation='relu')) model.add(BatchNormalization()) model.add(UpSampling2D(size=(2, 2))) #(256,256) model.add(Conv2D(64, (3, 3), strides=(1, 1), input_shape=(3,img_w, img_h), padding='same', activation='relu')) model.add(BatchNormalization()) model.add(Conv2D(64, (3, 3), strides=(1, 1), padding='same', activation='relu')) model.add(BatchNormalization()) model.add(Conv2D(n_label, (1, 1), strides=(1, 1), padding='same')) model.add(Reshape((n_label,img_w*img_h))) #axis=1和axis=2互换位置,等同于np.swapaxes(layer,1,2) model.add(Permute((2,1))) model.add(Activation('softmax')) model.compile(loss='categorical_crossentropy',optimizer='sgd',metrics=['accuracy']) model.summary() return model
划分数据集:读入数据集,选择的验证集大小是训练集的0.25
def get_train_val(val_rate = 0.25): train_url = [] train_set = [] val_set = [] for pic in os.listdir(filepath + 'src'): train_url.append(pic) random.shuffle(train_url) total_num = len(train_url) val_num = int(val_rate * total_num) for i in range(len(train_url)): if i < val_num: val_set.append(train_url[i]) else: train_set.append(train_url[i]) return train_set,val_set # data for training def generateData(batch_size,data=[]): #print 'generateData...' while True: train_data = [] train_label = [] batch = 0 for i in (range(len(data))): url = data[i] batch += 1 #print (filepath + 'src/' + url) #img = load_img(filepath + 'src/' + url, target_size=(img_w, img_h)) img = load_img(filepath + 'src/' + url) img = img_to_array(img) # print img # print img.shape train_data.append(img) #label = load_img(filepath + 'label/' + url, target_size=(img_w, img_h),grayscale=True) label = load_img(filepath + 'label/' + url, grayscale=True) label = img_to_array(label).reshape((img_w * img_h,)) # print label.shape train_label.append(label) if batch % batch_size==0: #print 'get enough bacth!\n' train_data = np.array(train_data) train_label = np.array(train_label).flatten() train_label = labelencoder.transform(train_label) train_label = to_categorical(train_label, num_classes=n_label) train_label = train_label.reshape((batch_size,img_w * img_h,n_label)) yield (train_data,train_label) train_data = [] train_label = [] batch = 0 # data for validation def generateValidData(batch_size,data=[]): #print 'generateValidData...' while True: valid_data = [] valid_label = [] batch = 0 for i in (range(len(data))): url = data[i] batch += 1 #img = load_img(filepath + 'src/' + url, target_size=(img_w, img_h)) img = load_img(filepath + 'src/' + url) #print img #print (filepath + 'src/' + url) img = img_to_array(img) # print img.shape valid_data.append(img) #label = load_img(filepath + 'label/' + url, target_size=(img_w, img_h),grayscale=True) label = load_img(filepath + 'label/' + url, grayscale=True) label = img_to_array(label).reshape((img_w * img_h,)) # print label.shape valid_label.append(label) if batch % batch_size==0: valid_data = np.array(valid_data) valid_label = np.array(valid_label).flatten() valid_label = labelencoder.transform(valid_label) valid_label = to_categorical(valid_label, num_classes=n_label) valid_label = valid_label.reshape((batch_size,img_w * img_h,n_label)) yield (valid_data,valid_label) valid_data = [] valid_label = [] batch = 0
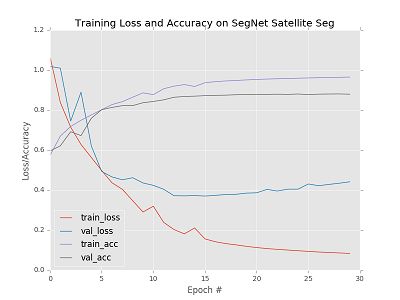
训练: batch size定为16,epoch定为30,每次都存储最佳model(save_best_only=True),并且在训练结束时绘制loss/acc曲线,并存储起来
def train(args): EPOCHS = 30 BS = 16 model = SegNet() modelcheck = ModelCheckpoint(args['model'],monitor='val_acc',save_best_only=True,mode='max') callable = [modelcheck] train_set,val_set = get_train_val() train_numb = len(train_set) valid_numb = len(val_set) print ("the number of train data is",train_numb) print ("the number of val data is",valid_numb) H = model.fit_generator(generator=generateData(BS,train_set),steps_per_epoch=train_numb//BS,epochs=EPOCHS,verbose=1, validation_data=generateValidData(BS,val_set),validation_steps=valid_numb//BS,callbacks=callable,max_q_size=1) # plot the training loss and accuracy plt.style.use("ggplot") plt.figure() N = EPOCHS plt.plot(np.arange(0, N), H.history["loss"], label="train_loss") plt.plot(np.arange(0, N), H.history["val_loss"], label="val_loss") plt.plot(np.arange(0, N), H.history["acc"], label="train_acc") plt.plot(np.arange(0, N), H.history["val_acc"], label="val_acc") plt.title("Training Loss and Accuracy on SegNet Satellite Seg") plt.xlabel("Epoch #") plt.ylabel("Loss/Accuracy") plt.legend(loc="lower left") plt.savefig(args["plot"])
预测 - 预测整张遥感图像:1)训练模型时选择的图片输入是256×256,所以预测时也要采用256×256的图片尺寸送进模型预测;2)将预测好的小图重新拼接成一个大图 - 先给大图做padding 0操作,得到一副padding过的大图,同时我们也生成一个与该图一样大的全0图A,把图像的尺寸补齐为256的倍数,然后以256为步长切割大图,依次将小图送进模型预测,预测好的小图则放在A的相应位置上,依次进行,最终得到预测好的整张大图(即A),再做图像切割,切割成原先图片的尺寸,完成整个预测流程
# 执行预测 - 修改待预测的图片的路径 python segnet_predict.py
def predict(args): # load the trained convolutional neural network print("[INFO] loading network...") model = load_model(args["model"]) stride = args['stride'] for n in range(len(TEST_SET)): path = TEST_SET[n] #load the image image = cv2.imread('./test/' + path) # pre-process the image for classification #image = image.astype("float") / 255.0 #image = img_to_array(image) h,w,_ = image.shape padding_h = (h//stride + 1) * stride padding_w = (w//stride + 1) * stride padding_img = np.zeros((padding_h,padding_w,3),dtype=np.uint8) padding_img[0:h,0:w,:] = image[:,:,:] padding_img = padding_img.astype("float") / 255.0 padding_img = img_to_array(padding_img) print 'src:',padding_img.shape mask_whole = np.zeros((padding_h,padding_w),dtype=np.uint8) for i in range(padding_h//stride): for j in range(padding_w//stride): crop = padding_img[:3,i*stride:i*stride+image_size,j*stride:j*stride+image_size] _,ch,cw = crop.shape if ch != 256 or cw != 256: print 'invalid size!' continue crop = np.expand_dims(crop, axis=0) #print 'crop:',crop.shape pred = model.predict_classes(crop,verbose=2) pred = labelencoder.inverse_transform(pred[0]) #print (np.unique(pred)) pred = pred.reshape((256,256)).astype(np.uint8) #print 'pred:',pred.shape mask_whole[i*stride:i*stride+image_size,j*stride:j*stride+image_size] = pred[:,:] cv2.imwrite('./predict/pre'+str(n+1)+'.png',mask_whole[0:h,0:w])
预测效果图:

问题:预测图Mask-Label可视化 - 每类物体对应的标签的值都是1到5,都接近黑色
解决: https://github.com/AstarLight/Satellite-Segmentation/blob/master/draw_lables.cpp
import cv2 import numpy as np ALL = 0 VEGETATION = 1 ROAD = 4 BUILDING = 2 WATER = 3 TEST_SET = ['1.png','2.png','3.png'] Mask_Set = ['pre1.png','pre2.png','pre3.png'] for n in range(len(TEST_SET)): print(n) path = TEST_SET[n] mask_path = Mask_Set[n] src = cv2.imread('../data/remote_sensing_image/test/' + path) mask = cv2.imread('./predict/'+mask_path) print(np.shape(mask)) h,w,_ = src.shape for i in range(0, h): for j in range(0, w): if (mask[i, j, 0] == VEGETATION): src[i, j, 0] = 159 src[i, j, 1] = 255 src[i, j, 2] = 84 if (mask[i, j, 0] == ROAD): src[i, j, 0] = 38 src[i, j, 1] = 71 src[i, j, 2] = 139 if (mask[i, j, 0] == BUILDING): src[i, j, 0] = 34 src[i, j, 1] = 180 src[i, j, 2] = 238 if (mask[i, j, 0] == WATER): src[i, j, 0] = 255 src[i, j, 1] = 191 src[i, j, 2] = 0 cv2.imwrite('./predict/stack' + str(n + 1) + '.png', src)
问题:拼接痕迹过于明显
解决:缩小切割时的滑动步伐,比如把切割步伐改为128,那么拼接时就会有一半的图像发生重叠,这样做可以尽可能地减少拼接痕迹
U-Net - 小数据集也能训练出好的模型,训练快
# 执行训练 python unet_train.py --model unet_buildings20.h5 --data ./unet_train/buildings/ # --data后指定UNet训练集路径
网络结构定义:整个呈现U形,故起名U-Net
1)四类物体 - 多分类模型 - 直接4分类
2)每一类物体 - 二分类模型 - 得到4张预测图,再做预测图叠加,合并成一张完整的包含4类的预测图(loss function = binary_crossentropy 训练二分类模型)
def unet(): inputs = Input((3, img_w, img_h)) conv1 = Conv2D(32, (3, 3), activation="relu", padding="same")(inputs) conv1 = Conv2D(32, (3, 3), activation="relu", padding="same")(conv1) pool1 = MaxPooling2D(pool_size=(2, 2))(conv1) conv2 = Conv2D(64, (3, 3), activation="relu", padding="same")(pool1) conv2 = Conv2D(64, (3, 3), activation="relu", padding="same")(conv2) pool2 = MaxPooling2D(pool_size=(2, 2))(conv2) conv3 = Conv2D(128, (3, 3), activation="relu", padding="same")(pool2) conv3 = Conv2D(128, (3, 3), activation="relu", padding="same")(conv3) pool3 = MaxPooling2D(pool_size=(2, 2))(conv3) conv4 = Conv2D(256, (3, 3), activation="relu", padding="same")(pool3) conv4 = Conv2D(256, (3, 3), activation="relu", padding="same")(conv4) pool4 = MaxPooling2D(pool_size=(2, 2))(conv4) conv5 = Conv2D(512, (3, 3), activation="relu", padding="same")(pool4) conv5 = Conv2D(512, (3, 3), activation="relu", padding="same")(conv5) up6 = concatenate([UpSampling2D(size=(2, 2))(conv5), conv4], axis=1) conv6 = Conv2D(256, (3, 3), activation="relu", padding="same")(up6) conv6 = Conv2D(256, (3, 3), activation="relu", padding="same")(conv6) up7 = concatenate([UpSampling2D(size=(2, 2))(conv6), conv3], axis=1) conv7 = Conv2D(128, (3, 3), activation="relu", padding="same")(up7) conv7 = Conv2D(128, (3, 3), activation="relu", padding="same")(conv7) up8 = concatenate([UpSampling2D(size=(2, 2))(conv7), conv2], axis=1) conv8 = Conv2D(64, (3, 3), activation="relu", padding="same")(up8) conv8 = Conv2D(64, (3, 3), activation="relu", padding="same")(conv8) up9 = concatenate([UpSampling2D(size=(2, 2))(conv8), conv1], axis=1) conv9 = Conv2D(32, (3, 3), activation="relu", padding="same")(up9) conv9 = Conv2D(32, (3, 3), activation="relu", padding="same")(conv9) conv10 = Conv2D(n_label, (1, 1), activation="sigmoid")(conv9) #conv10 = Conv2D(n_label, (1, 1), activation="softmax")(conv9) model = Model(inputs=inputs, outputs=conv10) model.compile(optimizer='Adam', loss='binary_crossentropy', metrics=['accuracy']) return model
划分数据集:读取数据
# data for training def generateData(batch_size,data=[]): #print 'generateData...' while True: train_data = [] train_label = [] batch = 0 for i in (range(len(data))): url = data[i] batch += 1 img = load_img(filepath + 'src/' + url) img = img_to_array(img) train_data.append(img) label = load_img(filepath + 'label/' + url, grayscale=True) label = img_to_array(label) #print label.shape train_label.append(label) if batch % batch_size==0: #print 'get enough bacth!\n' train_data = np.array(train_data) train_label = np.array(train_label) yield (train_data,train_label) train_data = [] train_label = [] batch = 0 # data for validation def generateValidData(batch_size,data=[]): #print 'generateValidData...' while True: valid_data = [] valid_label = [] batch = 0 for i in (range(len(data))): url = data[i] batch += 1 img = load_img(filepath + 'src/' + url) #print img img = img_to_array(img) # print img.shape valid_data.append(img) label = load_img(filepath + 'label/' + url, grayscale=True) valid_label.append(label) if batch % batch_size==0: valid_data = np.array(valid_data) valid_label = np.array(valid_label) yield (valid_data,valid_label) valid_data = [] valid_label = [] batch = 0
训练:指定输出model名字和训练集位置
python unet.py --model unet_buildings20.h5 --data ./unet_train/buildings/
预测 - 预测单张遥感图像:分别使用4个模型做预测,得到4张mask(比如下图是用训练好的buildings模型预测的结果),再将4张mask合并成1张 - 通过观察每一类的预测结果,根据不同类物体的预测准确率,给4类mask图排优先级(building>water>road>vegetation),当遇到一个像素点,4个mask图都说是属于自己类别的标签时,就可以根据先前定义好的优先级,把该像素的标签定为优先级最高的标签
# 执行预测 python unet_predict.py

def combind_all_mask(): for mask_num in tqdm(range(3)): if mask_num == 0: final_mask = np.zeros((5142,5664),np.uint8)#生成一个全黑全0图像,图片尺寸与原图相同 elif mask_num == 1: final_mask = np.zeros((2470,4011),np.uint8) elif mask_num == 2: final_mask = np.zeros((6116,3356),np.uint8) #final_mask = cv2.imread('final_1_8bits_predict.png',0) if mask_num == 0: mask_pool = mask1_pool elif mask_num == 1: mask_pool = mask2_pool elif mask_num == 2: mask_pool = mask3_pool final_name = img_sets[mask_num] for idx,name in enumerate(mask_pool): img = cv2.imread('./predict_mask/'+name,0) height,width = img.shape label_value = idx+1 #coressponding labels value for i in tqdm(range(height)): #priority:building>water>road>vegetation for j in range(width): if img[i,j] == 255: if label_value == 2: final_mask[i,j] = label_value elif label_value == 3 and final_mask[i,j] != 2: final_mask[i,j] = label_value elif label_value == 4 and final_mask[i,j] != 2 and final_mask[i,j] != 3: final_mask[i,j] = label_value elif label_value == 1 and final_mask[i,j] == 0: final_mask[i,j] = label_value cv2.imwrite('./final_result/'+final_name,final_mask) print 'combinding mask...' combind_all_mask()
模型融合
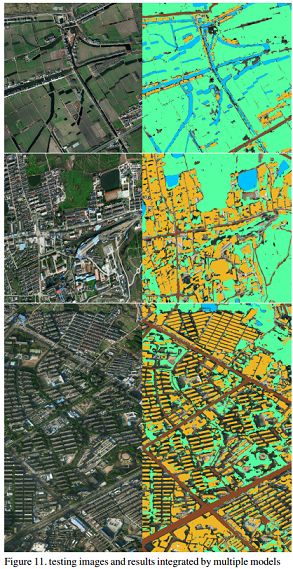
集成学习:两个模型 + 模型采取不同参数训练 - 得到很多预测MASK图 - 对每张结果图的每个像素点采取投票表决
少数服从多数的投票表决:对每张图相应位置的像素点的类别进行预测,票数最多的类别即为该像素点的类别 - 可以很好地去掉一些明显分类错误的像素点,很大程度上改善模型的预测能力
import numpy as np import cv2 import argparse RESULT_PREFIXX = ['./result1/','./result2/','./result3/'] # each mask has 5 classes: 0~4 def vote_per_image(image_id): result_list = [] for j in range(len(RESULT_PREFIXX)): im = cv2.imread(RESULT_PREFIXX[j]+str(image_id)+'.png',0) result_list.append(im) # each pixel height,width = result_list[0].shape vote_mask = np.zeros((height,width)) for h in range(height): for w in range(width): record = np.zeros((1,5)) for n in range(len(result_list)): mask = result_list[n] pixel = mask[h,w] #print('pix:',pixel) record[0,pixel]+=1 label = record.argmax() #print(label) vote_mask[h,w] = label cv2.imwrite('vote_mask'+str(image_id)+'.png',vote_mask) vote_per_image(3)
模型融合后的预测结果
额外的思路
1、GAN - Image-to-Image Translation with Conditional Adversarial Nets (pix2pix: generate some fake satellite images to enlarge the dataset)
针对数据集小的问题:使用生成对抗网络生成虚假的卫星地图(用标注好的卫星地图生成虚假的卫星地图) - 进一步扩大数据集 - 使用这些虚假+真实的数据集训练网络 - 网络的泛化能力将有更大的提升



问题:由于标注得不好,生成的虚假卫星地图质量不好(如下右图)
2、DeepLab
3、Mask RCNN
4、FCN
5、RefineNet
6、Post-Processing: CRF
基于ResNet+U-Net和Mask-R-CNN的卫星地图建筑物分割
地图图像识别的目标
在卫星图片上标注出建筑物轮廓:该分割目标与其它大型比赛(如微软的COCO Challenge、谷歌的Google AI Open Images比赛)相比,物体类别单一,且图片质量均匀
数据集
如图所示,是一组人工标注完善的卫星图片,其Mask和建筑物匹配度高,该图来自Crowdai上的比赛Mapping Challenge
地图图像识别数据集准备
生成训练样本
训练数据来源:都不是人工直接标注出的卫星图像,而是有一个由人工打上地理标记的图层文件(shapefile格式 - GIS领域的标准数据格式)以及从Google Map上抓取到的对应地区的卫星图片
构建训练数据:将图层文件中的标记(经纬度坐标)映射到Google Map卫星图片上(以图片左上角为原点,向右为X轴,向下为Y轴)
方法:Google Map JavaScript API的转换方式(用Python语言重写实现)
标注数据的格式
生成的数据集都是COCO风格的标注数据(COCO标注数据的具体规范可以参考https://github.com/cocodataset/cocoapi这个Github repo里的示例代码,在Windows安装Pycocotools的话可以参考https://github.com/philferriere/cocoapi)
问题:目前生成的训练数据中,标注与真实房屋的位置,很多图像上有大约10-20个像素的偏差(图片大小300 x 300),也有不少标注大于房屋实际面积的情况。甚至存在标注面积实际为房屋面积的2倍以上,这将导致如果精准分割出房屋,使用IoU>0.5作为阈值过滤掉不合格预测结果,再计算准确率的话,很多实际上完美分割的结果,会被认为是无效的。如图(红色边框较蓝色房屋,大小相似,但是位置偏移;黄色边框将绿色的建筑物全部囊括,但是面积要大很多,此时如果完美分割绿色建筑物,IoU很可能由于小于0.5而无效):

深度神经网络模型
ResNet+U-Net
Crowdai上举办了Open Map Challenge,其所解决的问题和这个问题相近,排名第一的队伍是Neptume.ml公司(其Github Repo地址:https://github.com/neptune-ml/open-solution-mapping-challenge)
其所使用的模型是ResNet 101和U-Net的组合,使用预训练的ResNet101对图像进行特征提取,再使用U-Net进行图像分割
模型的损失函数由两部分组成:loss = binary_cross_entropy * weight1 + dice_loss * weight2
其中,Binary Cross Entropy是计算预测值与实际标注每一个像素的异同,Dice Loss是用IoU的思想计算预测值与实际标注的偏差,两种Loss值的权重是需要人为设定的超参数,根据Github中的描述,模型训练前期,需要更多考虑Binary Cross Entropy损失值
Mask-R-CNN
比赛的主办方,给出的Baselline模型是Mask-R-CNN模型(Github:https://github.com/crowdAI/crowdai-mapping-challenge-mask-rcnn)
相较比赛第一名使用的RestNet+U-Net的方式,Mask-R-CNN模型太重型,这个模型一般用于解决复杂场景下的图像分类、物体检测和语义分割问题
问题:生成的训练集质量较低,导致肉眼评估模型,觉得模型表现尚可,但是使用程序比较预测结果的查全率/查准率(IoU >= 0.5),结果很差