硝烟中的Scrum和XP_学习笔记
1, 如何活学活用
孙子兵法有云:兵无常势,水无常形,能因敌变化而取胜者谓之神。很多人都向往用兵如神的境界,想必也知道读万卷书不如行万里路,纸上谈兵的故事更是耳熟能详;但偏偏不能举一反三。
且看风清扬的一段话:“......你将这华山派的三四十招融合贯通,设想如何一气呵成,然后全部将它忘了,忘得干干净净,一招也不可留在心中。待会便以甚么招数也没有的华山剑法,去跟田伯光对打”。如果有人说,既然“无招胜有招”是武学的最高境界,那干脆什么招数都不要学,拿把剑乱挥乱舞,处处破绽,也就处处无破绽,便是天下第一了。听到这话的人肯定会笑他太缺心眼。
根据 Nokia 标准来做迭代开发。迭代开发是敏捷宣言的基本原则——在早期频繁的交付可工作的软件。
Nokia 用了几年时间,对上百个 Scrum 团队的工作进行了回顾,总结出了迭代开发的基本需求:
迭代要有固定时长(被称为“时间盒——timebox”),不能超过六个星期。
在每一次迭代的结尾,代码都必须经过 QA 的测试,能够正常工作。
Nokia 的 Scrum标准:
Scrum 团队必须要有产品负责人,而且团队都清楚这个人是谁。
产品负责人必须要有产品 Backlog,其中包括团队对它进行的估算。
团队必须要有燃尽图,而且要了解他们自己的生产率。
在一个 Sprint 中,外人不能干涉团队的工作。
scrum拥有如下产物:
产品 Backlog、对于这个 Backlog 的估算、燃尽图;
你会了解团队的生产率,
并掌握在切实有效的 Scrum 过程中所包含的众多基础实践。
用Ken Schwaber的话说,Scrum不是方法学,它是一个框架。也就是说Scrum不会告诉你到底该做些什么。
XP 实践——各种各样的每日构建,结对编程,测试驱动开发,等等;
产品 backlog 是 Scrum 的核心,也是一切的起源。从根本上说,它就是一个需求、或故事、或特性等组成的列表,按照重要性的级别进行了排序。它里面包含的是客户想要的东西,并用客户的术语加以描述。
ID——统一标识符,就是个自增长的数字而已。以防重命名故事以后找不到它们。
Name(名称)——简短的、描述性的故事名。比如“查看你自己的交易明细”。它必须要含义明确,这样开发人员和产品负责人才能大致明白我们说的是什么东西,跟其他故事区分开。它一般由 2 到 10 个字组成。
Importance(重要性)——产品负责人评出一个数值,指示这个故事有多重要。例如 10 或 150。分数越高越重要。
o 我一直都想避免“优先级”这个说法,因为一般说 来优先级 1 都表示“最高”优先级,如果后来有其他更重要的东西就麻烦了。 它的优先级评级应该是什么呢?优先级 0?优先级-1?
Initial estimate(初始估算)——团队的初步估算,表示与其他故事相比,完成该故事所需的工作量。最小的单位是故事点(story point),一般大致相当于一个“理想的人天(man-day)”。
o 问一下你的团队, “如果可以投入最适合的人员来完成这个故事(人数要适中,通常为 2 个),把你们锁到一个屋子里,有很多食物,在完全没有打扰的情况下工作,那么需要几天,才能给出一个经过测试验证,可以交付的完整实现呢?”如果答案是“把 3 个人关在一起,大约需要 4 天时间”,那么初始估算的结果就是 12 个故事点。
o 不需要保证这个估值绝对无误 (比如两个故事点的故事就应该花两天时间),而是要保证相对的正确性(即,两个点的故事所花费的时间应该是四个点的故事所需的一半)
How to demo (如何做演示)——它大略描述了这个故事应该如何在 sprint 演示上进行示范,本质就是一个简单的测 试规范。“先这样做,然后那样做,就应该得到......的结果 ”。
o 如果你在使用 TDD(测试驱动开发),那么这段描述就可以作为验收测试的伪码表示。
Notes(注解)——相关信息、解释说明和对其它资料的引用等等。一般都非常简短。
额外的故事字段, 有时为了便于产品负责人判断优先级别,我们也会在产品 backlog中使用一些其它字段。
Track(类别)——当前故事的大致分类,例如“后台系统” 或“优化”。这样产品负责人就可以很容易选出所有的“优化”条目,把它们的级别都设得比较低。类似的操作执行起来都很方便。
Components(组件)——通常在 Excel 文档中用“复选框”实现,例如“数据库,服务器,客户端”。团队或者产品负责人可以在这里进行标识,以明确哪些技术组件在这个故事的实现中会被包含进来。这种做法在多个 Scrum 团队协作的时候很有用——比如一个后台系统团队和一个客户端团队——他们很容易知道自己应当对哪些故事负责。
Requestor(请求者)——产品负责人可能需要记录是哪个客户或相关干系人最先提出了这项需求,在后续开发过程 中向他提供反馈。
Bug tracking ID(Bug 跟踪 ID)——如果你有个 bug 跟踪系统,就像我们用的 Jira 一样,那么了解一下故事与 bug 之间的直接联系就会对你很有帮助。
通常我们会把 backlog 存放在共享的 Excel 文档里面(是为了多个用户可以同时编辑它)。虽然正规意义上这个文档应该归产品负责人所有,但是我们并不想把其他用户排斥在外。开发人员常常要打开这个文档,弄清一些事情,或者修改估算值。
基于同样原因,我们没有把这个文档放到版本控制仓库上,而是放到共享的驱动器里面。我们发现,要想保证多用户同时编辑而不会导致锁操作或是合并冲突,这是最简单的方式。
但是基本上其它所有的制品都放在了版本控制仓库中。
在 sprint 计划会议之前,要确保产品 backlog 的井然有序 。
但这到底是什么意思?所有的故事都必须定义得完美无缺?所有的估算都必须正确无误?所有的先后次序都必须固定不变?不,不,绝不是这样!它表示的意思是:
产品 backlog 必须存在(你能想象到这一点么?)。
只能有一个产品 backlog 和一个产品负责人(对于一个产品而言)。
所有重要的 backlog 条目都已经根据重要性被评过分,不同的重要程度对应不同的分数。
o 其实,重要程度比较低的 backlog 条目,评分相同也没关系,因为它们在这次 sprint 计划会议上可能根本不会被提出来。
o 无论任何故事, 只要产品负责人相信它会在下一个sprint 实现,那它就应该被划分到一个特有的重要性层次。
o 分数只是用来根据重要性对 backlog 条目排序。假如 A 的分数是 20,而 B 的分数是 100,那仅仅是说明 B 比 A 重要而已,绝不意味着 B 比 A 重要五倍。如果 B 的分数是 21 而不是 100,含义也是一样的!
o 最好在分数之间留出适当间隔, 以防后面出现一个C,比 A 重要而不如 B 重要。当然我们也可以给 C打一个 20.5 分,但这样看上去就很难看了,所以我们还是留出间隔来!
产品负责人应当理解每个故事的含义(通常故事都是由他来编写的,但是有的时候其他人也会添加一些请求,产品 负责人对它们划分先后次序)。他不需要知道每个故事具体是如何实现的,但是他要知道为什么这个故事会在这里。
Sprint 计划会议会产生一些实实在在的成果:
sprint 目标。
团队成员名单(以及他们的投入程度,如果不是 100%的 话)。
sprint backlog(即 sprint 中包括的故事列表)。
确定好 sprint 演示日期。
确定好时间地点,供举行每日 scrum 会议。
5.1 为什么产品负责人必须参加
有时候产品负责人会不太情愿跟团队一起花上几个小时制定 sprint计划。“嘿,小伙子们,我想要的东西已经列下来了,我没时间参加你们的计划会议。”这可是个非常严重的问题。
___________Scope ____ ___estimate________importance
范围(scope)和重要性(importance)由产品负责人设置。估算(estimate)由团队设置。在 sprint 计划会议上,经过团队和产品负责人面对面的对话,这三个变量会逐步得到调整优化。
会议启动以后,产品负责人一般会先概括一下希望在这个 sprint 中达成的目标,还有他认为最重要的故事。接下来,团队从最重要的故事开始逐一讨论每个故事,一一估算时间。在这个过程中,他们会针对范围提出些重要问题:“‘删除用户’这个故事,需不需要遍历这个用户所有尚未执行的事务,把它们统统取消?”有时答复会让他们感到惊讶,促使他们调整估算。
在某些情况下,团队对故事做出的时间估算,跟产品负责人的想法不太一样。这可能会让他调整故事的重要性; 或者修改故事的范围,导致团队重新估算,然后一连串诸如此类的后续反应。
这种直接的协作形式是 Scrum 的基础,也是所有敏捷软件开发的基础。
在上面的三角形中(时间,范围,成本/人力资源),我有意忽略了第四个变量——质量。
我尽力把内部质量和外部质量分开。
外部质量是系统用户可以感知的。运行缓慢、让人迷糊的用户界面就属于外部质量低劣。
内部质量一般指用户看不到的要素,它们对系统的可维护性有深远影响。可维护性包括系统设计的一致性、测试覆 盖率、代码可读性和重构等等。
在 sprint 计划会议之前先为它初步制定一个时间表,可以减少打破时间盒的风险。
下面来看一下我们用到的一个典型的时间表。
Sprint 计划会议:13:00 – 17:00 (每小时休息 10 分钟)
• 13:00 – 13:30。产品负责人对 sprint 目标进行总体介绍,概 括产品 backlog。定下演示的时间地点。
• 13:30 – 15:00。 团队估算时间, 在必要的情况下拆分 backlog条目。产品负责人在必要时修改重要性评分。理清每个条目的含义。所有重要性高的 backlog 条目都要填写“如何演示”。
• 15:00 – 16:00。团队选择要放入 sprint 中的故事。计算生产率,用作核查工作安排的基础。
• 16:00 – 17:00。为每日 scrum 会议(以下简称每日例会)安排固定的时间地点(如果和上次不同的话)。把故事进一步拆分成任务。
这个日程绝不是强制执行的。Scrum master 根据会议进程的需要,可以对各个阶段的子进程时间安排进行调整。
5.4 确定 sprint 长度
Sprint 演示日期是 sprint 计划会议的产出物,它被确定下来以后,也就确定了 sprint 的长度。
嗯,时间短就好。公司会因此而变得“敏捷”,有利于随机应变。短的 sprint=短反馈周期=更频繁的交付=更频繁的客户反馈=在错误方向上花的时间更少=学习和改进的速度更快,众多好处接踵而来。
但是,时间长的 sprint 也不错。团队可以有更多时间充分准备、解决发生的问题、 继续达成 sprint 目标,你也不会被接二连三的 sprint计划会议、演示等等压得不堪重负。
产品负责人一般会喜欢短一点的sprint,而开发人员喜欢时间长的sprint。所以sprint的长度是妥协后的产物。做过多次实验后,我们最终总结出了最喜欢的长度: 三个星期 。
5.5 决定 sprint 要包含的故事
决定哪些故事需要在这个 sprint 中完成,是 sprint 计划会议的一个主要活动。
4.6 我们为何使用索引卡
在大多数 sprint 计划会议上,大家都会讨论产品 backlog 中的故事细节。对故事进行估算、重定优先级、进一步确认细节、拆分,等等都会在会议上完成。
要想收到好的效果,不妨创建一些索引卡,把它们放到墙上(或一张大桌子上)。
这种用户体验比计算机和投影仪好得多。原因是:
大家站起来四处走动=> 他们可以更长时间地保持清醒,并留心会议进展。
他们有更多的个人参与感(而不是只有那个拿着键盘的家伙才有)。
多个故事可以同时编辑。
重新划分优先级变得易如反掌——挪动索引卡就行。
会议结束后,索引卡可以拿出会议室,贴在墙上的任务板上(参见第“我们怎样编写 sprint backlogs”)。
5.7 使用计划纸牌做时间估算
估算是一项团队活动——通常每个成员都会参与所有故事的估算。为啥要每个人都参加?
在计划的时候,我们一般都还不知道到底谁会来实现哪个故事的哪个部分。
每个故事一般有好几个人参与,也包括不同类型的专长 (用户界面设计、编程、测试、等等)。
团队成员必须要对故事内容有一定的理解才能进行估算。要求每个人都做估算,我们就可以确保他们都理解了每个条目的内容。这样就为大家在 sprint 中相互帮助夯实了基础,也有助于故事中的重要问题被尽早发现
如果要求每个人都对故事做估算,我们就会常常发现两个人对同一个故事的估算结果差异很大。我们应该尽早发现这种问题并就此进行讨论。
如果让整个团队进行估算, 通常那个对故事理解最透彻的人会第一个发言。不幸的是,这会严重影响其他人的估算。
有一项很优秀的技术可以避免这一点——它的名字是计划纸牌 (我记得是 Mike Cohn 创造出来这个名字的)。
0, 1/2, 1, 2, 3, 5, 8, 13, 20, 40, 100, ?, 咖啡杯
每个人都会得到如上图所示的 13 张卡片。在估算故事的时候,每个人都选出一张卡片来表示他的时间估算 (以故事点的方式表示),并把它正面朝下扣在桌上。所有人都完成以后,桌上的纸牌会被同时揭开。这样每个人都会被迫进行自我思考,而不是依赖于其他人估算的结果。
如果在两个估算之间有着巨大差异,团队就会就此进行讨论,并试图让大家对故事内容达成共识。他们也许会进行任务分解,之后再重新估算。这样的循环会往复进行,直到时间估算趋于一致为止,也就是每个人对这个故事的估算都差不多相同。
重要的是,我们必须提醒团队成员,他们要对这个故事中所包含的全部工作进行估算。而不是“他们自己负责”的部分工作。测试人员不能只估算测试工作。
注意,这里的数字顺序不是线性的。例如在 40 和 100 之间就没有数字。为什么这样?
这是因为,一旦时间的估算值比较大,其精确度就很难把握;这样做就可以避免人们对估算精确度产生错误的印象。 如果一个故事的估算值是差不多 20 个故事点,它到底应该是 20 还是 18 还是 21,其实无关紧要。我们知道的就是它是一个很大的故事,很难估算。所以 20 只是一个粗略估计。
另外,你也不能搞那种把 5 和 2 加起来得到 7 的把戏。要么选 5,要么选 8,没有 7。
有些卡片比较特殊:
0 = “这个故事已经完成了”或者“这个故事根本没啥东西,几分钟就能搞定”。
? = “我一点概念都没有。没想法。”
咖啡杯 = “我太累了,先歇会吧。”
5.8 把故事拆分成任务
等一下。“任务”和“故事”的区别是什么呢?嗯,这个问题问得不错。
区别很简单。故事是可以交付的东西,是产品负责人所关心的。任务是不可交付的东西,产品负责人对它也不关心。
Query users:[this user story will be split 7 tasks]
clarify requirements
write test case
design GUI
Find reporting tool & do spike
implement the user list
integration test, debug, refactor
implement the query format
我们会看到一些很有趣的现象:
• 新组建的 Scrum 团队不愿意花时间来预先把故事拆分成任务。有些人觉得这像是瀑布式的做法。
• 有些故事,大家都理解得很清楚,那么预先拆分还是随后拆分都一样简单。
• 这种类型的拆分常常可以发现一些会导致时间估算增加的工作,最后得出的 sprint 计划会更贴近现实。
• 这种预先拆分可以给每日例会的效率带来显著提高(参见“我们怎样进行每日例会”)。
• 即使拆分不够精确,而且一旦开始具体工作,事先的拆分结果也许会发生变化,但我们依然可以得到以上种种好处。
注意——我们在实践 TDD(测试驱动开发) ,所以几乎每个故事的 第一个任务都是“编写一个失败的测试 ” 而 最后一个任务是“重构” (提高代码的可读性,消除重复)。
5.9 定下每日例会的时间地点
Sprint 计划会议有一个产物常常被人们忽略: “确定的时间和地点, 以供举办每日例会”。 没有这一点,你的 sprint 就会有个“开门黑”。实际上,每个人都是在当前 sprint 的第一个每日例会上决定怎样开始工作。
我们的默认做法是选一个大家都不会有异议的最早时间。一般是9:00,9:30 或者 10:00。最关键的是,这必须是每个人都能完全接受的时间。
5.10 最后界限在哪里
OK,现在时间已经用完了。如果时间不够的话,那么我们该把哪些本该做的事情砍掉呢?
嗯,我总是用下面这个优先级列表:
优先级 1: sprint 目标和演示日期。这是启动 sprint 最起码应该有的东西。团队有一个目标,一个结束日期,然后就可以马上根据产品backlog 开始工作。没错,这是不像话,你应该认真考虑一下明天再开个新的 sprint 计划会议。不过如果确实需要马上启动 sprint,不妨先这么着吧。认真说来,只有这么点儿信息就开始 sprint,我还从来没有试过。
优先级 2:经过团队认可、要添加到这个 sprint 中的故事列表。
优先级 3:Sprint 中每个故事的估算值。
优先级 4:Sprint 中每个故事的“如何演示”。
优先级 5:生产率和资源计算,用作 sprint 计划的现实核查。包括团队成员的名单及每个人的承诺(不然就没法计算生产率)。
优先级 6:明确每日例会固定举行的时间地点。这只需要花几分钟,但如果时间不够用,Scrum master 可以在会后直接定下来,邮件通知所有人。
优先级 7:把故事拆分成任务。这个拆分也可以在每日例会上做,不过这会稍稍打乱 sprint 的流程。
5.11 技术故事
这有个很复杂的问题:技术故事。或者叫做非功能性条目,或者你想叫它什么都行。
我指的是需要完成但又不属于可交付物的东西,跟任何故事都没有直接关联,不会给产品负责人带来直接的价值。
我们把它叫做“技术故事”。
例如:
安装持续构建服务器
o 为什么要完成它:因为它会节省开发人员的大量时间,到迭代结束的时候,集成也不太容易出现重大问题。
编写系统设计概览
o 为什么要完成它:因为开发人员常常会忘记系统的整体设计,写出与之不一致的代码。团队需要有个描述整体概况的文档, 保证每个人对设计都有同样的理解。
重构 DAO 层
o 为什么要完成它:因为 DAO 层代码已经乱成一团了。混乱带来了本可以避免的 bug,每个人的时间都在被无谓的消耗。清理代码可以节省大家的时间,提高系统的健壮性。
升级 Jira (bug 跟踪工具)
o 为什么要完成它:当前的版本 bug 狂多,又很慢, 升级以后可以节省大家时间。
所以我们采取了下面这些做法:
1) 试着避免技术故事。努力找到一种方式,把技术故事变成可以衡量业务价值的普通故事。这样有助于产品负责人做出正确的权衡。
2) 如果无法把技术故事转变成普通故事,那就看看这项工作能不能当作另一个故事中的某个任务。例如,“重构 DAO 层”可以作为“编辑用户”中的一个任务,因为这个故事会涉及到 DAO 层。
3) 如果以上二者都不管用,那就把它定义为一个技术故事,用另外一个单独的列表来存放。产品负责人能看到它,但是不能编辑它。用“投入程度”和“预估生产率”这两个参数来跟产品负责人协商,从 sprint 里拨出一些时间来完成这些技术故事。
6, 我们怎样让别人了解我们的 sprint
我们要让整个公司了解我们在做些什么,这件事情至关重要。否则其他人就会发出抱怨,甚或对我们的工作做出臆断。
我们为此使用“sprint 信息页”。
我们在 wiki 上还有个“dashboard”页面, 链向所有正在进行的 sprint。
7, 我们怎样编写 sprint backlog
任务板
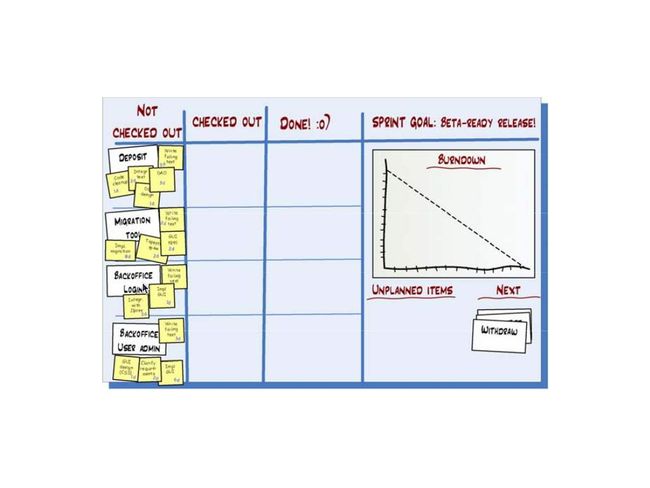
你当然也可以用白板。不过那多少有点浪费。可能的话,还是把白板省下来画设计草图,用没有挂白板的墙做任务板。
注意——如果你用贴纸来记录任务,别忘了用真正的胶带把它们粘好,否则有一天你会发现所有的贴纸都在地上堆成一堆。
8, 我们怎样进行 sprint 演示
Sprint 演示(有人也叫它 sprint 回顾)是 Scrum 中很重要的一环,却常为人们低估。
“哦,我们真的必须做演示么?没啥好东西能展示的!”
“我们没时间准备&%$#的演示!”
“我没时间参加其他团队的演示!”
8.1 为什么我们坚持所有的 sprint 都结束于演示
一次做得不错的演示,即使看上去很一般,也会带来深远影响。
团队的成果得到认可。他们会感觉很好。
其他人可以了解你的团队在做些什么。
演示可以吸引相关干系人的注意,并得到重要反馈。
演示是(或者说应该是)一种社会活动,不同的团队可以在这里相互交流,讨论各自的工作。这很有意义。
做演示会迫使团队真正完成一些工作,进行发布(即使是只在测试环境中)。如果没有演示,我们就会总是得到些99%完成的工作。有了演示以后,也许我们完成的事情会变少,但它们是真正完成的。这(在我们的案例中)比得到一堆貌似完成的工作要好得多,而且后者还会污染下一个 sprint。
8.2 Sprint 演示检查列表
确保清晰阐述了 sprint 目标。如果在演示上有些人对产品一无所知,那就花上几分钟来进行描述。
不要花太多时间准备演示,尤其是不要做花里胡哨的演讲。把那些玩意儿扔一边去,集中精力演示可以实际工作的代码。
节奏要快,也就是说要把准备的精力放在保持演示的快节奏上,而不是让它看上去好看。
让演示关注于业务层次, 不要管技术细节。注意力放在“我们做了什么”,而不是“我们怎么做的”。
可能的话,让观众自己试一下产品。
• 不要演示一大堆细碎的 bug 修复和微不足道的特性。你可以提到一些,但是不要演示,因为它们通常会花很长时间, 而且会分散大家的注意力,让他们不能关注更加重要的故事。
9, 我们怎样做 sprint 回顾
9.1 为什么我们坚持所有的团队都要做回顾
由于某些原因,团队常常都不太愿意做回顾。如果不给他们点温柔的刺激,我们的大多数团队都会跳过回顾,直接进行下一个 sprint。也许这只是瑞典的文化,我不太确定。
不过,看起来每个人都觉得回顾的用途极大。说句实话,我认为 回顾[retrospective]是 Scrum 中第二重要的事件 (最重要的是 sprint 计划会议),因为这是你做改进的最佳时机!
如果没有回顾,你就会发现团队在不断重犯同样的错误。
9.2 我们如何组织回顾
• 根据要讨论的内容范围,设定时间为 1 至 3 个小时。
• 参与者:产品负责人,整个团队还有我自己。
• 我们换到一个封闭的房间中,或者舒适的沙发角,或者屋顶平台等等类似的场所。只要能够在不受干扰的情况下讨论就好。
• 我们一般不会在团队房间中进行回顾,因为这往往会分散大家的注意力。
• 指定某人当秘书。
• Scrum master 向大家展示 sprint backlog, 在团队的帮助下对sprint 做总结。包括重要事件和决策等。
• 我们会轮流发言。每个人都有机会在不被人打断的情况下讲出自己的想法,他认为什么是好的,哪些可以做的更好,哪些需要在下个 sprint 中改变。
• 我们对预估生产率和实际生产率进行比较。如果差异比较大的话,我们会分析原因。
• 快结束的时候,Scrum master 对具体建议进行总结,得出下个 sprint 需要改进的地方。
三列分别是:
Good:如果我们可以重做同一个 sprint,哪些做法可以保 持。
Could have done better:如果我们可以重做同一个 sprint, 哪些做法需要改变。
Improvements:有关将来如何改进的具体想法。
第一列和第二列是回顾过去,第三列是展望将来。
团队通过头脑风暴得出所有的想法,写在即时贴上,然后用“圆点投票”来决定下一个 sprint 会着重进行哪些改进。每个人都有三块小磁铁,投票决定下个 sprint 所要采取措施的优先级。他们可以随意投票,也可以把全部三票投在一件事情上。
根据投票情况,他们选出了 5 项要重点进行的过程改进,在下一个回顾中,他们会跟踪这些改进的执行情况。不过不要想一口吃成个胖子,这一点很重要。每个 sprint 只关注几个改进就够了。
9.3 在团队间传播经验
Sprint 回顾不只关注团队怎样才能在下个 sprint 中做得更好,它有更广袤的含义。
我们的处理策略比较简单。有一个人(我们这儿是我)会参加所有的 sprint 回顾会议,充当知识桥梁。不用太正二八经。
另一种方式,是让每个 Scrum 团队都发布 sprint 回顾报告。我们试过这么做,但发现很多人都不会去读报告,而就此展开改进的就更少了。所以我们还是用了上面那种简单的方式。
充当“知识桥梁“的人需要服从一些重要规则:
他应当是一个很好的倾听者。
如果回顾会议过于沉寂,他应该问一些简单而目标明确的问题,以刺激团队展开讨论。例如“如果时间可以倒流,从第一天重新开始这个 sprint,那你觉得哪些事情会用其它方式来做?”
他应该自愿花时间参加所有团队的全部回顾。
他应该有一定的行政权力,如果出现一些团队无法控制的改进建议,他可以帮助推进实施。
10, 我们怎样组合使用 Scrum 和 XP
要说组合使用 Scrum 和 XP(极限编程)可以带来累累硕果,这毫无争议。我在网上看到过的绝大多数资料都证实了这一点,所以我不会花时间去讨论为什么要这么做。
不过,我还是会提到一点。 Scrum 注重的是管理和组织实践 ,而 XP 关注的是实际的编程实践 。这就是为什么它们可以很好地协同工作——它们解决的是不同领域的问题, 可以互为补充,相得益彰。
10.1 XP 中最有价值的一些实践
结对编程
测试驱动开发(TDD)
持续集成
代码集体所有权
充满信息的工作空间
代码标准
10.2 结对编程
有关结对编程的一些结论:
结对编程可以提高代码质量。
结对编程可以让团队的精力更加集中(比如坐在你后面的那个人会提醒你,“嘿,这个东西真的是这个 sprint 必需的吗?”)。
令人惊奇的是,很多强烈抵制结对编程的开发人员根本就没有尝试过,而一旦尝试之后就会迅速喜欢上它。
结对编程令人精疲力竭,不能全天都这样做。
常常更换结对是有好处的。
结对编程可以增进团队间的知识传播。速度快到令人难以想象。
有些人就是不习惯结对编程。不要因为一个优秀的开发人员不习惯结对编程就把他置之不理。
可以把代码审查作为结对编程的替代方案。
“领航员”(不用键盘的家伙)应该自己也有一台机器。不是用来开发,而是在需要的时候稍稍做一些探索尝试、当“司机”(使用键盘的家伙)、遇到难题的时候查看文档,等等。
不要强制大家使用结对编程。鼓励他们,提供合适的工具,让他们按照自己的节奏去尝试。
10.3 测试驱动开发(TDD)
有关 TDD 的一个 10 秒钟总结:
测试驱动开发意味着你要先写一个自动测试 , 然后 编写恰好够用的代码 ,让它通过这个测试,接着 对代码进行重构 ,主要是提高它的可读性和消除重复。整理一下,然后继续。
人们对测试驱动开发有着各种看法:
TDD 很难。开发人员需要花上一定时间才能掌握。 实际上,往往问题并不在于你用了多少精力去教学、辅导和演示——多数情况下,开发人员掌握它的唯一方式就是跟一个熟悉 TDD 的人一起结对编程,一旦掌握以后,他就会受到彻
底的影响,从此再也不想使用其它方式工作。
TDD 对系统设计的正面影响特别大。
在新产品中,需要过上一段时间,TDD 才能开始应用并有效运行,尤其是黑盒集成测试。但是回报来得非常快。
投入足够的时间,来保证大家可以很容易地编写测试。这味着要有合适的工具、有经验的人、提供合适的工具类或基类,等等。
我们在测试驱动开发中使用了如下工具:
jUnit / httpUnit / jWebUnit。我们正在考虑使用 TestNG 和 Selenium.
HSQLDB 用作嵌入式的内存数据库,在测试中使用。
Jetty 用作嵌入式的内存 Web 容器,在测试中使用。
Cobertura 用来度量测试覆盖率。
Spring 框架用来织入不同类型的测试装置(带有 mock、不带 mock、带有外部数据库或带有内存数据库等等)。
它会把 开发-构建-测试这三者构成的循环变得奇快无比 ,同时还可以充当一张安全网,让开发人员有足够的信心频繁重构,伴随着系统的增长,设计依然可以保持整洁和简单。
10.4 持续集成
我们的大多数产品在持续集成方面都已经很成熟了,它们是基于Maven 和 QuickBuild 的。这样做很管用,而且节省了我们大量时间。 对于 “哎,它在我的电脑上没有问题”这样的老问题,持续集成也是终极解决方案。要判断所有代码库的健康状况,可以用持续构建服务器充当“法官”或是参考点。每次有人向版本控制系统中 check in 东西,持续构建服务器就会醒来,在一个共享服务器上从头构建一切,运行所有测试。如果出现问题,它就会向整个团队发送邮件告知大家构建失败, 在邮件中会包括有哪些代码的变化导致构建失败的精确细节,指向测试报告的链接等。
每天晚上,持续构建服务器都会从头构建产品,并且向我们的内部文档门户上发布二进制文件(ears,wars 等)、文档、测试报告、测试覆盖率报告和依赖性分析报告等等。 有些产品也会被自动部署到测试环境中。
把这一切搭建起来需要大量工作,但付出的每一分钟都物有所值。
10.5 代码集体所有权
我们鼓励代码集体所有权,但并不是所有团队都采取了这种方式。我们发现:在结对编程中频繁交换结对,会自动把代码集体所有权提到一个很高的级别。我们已经证实,如果团队拥有高度的代码集体所有权,这个团队就会非常健壮,比如某些关键人物生病了,当前的 sprint 也不会因此嗝屁朝凉。
10.6 充满信息的工作空间
所有团队都可以有效利用白板和空的墙壁空间。很多房间的墙上都贴满了各种各样关于产品和项目的信息。这样做最大的问题,就是那些旧的作废信息也堆在墙上,也许我们应该在每个团队中引入一个“管家”的角色。
10.7 代码标准
不久前我们开始定义代码标准。它的用处很大,要是我们早就这样做就好了。引入代码标准几乎没花多少时间,我们只是一开始从简单入手,让它慢慢增长。只需要写下不是所有人都了如指掌的事情,并尽可能加上对外部资料的链接。
绝大多数程序员都有他们自己特定的编程风格。 例如他们如何处理异常,如何注释代码,何时返回 null 等等。有时候这种差异没什么关系,但在某些情况下,系统设计就会因此出现不一致的现象,情况严重,代码也不容易看懂。这时代码标准的用处就会凸显,从造成影响的因素中就可以知道了。
我们代码标准中的一些例子:
你可以打破这里的任一规则,不过一定要有个好理由,并且记录下来。
默 认 使 用 Sun 的 代 码 惯 例 :http://java.sun.com/docs/codeconv/html/CodeConvTOC.doc.html
永远,永远,永远不要在没有记录堆栈跟踪信息(stack或是重新抛出异常的情况下捕获异常。 log.debug() 用
trace)也不错,只要别丢失堆栈跟踪信息就行。
使用基于 setter 方法的依赖注入来将类与类解耦 (当然, 如果紧耦合可以令人满意的话就另当别论)。
避免缩写。为人熟知的缩写则可以,例如 DAO。
需要返回 Collections 或者数组的方法不应该返回 null。应该返回空的容器或数组,而不是 null。
10.8 可持续的开发速度/精力充沛的工作
很多有关敏捷软件开发的书都声称:加班工作在软件开发中会降低生产率。
经过几次不情愿的试验之后,我完全拥护这种说法
孙子兵法有云:兵无常势,水无常形,能因敌变化而取胜者谓之神。很多人都向往用兵如神的境界,想必也知道读万卷书不如行万里路,纸上谈兵的故事更是耳熟能详;但偏偏不能举一反三。
且看风清扬的一段话:“......你将这华山派的三四十招融合贯通,设想如何一气呵成,然后全部将它忘了,忘得干干净净,一招也不可留在心中。待会便以甚么招数也没有的华山剑法,去跟田伯光对打”。如果有人说,既然“无招胜有招”是武学的最高境界,那干脆什么招数都不要学,拿把剑乱挥乱舞,处处破绽,也就处处无破绽,便是天下第一了。听到这话的人肯定会笑他太缺心眼。
根据 Nokia 标准来做迭代开发。迭代开发是敏捷宣言的基本原则——在早期频繁的交付可工作的软件。
Nokia 用了几年时间,对上百个 Scrum 团队的工作进行了回顾,总结出了迭代开发的基本需求:
迭代要有固定时长(被称为“时间盒——timebox”),不能超过六个星期。
在每一次迭代的结尾,代码都必须经过 QA 的测试,能够正常工作。
Nokia 的 Scrum标准:
Scrum 团队必须要有产品负责人,而且团队都清楚这个人是谁。
产品负责人必须要有产品 Backlog,其中包括团队对它进行的估算。
团队必须要有燃尽图,而且要了解他们自己的生产率。
在一个 Sprint 中,外人不能干涉团队的工作。
scrum拥有如下产物:
产品 Backlog、对于这个 Backlog 的估算、燃尽图;
你会了解团队的生产率,
并掌握在切实有效的 Scrum 过程中所包含的众多基础实践。
用Ken Schwaber的话说,Scrum不是方法学,它是一个框架。也就是说Scrum不会告诉你到底该做些什么。
XP 实践——各种各样的每日构建,结对编程,测试驱动开发,等等;
产品 backlog 是 Scrum 的核心,也是一切的起源。从根本上说,它就是一个需求、或故事、或特性等组成的列表,按照重要性的级别进行了排序。它里面包含的是客户想要的东西,并用客户的术语加以描述。
我们叫它故事(story),有时候也叫做 backlog 条目。
ID——统一标识符,就是个自增长的数字而已。以防重命名故事以后找不到它们。
Name(名称)——简短的、描述性的故事名。比如“查看你自己的交易明细”。它必须要含义明确,这样开发人员和产品负责人才能大致明白我们说的是什么东西,跟其他故事区分开。它一般由 2 到 10 个字组成。
Importance(重要性)——产品负责人评出一个数值,指示这个故事有多重要。例如 10 或 150。分数越高越重要。
o 我一直都想避免“优先级”这个说法,因为一般说 来优先级 1 都表示“最高”优先级,如果后来有其他更重要的东西就麻烦了。 它的优先级评级应该是什么呢?优先级 0?优先级-1?
Initial estimate(初始估算)——团队的初步估算,表示与其他故事相比,完成该故事所需的工作量。最小的单位是故事点(story point),一般大致相当于一个“理想的人天(man-day)”。
o 问一下你的团队, “如果可以投入最适合的人员来完成这个故事(人数要适中,通常为 2 个),把你们锁到一个屋子里,有很多食物,在完全没有打扰的情况下工作,那么需要几天,才能给出一个经过测试验证,可以交付的完整实现呢?”如果答案是“把 3 个人关在一起,大约需要 4 天时间”,那么初始估算的结果就是 12 个故事点。
o 不需要保证这个估值绝对无误 (比如两个故事点的故事就应该花两天时间),而是要保证相对的正确性(即,两个点的故事所花费的时间应该是四个点的故事所需的一半)
How to demo (如何做演示)——它大略描述了这个故事应该如何在 sprint 演示上进行示范,本质就是一个简单的测 试规范。“先这样做,然后那样做,就应该得到......的结果 ”。
o 如果你在使用 TDD(测试驱动开发),那么这段描述就可以作为验收测试的伪码表示。
Notes(注解)——相关信息、解释说明和对其它资料的引用等等。一般都非常简短。
额外的故事字段, 有时为了便于产品负责人判断优先级别,我们也会在产品 backlog中使用一些其它字段。
Track(类别)——当前故事的大致分类,例如“后台系统” 或“优化”。这样产品负责人就可以很容易选出所有的“优化”条目,把它们的级别都设得比较低。类似的操作执行起来都很方便。
Components(组件)——通常在 Excel 文档中用“复选框”实现,例如“数据库,服务器,客户端”。团队或者产品负责人可以在这里进行标识,以明确哪些技术组件在这个故事的实现中会被包含进来。这种做法在多个 Scrum 团队协作的时候很有用——比如一个后台系统团队和一个客户端团队——他们很容易知道自己应当对哪些故事负责。
Requestor(请求者)——产品负责人可能需要记录是哪个客户或相关干系人最先提出了这项需求,在后续开发过程 中向他提供反馈。
Bug tracking ID(Bug 跟踪 ID)——如果你有个 bug 跟踪系统,就像我们用的 Jira 一样,那么了解一下故事与 bug 之间的直接联系就会对你很有帮助。
通常我们会把 backlog 存放在共享的 Excel 文档里面(是为了多个用户可以同时编辑它)。虽然正规意义上这个文档应该归产品负责人所有,但是我们并不想把其他用户排斥在外。开发人员常常要打开这个文档,弄清一些事情,或者修改估算值。
基于同样原因,我们没有把这个文档放到版本控制仓库上,而是放到共享的驱动器里面。我们发现,要想保证多用户同时编辑而不会导致锁操作或是合并冲突,这是最简单的方式。
但是基本上其它所有的制品都放在了版本控制仓库中。
在 sprint 计划会议之前,要确保产品 backlog 的井然有序 。
但这到底是什么意思?所有的故事都必须定义得完美无缺?所有的估算都必须正确无误?所有的先后次序都必须固定不变?不,不,绝不是这样!它表示的意思是:
产品 backlog 必须存在(你能想象到这一点么?)。
只能有一个产品 backlog 和一个产品负责人(对于一个产品而言)。
所有重要的 backlog 条目都已经根据重要性被评过分,不同的重要程度对应不同的分数。
o 其实,重要程度比较低的 backlog 条目,评分相同也没关系,因为它们在这次 sprint 计划会议上可能根本不会被提出来。
o 无论任何故事, 只要产品负责人相信它会在下一个sprint 实现,那它就应该被划分到一个特有的重要性层次。
o 分数只是用来根据重要性对 backlog 条目排序。假如 A 的分数是 20,而 B 的分数是 100,那仅仅是说明 B 比 A 重要而已,绝不意味着 B 比 A 重要五倍。如果 B 的分数是 21 而不是 100,含义也是一样的!
o 最好在分数之间留出适当间隔, 以防后面出现一个C,比 A 重要而不如 B 重要。当然我们也可以给 C打一个 20.5 分,但这样看上去就很难看了,所以我们还是留出间隔来!
产品负责人应当理解每个故事的含义(通常故事都是由他来编写的,但是有的时候其他人也会添加一些请求,产品 负责人对它们划分先后次序)。他不需要知道每个故事具体是如何实现的,但是他要知道为什么这个故事会在这里。
Sprint 计划会议会产生一些实实在在的成果:
sprint 目标。
团队成员名单(以及他们的投入程度,如果不是 100%的 话)。
sprint backlog(即 sprint 中包括的故事列表)。
确定好 sprint 演示日期。
确定好时间地点,供举行每日 scrum 会议。
5.1 为什么产品负责人必须参加
有时候产品负责人会不太情愿跟团队一起花上几个小时制定 sprint计划。“嘿,小伙子们,我想要的东西已经列下来了,我没时间参加你们的计划会议。”这可是个非常严重的问题。
___________Scope ____ ___estimate________importance
范围(scope)和重要性(importance)由产品负责人设置。估算(estimate)由团队设置。在 sprint 计划会议上,经过团队和产品负责人面对面的对话,这三个变量会逐步得到调整优化。
会议启动以后,产品负责人一般会先概括一下希望在这个 sprint 中达成的目标,还有他认为最重要的故事。接下来,团队从最重要的故事开始逐一讨论每个故事,一一估算时间。在这个过程中,他们会针对范围提出些重要问题:“‘删除用户’这个故事,需不需要遍历这个用户所有尚未执行的事务,把它们统统取消?”有时答复会让他们感到惊讶,促使他们调整估算。
在某些情况下,团队对故事做出的时间估算,跟产品负责人的想法不太一样。这可能会让他调整故事的重要性; 或者修改故事的范围,导致团队重新估算,然后一连串诸如此类的后续反应。
这种直接的协作形式是 Scrum 的基础,也是所有敏捷软件开发的基础。
在上面的三角形中(时间,范围,成本/人力资源),我有意忽略了第四个变量——质量。
我尽力把内部质量和外部质量分开。
外部质量是系统用户可以感知的。运行缓慢、让人迷糊的用户界面就属于外部质量低劣。
内部质量一般指用户看不到的要素,它们对系统的可维护性有深远影响。可维护性包括系统设计的一致性、测试覆 盖率、代码可读性和重构等等。
在 sprint 计划会议之前先为它初步制定一个时间表,可以减少打破时间盒的风险。
下面来看一下我们用到的一个典型的时间表。
Sprint 计划会议:13:00 – 17:00 (每小时休息 10 分钟)
• 13:00 – 13:30。产品负责人对 sprint 目标进行总体介绍,概 括产品 backlog。定下演示的时间地点。
• 13:30 – 15:00。 团队估算时间, 在必要的情况下拆分 backlog条目。产品负责人在必要时修改重要性评分。理清每个条目的含义。所有重要性高的 backlog 条目都要填写“如何演示”。
• 15:00 – 16:00。团队选择要放入 sprint 中的故事。计算生产率,用作核查工作安排的基础。
• 16:00 – 17:00。为每日 scrum 会议(以下简称每日例会)安排固定的时间地点(如果和上次不同的话)。把故事进一步拆分成任务。
这个日程绝不是强制执行的。Scrum master 根据会议进程的需要,可以对各个阶段的子进程时间安排进行调整。
5.4 确定 sprint 长度
Sprint 演示日期是 sprint 计划会议的产出物,它被确定下来以后,也就确定了 sprint 的长度。
嗯,时间短就好。公司会因此而变得“敏捷”,有利于随机应变。短的 sprint=短反馈周期=更频繁的交付=更频繁的客户反馈=在错误方向上花的时间更少=学习和改进的速度更快,众多好处接踵而来。
但是,时间长的 sprint 也不错。团队可以有更多时间充分准备、解决发生的问题、 继续达成 sprint 目标,你也不会被接二连三的 sprint计划会议、演示等等压得不堪重负。
产品负责人一般会喜欢短一点的sprint,而开发人员喜欢时间长的sprint。所以sprint的长度是妥协后的产物。做过多次实验后,我们最终总结出了最喜欢的长度: 三个星期 。
5.5 决定 sprint 要包含的故事
决定哪些故事需要在这个 sprint 中完成,是 sprint 计划会议的一个主要活动。
4.6 我们为何使用索引卡
在大多数 sprint 计划会议上,大家都会讨论产品 backlog 中的故事细节。对故事进行估算、重定优先级、进一步确认细节、拆分,等等都会在会议上完成。
要想收到好的效果,不妨创建一些索引卡,把它们放到墙上(或一张大桌子上)。
这种用户体验比计算机和投影仪好得多。原因是:
大家站起来四处走动=> 他们可以更长时间地保持清醒,并留心会议进展。
他们有更多的个人参与感(而不是只有那个拿着键盘的家伙才有)。
多个故事可以同时编辑。
重新划分优先级变得易如反掌——挪动索引卡就行。
会议结束后,索引卡可以拿出会议室,贴在墙上的任务板上(参见第“我们怎样编写 sprint backlogs”)。
5.7 使用计划纸牌做时间估算
估算是一项团队活动——通常每个成员都会参与所有故事的估算。为啥要每个人都参加?
在计划的时候,我们一般都还不知道到底谁会来实现哪个故事的哪个部分。
每个故事一般有好几个人参与,也包括不同类型的专长 (用户界面设计、编程、测试、等等)。
团队成员必须要对故事内容有一定的理解才能进行估算。要求每个人都做估算,我们就可以确保他们都理解了每个条目的内容。这样就为大家在 sprint 中相互帮助夯实了基础,也有助于故事中的重要问题被尽早发现
如果要求每个人都对故事做估算,我们就会常常发现两个人对同一个故事的估算结果差异很大。我们应该尽早发现这种问题并就此进行讨论。
如果让整个团队进行估算, 通常那个对故事理解最透彻的人会第一个发言。不幸的是,这会严重影响其他人的估算。
有一项很优秀的技术可以避免这一点——它的名字是计划纸牌 (我记得是 Mike Cohn 创造出来这个名字的)。
0, 1/2, 1, 2, 3, 5, 8, 13, 20, 40, 100, ?, 咖啡杯
每个人都会得到如上图所示的 13 张卡片。在估算故事的时候,每个人都选出一张卡片来表示他的时间估算 (以故事点的方式表示),并把它正面朝下扣在桌上。所有人都完成以后,桌上的纸牌会被同时揭开。这样每个人都会被迫进行自我思考,而不是依赖于其他人估算的结果。
如果在两个估算之间有着巨大差异,团队就会就此进行讨论,并试图让大家对故事内容达成共识。他们也许会进行任务分解,之后再重新估算。这样的循环会往复进行,直到时间估算趋于一致为止,也就是每个人对这个故事的估算都差不多相同。
重要的是,我们必须提醒团队成员,他们要对这个故事中所包含的全部工作进行估算。而不是“他们自己负责”的部分工作。测试人员不能只估算测试工作。
注意,这里的数字顺序不是线性的。例如在 40 和 100 之间就没有数字。为什么这样?
这是因为,一旦时间的估算值比较大,其精确度就很难把握;这样做就可以避免人们对估算精确度产生错误的印象。 如果一个故事的估算值是差不多 20 个故事点,它到底应该是 20 还是 18 还是 21,其实无关紧要。我们知道的就是它是一个很大的故事,很难估算。所以 20 只是一个粗略估计。
另外,你也不能搞那种把 5 和 2 加起来得到 7 的把戏。要么选 5,要么选 8,没有 7。
有些卡片比较特殊:
0 = “这个故事已经完成了”或者“这个故事根本没啥东西,几分钟就能搞定”。
? = “我一点概念都没有。没想法。”
咖啡杯 = “我太累了,先歇会吧。”
5.8 把故事拆分成任务
等一下。“任务”和“故事”的区别是什么呢?嗯,这个问题问得不错。
区别很简单。故事是可以交付的东西,是产品负责人所关心的。任务是不可交付的东西,产品负责人对它也不关心。
Query users:[this user story will be split 7 tasks]
clarify requirements
write test case
design GUI
Find reporting tool & do spike
implement the user list
integration test, debug, refactor
implement the query format
我们会看到一些很有趣的现象:
• 新组建的 Scrum 团队不愿意花时间来预先把故事拆分成任务。有些人觉得这像是瀑布式的做法。
• 有些故事,大家都理解得很清楚,那么预先拆分还是随后拆分都一样简单。
• 这种类型的拆分常常可以发现一些会导致时间估算增加的工作,最后得出的 sprint 计划会更贴近现实。
• 这种预先拆分可以给每日例会的效率带来显著提高(参见“我们怎样进行每日例会”)。
• 即使拆分不够精确,而且一旦开始具体工作,事先的拆分结果也许会发生变化,但我们依然可以得到以上种种好处。
注意——我们在实践 TDD(测试驱动开发) ,所以几乎每个故事的 第一个任务都是“编写一个失败的测试 ” 而 最后一个任务是“重构” (提高代码的可读性,消除重复)。
5.9 定下每日例会的时间地点
Sprint 计划会议有一个产物常常被人们忽略: “确定的时间和地点, 以供举办每日例会”。 没有这一点,你的 sprint 就会有个“开门黑”。实际上,每个人都是在当前 sprint 的第一个每日例会上决定怎样开始工作。
我们的默认做法是选一个大家都不会有异议的最早时间。一般是9:00,9:30 或者 10:00。最关键的是,这必须是每个人都能完全接受的时间。
5.10 最后界限在哪里
OK,现在时间已经用完了。如果时间不够的话,那么我们该把哪些本该做的事情砍掉呢?
嗯,我总是用下面这个优先级列表:
优先级 1: sprint 目标和演示日期。这是启动 sprint 最起码应该有的东西。团队有一个目标,一个结束日期,然后就可以马上根据产品backlog 开始工作。没错,这是不像话,你应该认真考虑一下明天再开个新的 sprint 计划会议。不过如果确实需要马上启动 sprint,不妨先这么着吧。认真说来,只有这么点儿信息就开始 sprint,我还从来没有试过。
优先级 2:经过团队认可、要添加到这个 sprint 中的故事列表。
优先级 3:Sprint 中每个故事的估算值。
优先级 4:Sprint 中每个故事的“如何演示”。
优先级 5:生产率和资源计算,用作 sprint 计划的现实核查。包括团队成员的名单及每个人的承诺(不然就没法计算生产率)。
优先级 6:明确每日例会固定举行的时间地点。这只需要花几分钟,但如果时间不够用,Scrum master 可以在会后直接定下来,邮件通知所有人。
优先级 7:把故事拆分成任务。这个拆分也可以在每日例会上做,不过这会稍稍打乱 sprint 的流程。
5.11 技术故事
这有个很复杂的问题:技术故事。或者叫做非功能性条目,或者你想叫它什么都行。
我指的是需要完成但又不属于可交付物的东西,跟任何故事都没有直接关联,不会给产品负责人带来直接的价值。
我们把它叫做“技术故事”。
例如:
安装持续构建服务器
o 为什么要完成它:因为它会节省开发人员的大量时间,到迭代结束的时候,集成也不太容易出现重大问题。
编写系统设计概览
o 为什么要完成它:因为开发人员常常会忘记系统的整体设计,写出与之不一致的代码。团队需要有个描述整体概况的文档, 保证每个人对设计都有同样的理解。
重构 DAO 层
o 为什么要完成它:因为 DAO 层代码已经乱成一团了。混乱带来了本可以避免的 bug,每个人的时间都在被无谓的消耗。清理代码可以节省大家的时间,提高系统的健壮性。
升级 Jira (bug 跟踪工具)
o 为什么要完成它:当前的版本 bug 狂多,又很慢, 升级以后可以节省大家时间。
所以我们采取了下面这些做法:
1) 试着避免技术故事。努力找到一种方式,把技术故事变成可以衡量业务价值的普通故事。这样有助于产品负责人做出正确的权衡。
2) 如果无法把技术故事转变成普通故事,那就看看这项工作能不能当作另一个故事中的某个任务。例如,“重构 DAO 层”可以作为“编辑用户”中的一个任务,因为这个故事会涉及到 DAO 层。
3) 如果以上二者都不管用,那就把它定义为一个技术故事,用另外一个单独的列表来存放。产品负责人能看到它,但是不能编辑它。用“投入程度”和“预估生产率”这两个参数来跟产品负责人协商,从 sprint 里拨出一些时间来完成这些技术故事。
6, 我们怎样让别人了解我们的 sprint
我们要让整个公司了解我们在做些什么,这件事情至关重要。否则其他人就会发出抱怨,甚或对我们的工作做出臆断。
我们为此使用“sprint 信息页”。
我们在 wiki 上还有个“dashboard”页面, 链向所有正在进行的 sprint。
7, 我们怎样编写 sprint backlog
任务板
你当然也可以用白板。不过那多少有点浪费。可能的话,还是把白板省下来画设计草图,用没有挂白板的墙做任务板。
注意——如果你用贴纸来记录任务,别忘了用真正的胶带把它们粘好,否则有一天你会发现所有的贴纸都在地上堆成一堆。
8, 我们怎样进行 sprint 演示
Sprint 演示(有人也叫它 sprint 回顾)是 Scrum 中很重要的一环,却常为人们低估。
“哦,我们真的必须做演示么?没啥好东西能展示的!”
“我们没时间准备&%$#的演示!”
“我没时间参加其他团队的演示!”
8.1 为什么我们坚持所有的 sprint 都结束于演示
一次做得不错的演示,即使看上去很一般,也会带来深远影响。
团队的成果得到认可。他们会感觉很好。
其他人可以了解你的团队在做些什么。
演示可以吸引相关干系人的注意,并得到重要反馈。
演示是(或者说应该是)一种社会活动,不同的团队可以在这里相互交流,讨论各自的工作。这很有意义。
做演示会迫使团队真正完成一些工作,进行发布(即使是只在测试环境中)。如果没有演示,我们就会总是得到些99%完成的工作。有了演示以后,也许我们完成的事情会变少,但它们是真正完成的。这(在我们的案例中)比得到一堆貌似完成的工作要好得多,而且后者还会污染下一个 sprint。
8.2 Sprint 演示检查列表
确保清晰阐述了 sprint 目标。如果在演示上有些人对产品一无所知,那就花上几分钟来进行描述。
不要花太多时间准备演示,尤其是不要做花里胡哨的演讲。把那些玩意儿扔一边去,集中精力演示可以实际工作的代码。
节奏要快,也就是说要把准备的精力放在保持演示的快节奏上,而不是让它看上去好看。
让演示关注于业务层次, 不要管技术细节。注意力放在“我们做了什么”,而不是“我们怎么做的”。
可能的话,让观众自己试一下产品。
• 不要演示一大堆细碎的 bug 修复和微不足道的特性。你可以提到一些,但是不要演示,因为它们通常会花很长时间, 而且会分散大家的注意力,让他们不能关注更加重要的故事。
9, 我们怎样做 sprint 回顾
9.1 为什么我们坚持所有的团队都要做回顾
由于某些原因,团队常常都不太愿意做回顾。如果不给他们点温柔的刺激,我们的大多数团队都会跳过回顾,直接进行下一个 sprint。也许这只是瑞典的文化,我不太确定。
不过,看起来每个人都觉得回顾的用途极大。说句实话,我认为 回顾[retrospective]是 Scrum 中第二重要的事件 (最重要的是 sprint 计划会议),因为这是你做改进的最佳时机!
如果没有回顾,你就会发现团队在不断重犯同样的错误。
9.2 我们如何组织回顾
• 根据要讨论的内容范围,设定时间为 1 至 3 个小时。
• 参与者:产品负责人,整个团队还有我自己。
• 我们换到一个封闭的房间中,或者舒适的沙发角,或者屋顶平台等等类似的场所。只要能够在不受干扰的情况下讨论就好。
• 我们一般不会在团队房间中进行回顾,因为这往往会分散大家的注意力。
• 指定某人当秘书。
• Scrum master 向大家展示 sprint backlog, 在团队的帮助下对sprint 做总结。包括重要事件和决策等。
• 我们会轮流发言。每个人都有机会在不被人打断的情况下讲出自己的想法,他认为什么是好的,哪些可以做的更好,哪些需要在下个 sprint 中改变。
• 我们对预估生产率和实际生产率进行比较。如果差异比较大的话,我们会分析原因。
• 快结束的时候,Scrum master 对具体建议进行总结,得出下个 sprint 需要改进的地方。
三列分别是:
Good:如果我们可以重做同一个 sprint,哪些做法可以保 持。
Could have done better:如果我们可以重做同一个 sprint, 哪些做法需要改变。
Improvements:有关将来如何改进的具体想法。
第一列和第二列是回顾过去,第三列是展望将来。
团队通过头脑风暴得出所有的想法,写在即时贴上,然后用“圆点投票”来决定下一个 sprint 会着重进行哪些改进。每个人都有三块小磁铁,投票决定下个 sprint 所要采取措施的优先级。他们可以随意投票,也可以把全部三票投在一件事情上。
根据投票情况,他们选出了 5 项要重点进行的过程改进,在下一个回顾中,他们会跟踪这些改进的执行情况。不过不要想一口吃成个胖子,这一点很重要。每个 sprint 只关注几个改进就够了。
9.3 在团队间传播经验
Sprint 回顾不只关注团队怎样才能在下个 sprint 中做得更好,它有更广袤的含义。
我们的处理策略比较简单。有一个人(我们这儿是我)会参加所有的 sprint 回顾会议,充当知识桥梁。不用太正二八经。
另一种方式,是让每个 Scrum 团队都发布 sprint 回顾报告。我们试过这么做,但发现很多人都不会去读报告,而就此展开改进的就更少了。所以我们还是用了上面那种简单的方式。
充当“知识桥梁“的人需要服从一些重要规则:
他应当是一个很好的倾听者。
如果回顾会议过于沉寂,他应该问一些简单而目标明确的问题,以刺激团队展开讨论。例如“如果时间可以倒流,从第一天重新开始这个 sprint,那你觉得哪些事情会用其它方式来做?”
他应该自愿花时间参加所有团队的全部回顾。
他应该有一定的行政权力,如果出现一些团队无法控制的改进建议,他可以帮助推进实施。
10, 我们怎样组合使用 Scrum 和 XP
要说组合使用 Scrum 和 XP(极限编程)可以带来累累硕果,这毫无争议。我在网上看到过的绝大多数资料都证实了这一点,所以我不会花时间去讨论为什么要这么做。
不过,我还是会提到一点。 Scrum 注重的是管理和组织实践 ,而 XP 关注的是实际的编程实践 。这就是为什么它们可以很好地协同工作——它们解决的是不同领域的问题, 可以互为补充,相得益彰。
10.1 XP 中最有价值的一些实践
结对编程
测试驱动开发(TDD)
持续集成
代码集体所有权
充满信息的工作空间
代码标准
10.2 结对编程
有关结对编程的一些结论:
结对编程可以提高代码质量。
结对编程可以让团队的精力更加集中(比如坐在你后面的那个人会提醒你,“嘿,这个东西真的是这个 sprint 必需的吗?”)。
令人惊奇的是,很多强烈抵制结对编程的开发人员根本就没有尝试过,而一旦尝试之后就会迅速喜欢上它。
结对编程令人精疲力竭,不能全天都这样做。
常常更换结对是有好处的。
结对编程可以增进团队间的知识传播。速度快到令人难以想象。
有些人就是不习惯结对编程。不要因为一个优秀的开发人员不习惯结对编程就把他置之不理。
可以把代码审查作为结对编程的替代方案。
“领航员”(不用键盘的家伙)应该自己也有一台机器。不是用来开发,而是在需要的时候稍稍做一些探索尝试、当“司机”(使用键盘的家伙)、遇到难题的时候查看文档,等等。
不要强制大家使用结对编程。鼓励他们,提供合适的工具,让他们按照自己的节奏去尝试。
10.3 测试驱动开发(TDD)
有关 TDD 的一个 10 秒钟总结:
测试驱动开发意味着你要先写一个自动测试 , 然后 编写恰好够用的代码 ,让它通过这个测试,接着 对代码进行重构 ,主要是提高它的可读性和消除重复。整理一下,然后继续。
人们对测试驱动开发有着各种看法:
TDD 很难。开发人员需要花上一定时间才能掌握。 实际上,往往问题并不在于你用了多少精力去教学、辅导和演示——多数情况下,开发人员掌握它的唯一方式就是跟一个熟悉 TDD 的人一起结对编程,一旦掌握以后,他就会受到彻
底的影响,从此再也不想使用其它方式工作。
TDD 对系统设计的正面影响特别大。
在新产品中,需要过上一段时间,TDD 才能开始应用并有效运行,尤其是黑盒集成测试。但是回报来得非常快。
投入足够的时间,来保证大家可以很容易地编写测试。这味着要有合适的工具、有经验的人、提供合适的工具类或基类,等等。
我们在测试驱动开发中使用了如下工具:
jUnit / httpUnit / jWebUnit。我们正在考虑使用 TestNG 和 Selenium.
HSQLDB 用作嵌入式的内存数据库,在测试中使用。
Jetty 用作嵌入式的内存 Web 容器,在测试中使用。
Cobertura 用来度量测试覆盖率。
Spring 框架用来织入不同类型的测试装置(带有 mock、不带 mock、带有外部数据库或带有内存数据库等等)。
它会把 开发-构建-测试这三者构成的循环变得奇快无比 ,同时还可以充当一张安全网,让开发人员有足够的信心频繁重构,伴随着系统的增长,设计依然可以保持整洁和简单。
10.4 持续集成
我们的大多数产品在持续集成方面都已经很成熟了,它们是基于Maven 和 QuickBuild 的。这样做很管用,而且节省了我们大量时间。 对于 “哎,它在我的电脑上没有问题”这样的老问题,持续集成也是终极解决方案。要判断所有代码库的健康状况,可以用持续构建服务器充当“法官”或是参考点。每次有人向版本控制系统中 check in 东西,持续构建服务器就会醒来,在一个共享服务器上从头构建一切,运行所有测试。如果出现问题,它就会向整个团队发送邮件告知大家构建失败, 在邮件中会包括有哪些代码的变化导致构建失败的精确细节,指向测试报告的链接等。
每天晚上,持续构建服务器都会从头构建产品,并且向我们的内部文档门户上发布二进制文件(ears,wars 等)、文档、测试报告、测试覆盖率报告和依赖性分析报告等等。 有些产品也会被自动部署到测试环境中。
把这一切搭建起来需要大量工作,但付出的每一分钟都物有所值。
10.5 代码集体所有权
我们鼓励代码集体所有权,但并不是所有团队都采取了这种方式。我们发现:在结对编程中频繁交换结对,会自动把代码集体所有权提到一个很高的级别。我们已经证实,如果团队拥有高度的代码集体所有权,这个团队就会非常健壮,比如某些关键人物生病了,当前的 sprint 也不会因此嗝屁朝凉。
10.6 充满信息的工作空间
所有团队都可以有效利用白板和空的墙壁空间。很多房间的墙上都贴满了各种各样关于产品和项目的信息。这样做最大的问题,就是那些旧的作废信息也堆在墙上,也许我们应该在每个团队中引入一个“管家”的角色。
10.7 代码标准
不久前我们开始定义代码标准。它的用处很大,要是我们早就这样做就好了。引入代码标准几乎没花多少时间,我们只是一开始从简单入手,让它慢慢增长。只需要写下不是所有人都了如指掌的事情,并尽可能加上对外部资料的链接。
绝大多数程序员都有他们自己特定的编程风格。 例如他们如何处理异常,如何注释代码,何时返回 null 等等。有时候这种差异没什么关系,但在某些情况下,系统设计就会因此出现不一致的现象,情况严重,代码也不容易看懂。这时代码标准的用处就会凸显,从造成影响的因素中就可以知道了。
我们代码标准中的一些例子:
你可以打破这里的任一规则,不过一定要有个好理由,并且记录下来。
默 认 使 用 Sun 的 代 码 惯 例 :http://java.sun.com/docs/codeconv/html/CodeConvTOC.doc.html
永远,永远,永远不要在没有记录堆栈跟踪信息(stack或是重新抛出异常的情况下捕获异常。 log.debug() 用
trace)也不错,只要别丢失堆栈跟踪信息就行。
使用基于 setter 方法的依赖注入来将类与类解耦 (当然, 如果紧耦合可以令人满意的话就另当别论)。
避免缩写。为人熟知的缩写则可以,例如 DAO。
需要返回 Collections 或者数组的方法不应该返回 null。应该返回空的容器或数组,而不是 null。
10.8 可持续的开发速度/精力充沛的工作
很多有关敏捷软件开发的书都声称:加班工作在软件开发中会降低生产率。
经过几次不情愿的试验之后,我完全拥护这种说法