【先更!!】爬虫之动态网站~~爬图片辣(也是我的第二个python爬虫emmmm
一. 简介
(爬虫,爬虫,就是一只在“爬”的虫hh,网络爬虫,也被称为网络蜘蛛,它能根据网页的url爬取网页的内容。)
问:什么是网络爬虫
答:一段程序(一个脚本)
问:爬虫能干什么
答:能够模拟浏览器自动的浏览网页,自动的、批量的采集我们需要的资源(图片、视频、文件等)
如果现在我想要下载一篇小说(现在好多都不免费辣~),首先!我找到了一个很优秀的网站,可以免费在线阅读,但是想要下载的话,那就要一章~一章的下载辣,那么这个时候,你是不是也在想着,何不写一个简单的小程序让它自己去下载呢!那么就要考虑一下我们的python爬虫辣,是不是感觉有点意思了!巴拉巴拉~~
但是!今天我们不下载小说^.^嘿嘿 (爬小说的下次补上辣。 我们今天来试试爬一个动态网站,让它自动下载一些图片 - -
首先,想要做爬虫,还是要稍微了解一下下html的。
HTML(超文本标记语言),是一种标记性语言,标记语言是一套类似 < a >,< /a>这样的标记标签,然后通过浏览器的实现标准来翻译成精彩的页面,也就是我们平时看到的网页啦,如下图:
 那么这个网页的html信息是怎么显示出来的呢!如下图:
那么这个网页的html信息是怎么显示出来的呢!如下图:
只要右击网页空白处,点击这个检查就可以啦~
二. 辅助工具
了解了这个之后,我们看一下爬虫需要的几个简单的辅助工具:
1. urllib库是python内置的,无需我们额外安装,只要安装了Python就可以使用。
2. requests库:这是一个很强大的第三方库,很好用呐~所以我们用它来获取网页的HTML信息。
在cmd中使用如下指令安装requests
![]()
或者
![]()
requests的官方中文教程地址:http://docs.python-requests.org/zh_CN/latest/user/quickstart.html
感兴趣的宝贝儿可以去看看
3.BeautifulSoup库:一款优秀的HTML/XML解析库,用来做爬虫,不用考虑编码,很强大很好用
安装方法和requests类似,同样官方中文教程:https://beautifulsoup.readthedocs.io/zh_CN/latest/
4.Fidder工具:这是一个用来抓包的软件,能够截获所有的HTTP通讯。一般网站都会有反爬机制,我们用这个软件来分析网页,或者在爬取动态网站时,也要用这个软件来分析网页,找到他的JavaScript脚本!!......等
下载地址:https://www.telerik.com/fiddler
用的话,也蛮简单哒!
在安装之后需要改下配置:tools--->options--->https,不然的话,抓到的好多网页都显示加密!

爬虫的辅助工具还有很多,而在这块,我们暂时只用到了这几个,所以只简单的介绍了下这几个辣。
三. 开爬!!!!
准备工作做得也算蛮充分辣,那么我们就开始吧!
网站URL:https://unsplash.com/
在这个网站,我们可以免费下载好多的免费高清壁纸,相信大家看到好看的图片的第一反应,也是把它下载下来,收藏起来吧哈哈,那么,我们来试着爬取一下这个网站,实现一个批量下载。
首先捋一下思路!!!!我们想要下载图片,就要有图片的url,那么图片的url从哪里来呢,就要:
1.使用requests来获取整个网页的HTML信息
2.使用BeautifulSoup解析HTML信息,找到所有
3.当然是根据拿到的图片的url来下载图片啦~~
看着似乎也不是很难
那么我们来试试吧嘻嘻。
1.首先获取整个网页的HTML信息,来找标签:
"""
Created on Thu Nov 22 14:44:26 2018
@author: 小象
"""
import requests
if __name__ == '__main__':
target = 'https://unsplash.com/'
req = requests.get(url=target)
print(req.text)运行结果:

网页源码:
似乎我们获取到的html信息和我们预料中的不太一样呢,怎么一个标签都么有!!!这是为什么呢,原因就在于这个网站是一个动态网站啦!而动态网站有一部分目的也是为了反爬虫,那么什么是动态加载呢,就是说,我们每次进来网站首页的照片都是不同的,是在不断更新滴!!动态加载一般都是调用JavaScript脚本来实现的,那么在这块,我们只要找到负责动态加载图片的JavaScript脚本,不就可以找到图片的存放地址了吗(即url),现在!!!就需要我们强大的抓包工具------Fiddler小伙伴登场啦,(当然,也可以用浏览器自带的NetWorks哈,按F12就好)如图:
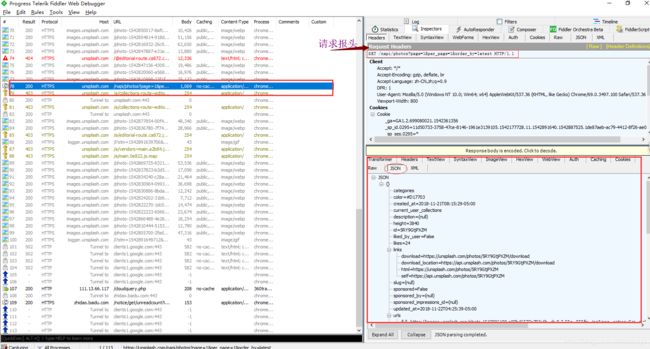
可以看到,左侧红框处,就是我们GET请求的地址,也就是网站的URL,右下侧是服务器返回的信息,我们可以看到服务器返回的json格式的数据,这里面,似乎就有我们需要的内容鸭!!
EN对!还有这个JavaScript的请求地址(仔细瞅瞅),放在下图吧!
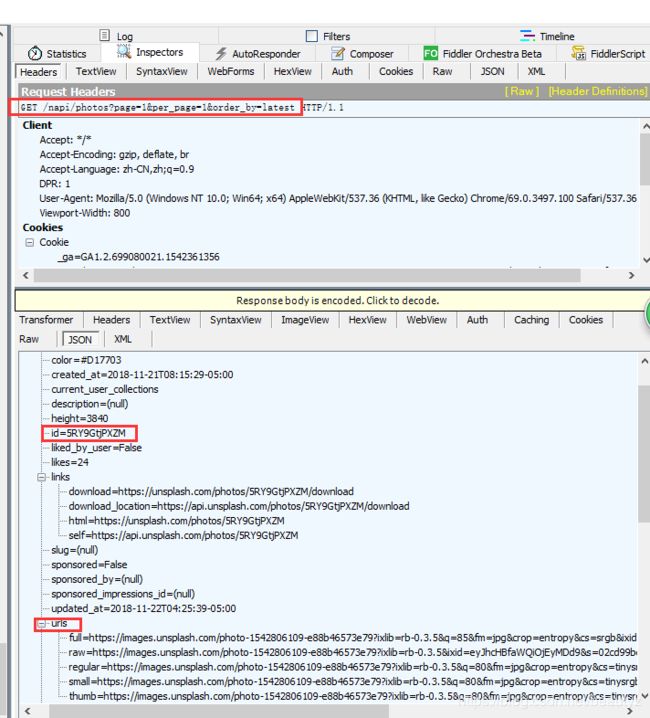
对!没错!就是这个:http://unsplash.com/napi/photos?page=1&per_page=10&order_by=latest
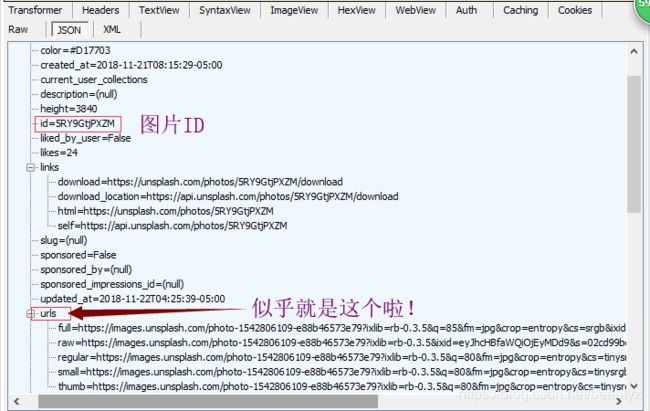
分析发现,在这个返回的数据信息里面,我们找到了图片的id,大小,链接等,那么~~是不是稍微有点头绪了咩。
那么我们在继续这个网站的分析,之前用Fiddler软件有分析出一些东西,但是始终感觉抓不住???嗯?(是不熟悉emmmm)哈哈,后面用浏览器自带的NetWorks分析了一下(好像也蛮好用),如下图:
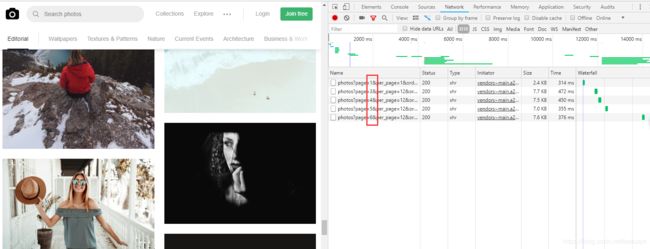
在不断往下拉进度条之后,会发现这个page在变,那么~~~不妨有一个大胆的想法,对哒!!!让这个page一直在变的话,就可以拿到好多好多的图片啦,再继续看!
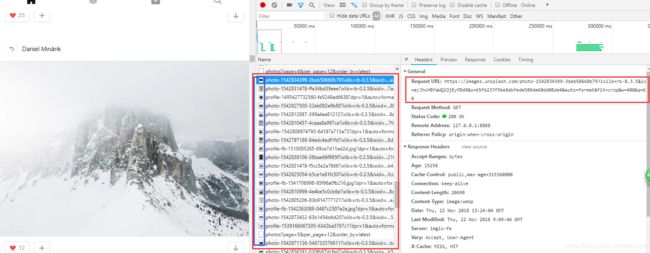
在这块,我们可以看到好多之前在fiddler那块看到的urls,左边似乎还是图片的缩略图,嘻嘻,那么,可以复制一个url来试试,发现,嗯!确实是可以下载的,那么,我们的一大问题,似乎也解决了,现在就是要拿到这个URL,然后去下载保存图片!!!
那么接下来就是看如何拿到这个URL了,按照我们的思路,编写代码如下:
# -*- coding: utf-8 -*-
"""
Created on Fri Nov 23 11:15:46 2018
@author: 小象
"""
import requests,json
if __name__ == '__main__':
page_num = 1
target = 'http://unsplash.com/napi/photos?page=xxx&per_page=30&order_by=latest'
target = target.replace('xxx',str(page_num))
req = requests.get(url=target, verify=False)
# 分析json脚本
html = json.loads(req.text)
image_count = 0
# 获取到了图片id和url,通过url就可以下载,然后保存在本地
for index, each in enumerate(html):
print(image_count)
print('图片id:', each['id'])
print('urls:', each['urls']['small'])
image_count += 1
这块为了防止爬的次数太多,被网站拉黑,加了个  这个,以防报SSL认证错误,SSL认证是指客户端到服务器端的认证,一个非常简单的解决错误的方法就是设置一下这个requests.get()方法的verify参数。这个参数默认设置为True,也就是执行认证。我们将其设置为False,绕过认证不就可以啦!
这个,以防报SSL认证错误,SSL认证是指客户端到服务器端的认证,一个非常简单的解决错误的方法就是设置一下这个requests.get()方法的verify参数。这个参数默认设置为True,也就是执行认证。我们将其设置为False,绕过认证不就可以啦!
看一下上面这段代码的执行结果吧:
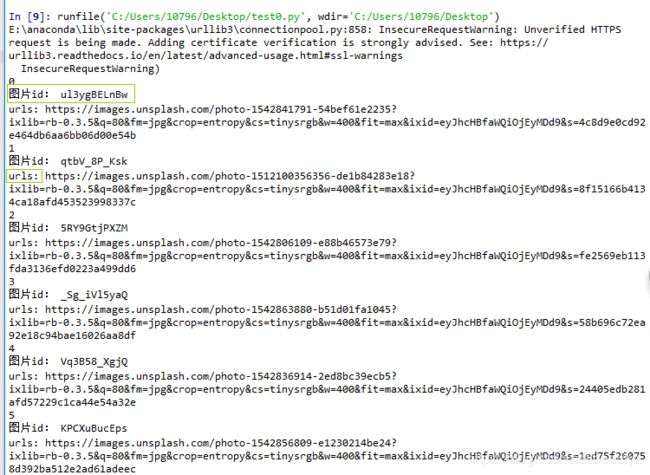
可以看到,我们已经顺利地拿到了图片的id和url!!!也就是说,离下载又更近一步啦!
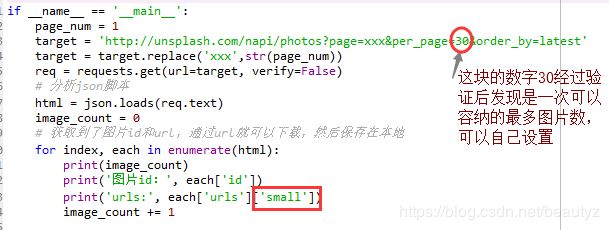
然后还有这个数字30和这个'small',small的话是我们之前分析出来的,发现一张图片有好几个url,看了一下,原来都是一样的,只不过是规格不一样,如下图:
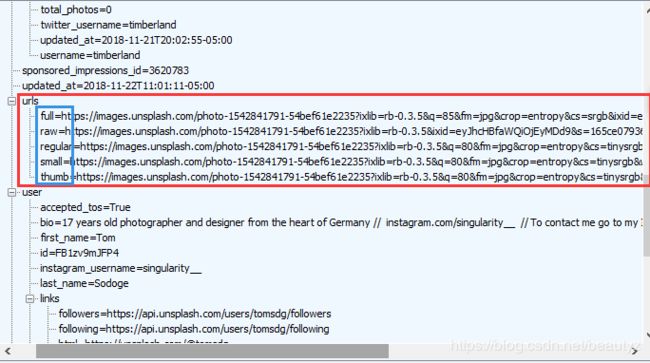
所以我在这块写的是small啦~~下载速度会稍微快一丢丢。
现在是id也有了,url也有了,那就要考虑下载之后的保存问题啦!!在这块,我是在网上找的一段代码,嘻嘻很好用
看一下吧,就是这个:
# 保存图片
def save_img(file_save_path, img_id, img_url):
try:
# 是否有这个路径
if not os.path.exists(file_save_path):
# 创建路径
os.makedirs(file_save_path)
res_filename = '{}{}{}.{}'.format(file_save_path, os.sep, img_id, find_suffix(img_url))
print(res_filename)
# 下载图片,并保存到文件夹中
urllib.request.urlretrieve(img_url, filename=res_filename)
except IOError as e:
print("IOError")
except Exception as e:
print("Exception")嗯~现在呢,我们所需要的我们已经拿到了,那么就来整合一下代码!
# -*- coding: utf-8 -*-
"""
Created on Mon Nov 19 14:24:19 2018
@author: 小象
"""
from urllib.parse import urlsplit
import requests, json, os, urllib
# 获取图片的后缀
def find_suffix(url):
url_return = url.split('?')
res = res = urllib.parse.parse_qs(url_return[1])
res_new = str(res['fm']).replace("['", "").replace("']", "")
return str(res_new)
# 保存图片
def save_img(file_save_path, img_id, img_url):
try:
# 是否有这个路径
if not os.path.exists(file_save_path):
# 创建路径
os.makedirs(file_save_path)
res_filename = '{}{}{}.{}'.format(file_save_path, os.sep, img_id, find_suffix(img_url))
print(res_filename)
# 下载图片,并保存到文件夹中
urllib.request.urlretrieve(img_url, filename=res_filename)
except IOError as e:
print("IOError")
except Exception as e:
print("Exception")
if __name__ == '__main__':
file_path = 'C:/Users/10796/Desktop/爬虫img_save'
page_num = 1
image_count = 0
while True:
target = 'http://unsplash.com/napi/photos?page=xxx&per_page=10&order_by=latest'
target = target.replace('xxx',str(page_num))
req = requests.get(url=target, verify=False)
# 分析json脚本
html = json.loads(req.text)
# 获取到了图片id和url,通过url就可以下载,然后保存在本地
for index, each in enumerate(html):
print('正在下载第%d张图片' % (image_count+1))
print('图片id:', each['id'])
print('urls:', each['urls']['small'])
save_img(file_path, each['id'], each['urls']['small'])
image_count += 1
page_num += 1看一下运行结果吧~~~
嘿嘿,就是这个样子啦!因为我们图片规格都选的small,所以下载速度也还可以哈
在这块我们再来做一个总结!!
爬虫的一般步骤:
首先向目标浏览器发送一个requests请求,这块可以模仿请求头,等待服务器响应,如果请求失败的话,就要抓包来分析网页,和正常访问的数据包作对比;如果成功那么就要来解析数据,清洗数据,保存数据。