我们从这节课开始,讲Spark的内核,英文叫做Spark Core,在讲Spark Core之前我们先讲一个重要的概念,RDD,

我们Spark所有的计算,都是基于RDD来计算的,我们所有的计算都是通过RDD来计算的,那问题来了,RDD到底是什么?
resilient 美 [rɪ'zɪlɪənt]
adj. 弹回的,有弹力的
adj. 能复原的;有复原力的
distributed 美 [dɪ'strɪbjʊtɪd]
adj. 分布式的,分散式的
dataset 美 ['detə]美 [sɛt]
数据集合
这是我们Spark最核心的数据结构,我们所有的开发编程,都是围绕这这个RDD来展开的
根据这个名字,我们猜猜这个RDD是什么意思?
这个词是个什么词性,是个名词对吧?Dataset,数据集,我们学习Java的时候学过这个Set把,他是一个集合对吧,data名词,给这个Set这个当做定语对吧?说明这是一个数据的集合对吧?Resilient形容词,形容这个数据集,是有弹性的,弹性什么意思,可以伸缩对吧,你拉他一下,他自己可以回到原来的状态对吗?他把这个定语放在这什么意思,说明我们这个数据集是能够自我修复对吧?
能够自我修复是什么意思?
《Learning Spark:Lightning-fast Data Analysis》一书中解释“弹性”是指在任何时候都能进行重算。这样当集群中的一台机器挂掉而导致存储在其上的RDD丢失后,Spark还可以重新计算出这部分的分区的数据。但用户感觉不到这部分的内容丢失过。这样RDD数据集就像块带有弹性的海绵一样,不管怎样挤压(分区遭到破坏)都是完整的。
分布式是什么意思?
分布式对应的就是单机的系统
那我们说分布式的优点是什么啊?其实优点还是有很多的,但最显著的优点就是有3个,他可以负载均衡是吗?当我们的计算资源,紧缺时,可以使用其他的计算资源对吗?他可以容错对吗?当我们一台机器的数据坏掉了,还有另外一个机器做副本,所以还可以找回来对吗?扩展性强对吗?我们可以提供更多的机器,更多的计算资源,更多的存储资源,为整个分布式系统提供水平的线性扩展,对吗?
那我们现在明白这个RDD是什么了吗?
大家还记得我们之前写的WordCount是怎么写的吗?
sc.这个sc是Spark上下文这么一个对象,SparkContext
sc.textFile这是读一个文件,Spark会将这个文件,加载到RDD里面去啊?
sc.textFile返回的是一个RDD对象 是吧?
然后rdd.flatMap.map.reduceByKey 对吧然后foreach打印一下对吧?
这种...是链式编程结构的一种计算,啥叫链式编程结构呢,就是flatMap的返回对象其实还是一个rdd对吧?
所以说一切都是基于RDD的
现在我们知道了RDD是弹性分布式数据集,
那么他有5大特性,我们说RDD的5大特性,我们可以把他理解为RDD的5个属性
这5大特性,我们用画图的方式来讲一下
这5大特性,我讲完之后你们可能会有一些疑问
到时候你们可以来问我,但我不一定会回答,为什么?因为随着课程的深入,这5个特性都会给你们讲明白,这就叫循序渐进,知道吗?
如果你们现在问的所有问题我都去回答的话,太深入的东西你们肯定理解不了,能明白我的意思吗?
大家不用担心,对基础比较好的东西,我在PPT的最后,给大家提供个链接,这是我们这个系列课程最后一天要给大家讲的内容,有余力的同学可以深入研究一下
我们用画图的方式来讲这5大特性,
比如说我们Spark现在要计算的数据,是放到HDFS上面

比如我们现在要处理的这个文件由3个Block组成的

那么这个文件是不是可能在不同的节点上?
然后我要用Spark来计算一下这个文件,首先是不是要把这个文件加载到Spark里面来啊?

哪一行代码?我们用sc.textFile(“hdfs://hostname:port/path”)

我们调用了sc.textFite方法,他给我们返回回来一个rdd是吧?

这个RDD里面是有一系列的分区的,我们刚才说了,RDD是不是一个弹性分布式数据集啊?
他是一个分布式的数据集,我们可以和hdfs里面的概念和这个类比,Hadoop里面是不是有block啊?hdfs之所以是分布式,是不是因为里面有hdfs里面叫做block的存储单元啊?如果hdfs里面没有存储单元,那他能完成分布式吗?如果没有这个存储单元这么一说,一个大文件,要么存在A机器,要么存在B机器。如果一台机器存不下,那我们只能去扩展这台机器的硬盘对吗?我们想实现分布式存储,我们首先需要把一个大文件拆成很多小文件,通过索引的方式知道文件的先后顺序和存储位置,就可以实现分布式存储系统了,对吗?
那我们RDD他也是分布式的,是不是也需要类似Block这样的分布式的存储单元啊?那我们Spark里面就叫他是Partition
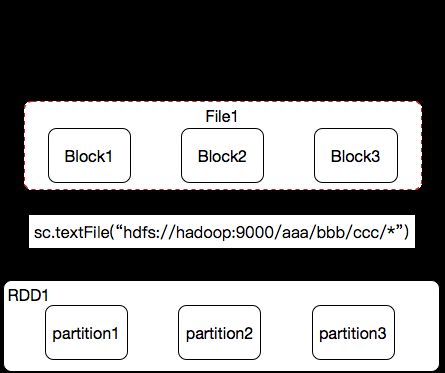
那到底有多少个partition是有谁来决定的?那么到底有多少个Partition是由我要读取的这个file的Block数量决定的?能理解吗?
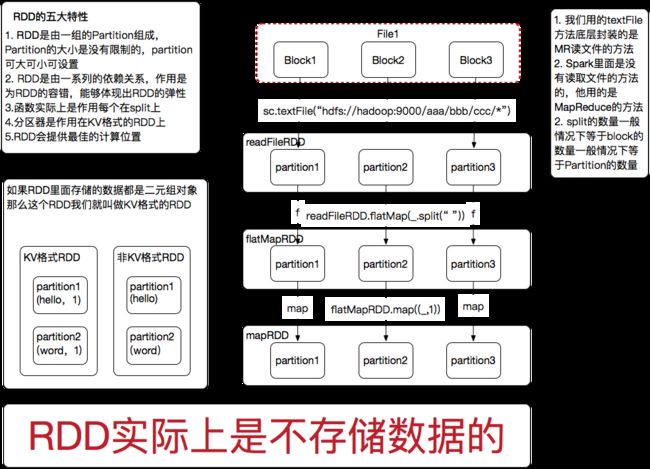
那再跟大家深入的说一下,这个textFile是一个读文件的方法
它的底层封装的是MR读文件的方法,Spark本身是没有读文件的方法的,他调用的是MapReduce读文件的方法
那我们mapreduce读文件就有特点了,首先他要干嘛?
MR读文件之前是不是要先划分split
那准确的来说,每一个Partition是和我们Split对应的对吗?
又因为Split和Block一般情况下是一样的,所以Partition的数量和Block的数量是一样的
那一般情况下就把partition的个数记成和block数量是一样的
hadoop里面的Split数量是如何决定的?
【Hadoop】三句话告诉你 mapreduce 中MAP进程的数量怎么控制?
然后我们继续画图

我们读完文件,通过flatmap.map.reduceByKey一系列算子的转换,完成了我们WordCount这个业务
新的RDD都是依赖上级的RDD的,
我们的resultRDD是依赖mapRDD的
mapRDD是依赖flatMapRDD的
flatMapRDD是依赖readFileRDD
我们继续画图,我们之前编程的时候是针对RDD的方法,其实通过我们之后的讲解,大家就会知道,我们的textFile算子,flatMap算子,map算子,reduceByKey算子都是作用在partition上的,所以我们这个图要修改一下

我们继续来讲第四个特性

在什么阶段有分区器啊?在Suffle阶段才会有分区器,
分区器的作用是什么?决定我这一条记录是写在哪个磁盘小文件上
那什么是kv格式的RDD我们画图演示一下
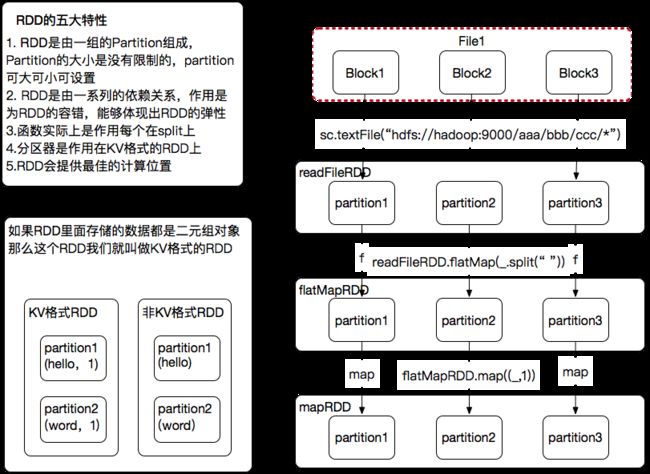
我们这个flatMepRDD是基于readFileRDD的,readFileRDD里面的partition可能是在不同的Block节点上面进行存储的,那要是基于RDD进行计算,是要启动task任务,那我这个Task任务分发到哪个节点上是最好的呢?是不是分发到数据所在的节点上是最好的啊?这就符合我们大数据的计算原则,移动计算而不移动数据
第五个这个特性就是说,这个readFileRDD会对外提供一个接口,我调用这个接口我就知道每个Partition所在的节点,和具体的位置
知道他的位置以后,可以参考这个位置,分发Task去执行,执行完之后就得到flatMap这个RDD了
答疑时间,哪不理解
有同学说第五个特性不理解,
rdd可以提供最佳的计算位置,task计算的数据本地化
第五个特性,我们在讲Spark调优的时候,会专门拿出一节课的时间来讲这第五个特性
第四个特性,我们会在讲shuffle的时候,详细的讲为什么会有这第四个特性
我们在这里看一下源码,这五个特性是RDD这个类里面的注释
那我们该如何去找RDD这个类呢?
用搜索,快捷键是按两下shift,
或者我们从代码里面找,core->src->main->scala->rdd->RDD
rdd这个包里面有很多的各种各样的RDD,其中有一个叫RDD的这样一个抽象类
包里面的其他RDD都是这个RDD的子类
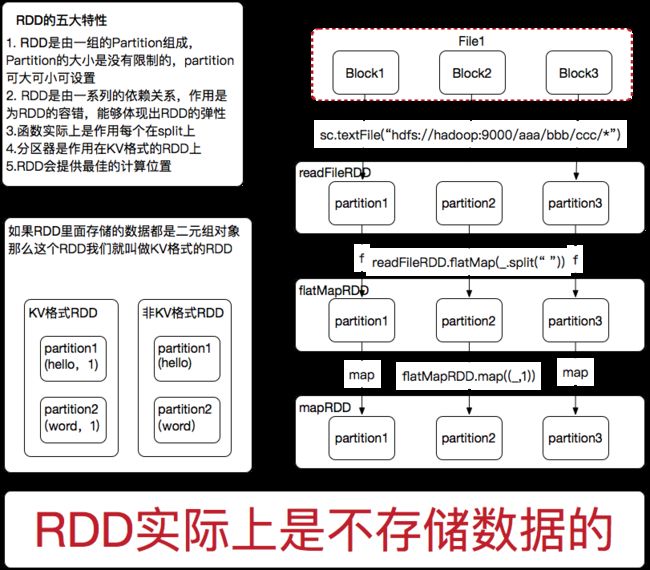
最后总结一点,RDD实际上是不存储数据的
对于初学者的你们来说,今天一天,你们把RDD以为里面是存储数据的,这样便于你们与JAVA开发里面的集合类做类比,这样比较方便你们记住这个概念,但这样的理解就仅限于今天一天,因为随着你们学习的深入,你们更多的概念你们会记住,就不需要用这个存数据来关联这个记忆了
RDD不存数据这个事,我明天会给你们讲明白,这样更方便你们入门
最终这张图片放在这里
好我们RDD就先讲到这里
下面我们看这张PPT
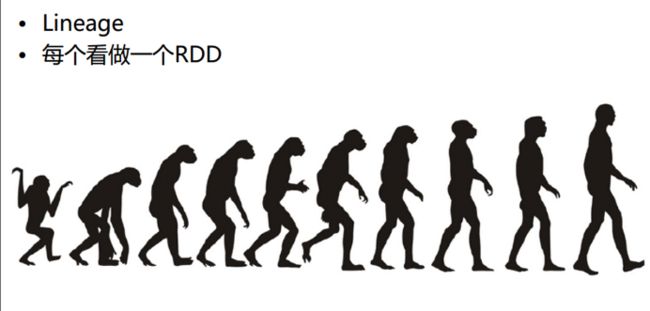
这是一张进化的图,非常像我们的RDD
这里有一个名词,叫做Lineage,翻译成中文,是血统的意思
人的这一个方向是我们的resultRDD 猴子的这个方向是我们的数据源
当我们在中间的RDD出现问题的过程中,我们可以通过他的父RDD来做重新计算,这是Spark保证数据容错的一个根本。
Spark任务执行的流程

这是一个最简单的Spark执行的流程,之后我们会逐步深入的讲这个执行流程,这个执行流程也是我们在面试中经常会被问到的。
看这张图,一共有四台服务器规模的一个集群
这台服务器上启动了一个进程叫做Driver进程,还有其他三台服务器,启动一个Worker进程
这些都是真实的服务器,所以服务器上面会有一些计算用的RAM内存,这些服务器还有磁盘,磁盘上存储着我们要计算的数据
通过这张图来看,Driver这个进程主要负责人什么?
调度,什么调度啊?任务调度是吗?
是不是task的下发和result的收集啊?
大家想Driver是负责结果的回收,那如果计算的结果特别大,会有什么一个后果啊?
刚才我有讲说Driver他是一个进程,进程的内存是不是有限啊?
如果计算的结果result非常的大,是不是会导致Driver进程OOM啊?
我们看到的Driver,Worker他都是一个JVM进程,
JVM是什么啊?是不是java虚拟机啊?来大家跟上我的思路啊,我问的问题,一定在脑袋里面过一下啊
从这张图来看,Driver是不是跟我们的集群,会有频繁的通信啊?
都有哪些通信啊,分发Task是不是通信啊?收集结果是不是通信啊?
那我们说Driver做调度,Driver是不是要知道Worker执行的情况啊?
举个例子,我们在公司里面工作,领导分配给你一个任务,你说这任务特别的难,我自己研究一个礼拜,一个礼拜以后领导来问你,你告诉他你搞不定,领导会喜欢你这样的员工吗?
那你要是员工你应该怎么做啊?
讲这张图的目的,是让大家对Spark任务执行流程有个初步的了解,
Driver与Worker之间会有频繁的通信,就是你跟你领导要有频繁的沟通。
大家能记住这一点吗?要怎么?要沟通,对吗?谁跟谁来沟通?Driver和Worker来沟通
然后我们继续往下,如果我们要写一个Spark程序,那流程是什么样子的呢?
我们来感受一下写应用程序怎么写?

首先加载数据集对吗?数据集可以是Hadoop分布式文件系统上的数据
可以是Hbase的数据,可以是Hive的数据,可以是NoSQL的数据,可以是本机的数据,
也可以是内存对象的数据,加载完的数据对象,就是我们的RDD
我们现在有了RDD以后是不是要对这个RDD进行一系列的操作啊?
我们可以对RDD进行transformation类的操作
什么叫transformation类的操作啊?
我们之前所讲的flatMap、map、reduceByKey都属于transformation类的算子
transformation他是一个类别的名称,在这个类里面有很多具体的算子
那这些就是具体的算子
所有的transformation类算子他有一个特点,就是他是延迟执行的。
对刚加载过来的RDD,执行一把flatMap,实际上他并不会真正的去执行,他等待一个时机来触发执行,
还有一类的算子叫做action类算子,Action类算子他是立即执行,或者说叫触发执行
一个Spark 应用程序 你写的一系列转换,他是由transformation类算子进行转换的
遇到Action类算子才会执行
我们在写WordCount的时候,最后有一个foreach算子,老师在这告诉大家,foreach算子是一个Action算子,所以我们的程序可以执行出结果
大家可以式一下,如果不写foreach算子,程序并不会执行

我们可以看一下这段代码,这是一段伪代码
sc.textFile他是读一个文件对吧?
filter是过滤的这样一个transformation类算子
他会将lines这个RDD的内容进行过滤,那过滤的条件是什么?startWith(“ERROR”)
我们之前讲过Boolean类型的匿名函数,我们称他为谓词,大家还记得吗?
那大家回忆一下,Boolean是true的时候是保留还是false的时候是保留啊?
那保留的结果是不是放到errors这个RDD里面去了
那下面一行将errors又进行了一次过滤,包含MySQL的内容过滤出来了
在.count之前也是一个延迟执行的transformation类算子,我们把这个结果进行一个count计数由于count是Action类算子,所以他立即执行
最下面一行也是一样,过滤了包含Http这样一个字符串的所有记录
整个这一段代码我们叫他为Spark Application,Spark应用程序
在这段代码里面有几个Action类算子,那么这个应用程序就有多少个Job
Job的个数与我们的Action类算子是一一对应的。
那么一个Application里面可以有很多个job,那有多少个Action类算子就有多少个Job