Cortex-M3内核简析
MCU的主要组成有:内核、储存器、外设。大部分刚接触MCU的人员一般是从关注外设的使用开始,但对于要深入理解MCU工作原理,了解MCU的内核、储存器这两部分内容是很有必要的。本文将以Cortex-M3内核为例对MCU的内核做一个简要分析。主要关注以下三个问题:
问题一、定义:Cortex-M3内核是什么?
问题二、结构:Cortex-M3架构是怎么样的?
问题三、功能:Cortex-M3架构各模块各有什么用?
下面我们来通过解答以上三个问题来初步认识Cortex-M3内核。
一、Cortex-M3内核是什么(定义)?
Cortex-M3
内核是单片机的中央处理器单元
CPU
。
Cortex-M3
内核与基于
Cortex-M3
的
MCU区别
:
基于
Cortex-M3
的
MCU
:
Cortex-M3+
存储器
+
外设等。
Cortex-M3内核通过接口总线的形式挂载了储存器、外设、中断等组成一个MCU,
如图所示

二、Cortex-M3架构是怎么样的(结构)?
特点:
1、Cortex-M3
是一个
32
位处理器内核。内部的数据路径是
32
位,寄存器是
32
位,存储器接口是
32
位。
2、Cortex-M3
采用哈佛架构。拥有独立的指令总线和数据总线,取指与数据访问可以同时进行。
3、
支持小端模式、大端模式。
组成介绍:
Cortex-M3内核的架构如下图所示,本文我们主要关注架构图中标了序号的模块。有:
寄存器组(①)、NVIC(②)、中断和异常(③)、储存器映射(④)、总线接口(⑤)、调试支持(⑥)、指令集。(注:数字序号与图中序号对应)
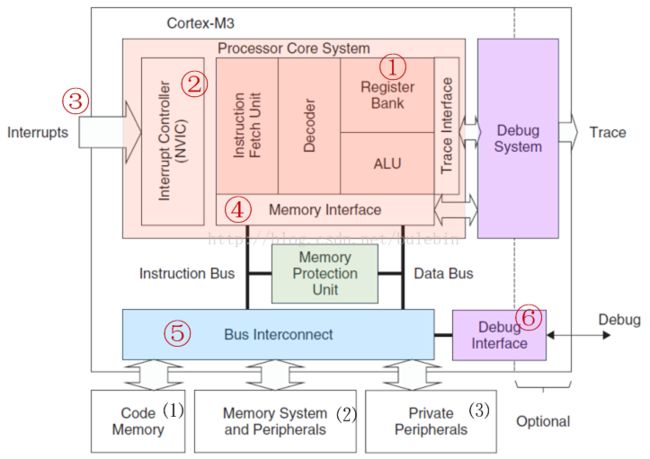
三、Cortex-M3架构各模块各有什么用(功能)?
1、寄存器组(①)
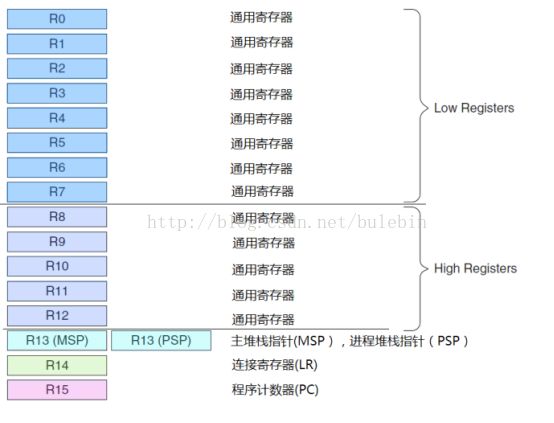
1、R0-R12
:通用寄存器
R0-R12
都是
32
位通用寄存器,用于数据操作。绝大多数
16
位
Thumb
指令只能访问
R0-R7
,
32
位
Thumb-2
指令可以访问所有寄存器。
2、R13
:两个堆栈指针。
CM3
拥有两个堆栈指针,都是
banked
,因此任一时刻只能使用其中一个。
主堆栈指针
MSP
:复位后缺省使用的堆栈指针,用于操作系统内核以及异常处理例程。
进程堆栈指针
PSP
:由用户的应用程序代码使用。
堆栈指针的最低两位永远是
0
,意味着堆栈总是
4
字节对齐。
3、R14
:连接寄存器
当调用一个子程序时,由
R14
存储返回地址。不像大多数其他处理器,
ARM
为了减少访问内存的次数,把返回地址直接存储在寄存器中。这样足以使很多只有
1
级子程序调用的代码无需访问内存(堆栈内存),从而提高子程序调用的效率。如果多于
1
级,则需要把前一级的
R14
值压到堆栈里。
4、R15
:程序计数寄存器
指向当前的程序地址,如果修改它的值,就能改变程序的执行流。
5、
特殊功能寄存器
PSRs
:程序状态字寄存器组
PRIMASK,FAULTMASK,BASEPRI
:中断屏蔽寄存器组
CONTROL:
控制寄存器
特殊功能寄存器的功能描述如下图所示。


2、NVIC
嵌套向量中断控制器(②)
1、
可嵌套中断支持。可嵌套中断支持,覆盖所有的外部中断和绝大多数系统异常。这些异常可以赋予不同的优先级。当前优先级被存储在
xPSR
的专用字段。当一个异常发生时,硬件会字段比较该异常是否与当前的异常优先级更高,如果发现来了更高优先级的异常,处理器就会中断当前的中断服务程序,而服务新来的异常。
2、
向量中断支持。当开始响应一个中断后,
Cortex-M3
会自动定位一张向量表,并且根据中断号从表中找出
ISR
的入口地址,然后跳转过去执行。
3、
动态优先级调整。软件可以在运行时期更改中断的优先级,如果在某
ISR
中修改了自己所对应中断的优先级,而且这个中断又有新的实例处于悬起中,也不会自己打断自己,从而没有重入风险。
4、
中断延迟大大缩短。
Cortex-M3为了缩短中断延迟,引入了几个新特性,包括自动的现场保护和恢复,以及其它的措施,用于缩短中断嵌套时的ISR间延迟。
5、
中断可屏蔽。既可以屏蔽优先级低于某个阈值的中断
/
异常(设置
BASEPRI
寄存器),也可以全体封杀(设置
PRIMASK
和
FAULTMASK
寄存器)。这是为了让时间关键的任务能在死线到来前完成,而不被干扰。
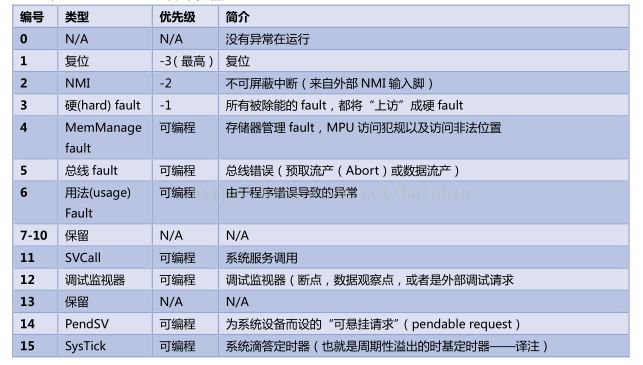
3、中断和异常(③)
Cortex-M3
的所有中断机制都由
NVIC
实现。除了支持
240
条中断之外,
NVIC
还支持
16-4-1=11
个内部异常源(4+1个为保留),可以实现
fault
管理机制。结果,
Cortex-M3
有了
256
个预定义的异常类型。
虽然
Cortex-M3
支持
240
个外中断,但具体使用了多少个是由芯片生产商决定。
Cortex-M3
还有一个
NMI
(不可屏蔽中断)输入脚,当它被置为有效时,
NMI
服务函数会无条件地执行。
4、存储器映射(④)
Cortex-M3
支持
4GB
存储空间。
不像其它的
ARM
架构,它们的存储器映射由半导体厂商说的算。
Cortex-M3
预先定义了“粗线条的”存储器映射。通过把片上外设的寄存器映射到外设区,就可以简单地以访问内存的方式来访问这些外设的寄存器,从而控制外设的工作。不要每学一种不同的单片机就要熟悉一种新的存储器映射。
各个分区存储器映射如下图,有Code区(Flash区)、片上SRAM区、片上外设区、片外RAM区、片外外设区、
Cortex-M3私有外设区。

5、总线接口(⑤)
Cortex-M3
内部有若干个总线接口,以使
Cortex-M3
能同时取址和访内(访问内存):
1、
指令存储区总线(两条):有两条代码存储区总线负责对代码存储区的访问,分别是
I-Code
总线和
D-Code
总线。前者用于取指,后者用于查表等操作。(对应架构图中的数字序号⑴)
2、
系统总线用于访问内存和外设。覆盖的区域包含
SRAM
、片上外设、片外
RAM
、片外扩展设备,以及系统级存储区的部分空间。(对应架构图中的数字序号⑵)
3、
私有外设总线负责一部分私有外设的访问,主要是访问调试组件。它们也在系统级存储区。(对应架构图中的数字序号⑶)
6、调试支持(⑥)
Cortex-M3
在内核水平上搭载了若干种调试相关的特性。最主要的就是程序执行控制,包括停机(
halting
)、单步执行(
stepping
)、指令断点、数据观察点、寄存器和存储器访问、性能速写以及各种跟踪机制。
目前可用的
DPs
包括
SWJ-DP
,既支持传统的
JTAG
调试,也支持新的串行线调试协议
SWD
。
7、指令集
Cortex-M3
只使用
Thumb-2
指令集,它允许
32
位指令和
16
位指令水乳交融,代码密度和处理性能两手抓。
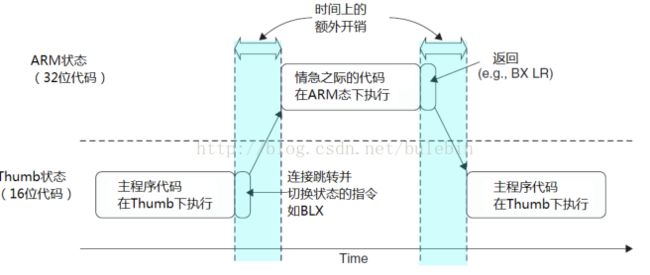
在过去,做
ARM
开放必须处理好两个状态。
32
位的
ARM
状态和
16
位的
Thumb
状态,这两个状态是井水不犯河水。当处理器在
ARM
状态下时
2
,所有的指令均是
32
位的,那怕是
NOP
指令,此时性能相当高。在
Thumb
状态下,所有的指令均是
16
位的,代码密度提高了一倍。但是,
Thumb
状态下的指令功能是
ARM
下的一个子集,结果可能需要更多条的指令区完成相同的工作,导致处理性能下降。
为了取长补短,很多应用程序都混合使用
ARM
和
Thumb
代码段。这种混合使用有额外开销,时间和空间上都有,主要发生在状态切换时,另一方面,
ARM
代码和
Thumb
代码需要以不同的方式编译,这也增加了软件开发管理的复杂度。
如下图为ARM7处理的状态切换图。
Cortex-M3
只使用
Thumb-2
指令集,使
Cortex-M3有几个方面比传统ARM处理器更先进:
1、消灭了状态切换的额外开销,节省了执行时间和指令空间。
2、不需要把源代码分成ARM编译和Thumb编译,软件开发的管理大大减少。
3、无需再反复求证和测试:究竟在何时何地切换到何种状态,程序才最有效率。
本文主要参考以下资料编写:
·《
Cortex M3
权威指南》