视频编解码算法面试总结
硕士毕业后,一直从事算法工程师,具有丰富的深度学习,图像视频处理经验,因此录制了一些课程,欢迎大家观看,有问题可以找我私聊:QQ:81664352,谢谢
基于web端的人脸识别算法视频教程
1.掌握深度学习图像处理(基于keras、tensorflow、opencv)
2.掌握web前后端设计(基 于flask框架)
3.开发基于web端的深度学习图像,把web端应用与人工智能相结合
[视频教程]
https://edu.csdn.net/course/detail/28400/391614?pre_view=1
H.264与H.265的主要差异
H.265仍然采用混合编解码,编解码结构域H.264基本一致,
主要的不同在于:
1.编码块划分结构:采用CU (CodingUnit)、PU(PredictionUnit)和TU(TransformUnit)的递归结构。
2.基本细节:各功能块的内部细节有很多差异
3.并行工具:增加了Tile以及WPP等并行工具集以提高编码速度
4.滤波器:在去块滤波之后增加了SAO(sample adaptive offset)滤波模块
H.265的框架图

PSNR计算方式
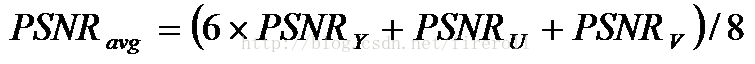
各模块技术差异汇总

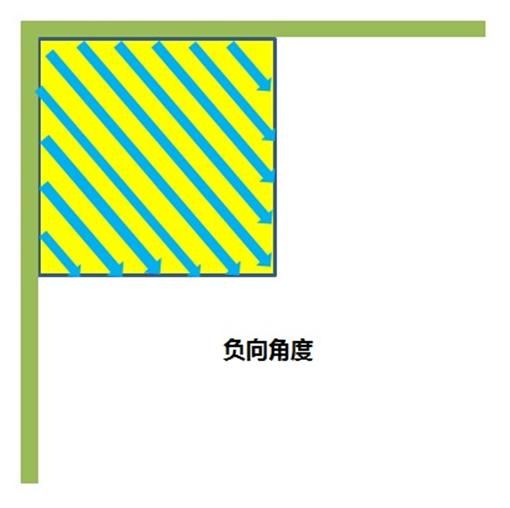
HEVC定义了33种预测角度的集合,其精度为1/32。根据经验,图像内容中水平和垂直一致通常出现的概率超过其他方向一致。相邻方向之间的角度差越接近这两个方向便越小,越靠近对角线方向便越大,其目的在于在接近水平和垂直模式时可以提供更加精准的预测结果,而在出现机会较低的对角方向减小预测的运算负荷。
DC模式,所有预测像素值都是同一个值,也即参考数据的均值,这也是DC模式命名的由来。
Plane模式,二维预测除了利用本行的相邻像素点进行预测外,还使用前一行的像素点进行预测。通过给不同行的像素值赋予相应的加权值,最后获得预测值。
首先从参考数据中获取的是顶行和左列的数据,并记录一下左下角和右上角的两个像素值。然后计算底行和右列的数据,方法是用左下角的像素减去顶行相应位置的像素得到底行,右上角的像素减去左列相应位置的像素得到右列。预测块中每个像素的数据,就是对应的四个边的像素值的平均
我们假设左上角起,上方那一行是17个像素是a1 b2 c3 d4 e5 f6 g7 h8 i9 j8 k7 l6 m5 n4 o3 p2 q1,用这17个像素计算一个H值。
我在上面标了1~9~1的数字,有数字相同的8对像素,后面计算的时候,都是一对对的计算的。
i9;j8 - h8;k7 - g7;l6 - f6;m5 - e5;n4 - d4;o3 - c3;p2 - b2;q1 - a1,这九对分别乘以权重0到8(也就是i9这个像素没有用到),而最左边和最右边两个像素权重最大。
同理V值,也是一样的算法,从上到下像素记作带'的(当然a1' = a1)。
然后计算一个A值,它等于右上角(q1)和左下角(V值计算时候对应的那个q1')的和乘以16
计算一个B值,它等于(5*H+32)/64,计算一个C值,C=(5*V+32)/64,这种后面加了32又除以64的,其实都是用来四舍五入的。
然后就能计算我们的预测值了。
i00 = A - 7*B -7*C + 16
pix[0][0] = i00 / 32(超出0到255范围的要截断成0或者255)
然后计算第一行十六个像素分别是i00 + B到i00 + 15*B,然后除以32(然后截断到0~255)
第二行是在第一行基础上加了一个C,一直到第16行,加了15个C,于是这256个像素都算出来了。



块划分结构
在H.265中,将宏块的大小从H.264的16×16扩展到了64×64,以便于高分辨率视频的压缩。
同时,采用了更加灵活的编码结构来提高编码效率,
包括编码单元(CodingUnit)、预测单元(PredictUnit)和变换单元(TransformUnit)。
如下图所示:

其中:
编码单元类似于H.264/AVC中的宏块的概念,用于编码的过程。
预测单元是进行预测的基本单元,
变换单元是进行变换和量化的基本单元。
这三个单元的分离,使得变换、预测和编码各个处理环节更加灵活,
也有利于各环节的划分更加符合视频图像的纹理特征,
有利于各个单元更优化的完成各自的功能。
RQT是一种自适应的变换技术,这种思想是对H.264/AVC中ABT(AdaptiveBlock-size Transform)技术的延伸和扩展。
对于帧间编码来说,它允许变换块的大小根据运动补偿块的大小进行自适应的调整;
对于帧内编码来说,它允许变换块的大小根据帧内预测残差的特性进行自适应的调整。
大块的变换相对于小块的变换,一方面能够提供更好的能量集中效果,并能在量化后保存更多的图像细节,但是另一方面在量化后却会带来更多的振铃效应。
因此,根据当前块信号的特性,自适应的选择变换块大小,如下图所示,可以得到能量集中、细节保留程度以及图像的振铃效应三者最优的折中。
帧内预测模式
本质上H.265是在H.264的预测方向基础上增加了更多的预测方向
H.265:所有尺寸的CU块,亮度有35种预测方向,色度有5种预测方向
H.264:亮度 4x4块9个方向,8x8块9个方向,16x16块4种方向,色度4种方向
H.264的帧内预测方向:
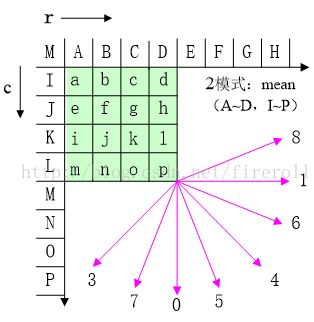 H.265的帧内预测方向:
H.265的帧内预测方向:
 6. 帧间预测
6. 帧间预测
本质上H.265是在H.264基础上增加插值的抽头系数个数,改变抽头系数值以及增加运动矢量预测值的候选个数,以达到减少预测残差的目的。
H.265与H.264一样插值精度都是亮度到1/4,色度到1/8精度,但插值滤波器抽头长度和系数不同.
H.265的增加了运动矢量预测值候选的个数,而H.264预测值只有一个

H.265的空域候选项:

H.265时域共同位置候选项
去块滤波
本质上H.265的去块滤波与H.264的去块滤波及流程是一致的,做了如下最显著的改变:
Ø 滤波边界: H.264最小到4x4边界滤波;而H.265适应最新的CU、PU和TU划分结构的滤波边缘,最小滤波边界为8x8,
Ø 滤波顺序:H264先宏块内采用垂直边界,再当前宏块内水平边界;而H.265先整帧的垂直边界,再整帧的水平边界
ALF自适应环路滤波
ALF在编解码环路内,位于Deblock和SAO之后,
用于恢复重建图像以达到重建图像与原始图像之间的均方差(MSE)最小。
ALF的系数是在帧级计算和传输的,可以整帧应用ALF,
也可以对于基于块或基于量化树(quadtree)的部分区域进行ALF,
如果是基于部分区域的ALF,还必须传递指示区域信息的附加信息。
采样点自适应偏移(Sample AdaptiveOffset)滤波
SAO(sample adaptive offset)滤波其实就是对去块滤波后的重建像素按照不同的模板进行分类,并对每一种分类像素进行补偿, 分类模板分为BO(Band offset)和EO(Edge offset)。

BO分类:

EO分类模块:
SAO在编解码环路内,位于Deblock之后,通过对重建图像的分类,对每一类图像像素值加减一个偏移,达到减少失真的目的,从而提高压缩率,减少码流。
采用SAO后,平均可以减少2%~6%的码流,而编码器和解码器的性能消耗仅仅增加了约2%。
并行化设计
当前芯片架构已经从单核性能逐渐往多核并行方向发展,因此为了适应并行化程度非常高的芯片实现,HEVC/H265引入了很多并行运算的优化思路, 主要包括以下几个方面:
(1)Tile
如图3所示,用垂直和水平的边界将图像划分为一些行和列,划分出的矩形区域为一个Tile,每一个Tile包含整数个LCU(Largest Coding Unit),Tile之间可以互相独立,以此实现并行处理:![]()

Tile划分示意图
(2 Entropy slice
Entropy Slice允许在一个slice内部再切分成多个Entropy Slices,每个Entropy Slice可以独立的编码和解码,从而提高了编解码器的并行处理能力:
Entropy Slice的概念是Sharp公司提出的,现在改名为lightweighted slice(轻量级slice?),这个提案主要解决的问题是针对H.264 Slice切分的一些缺点:
1. H.264的熵编码以slice为单位,这可能会造成各个slice之间的编码负担不均衡,有的slice负担重,有的则负担轻。理论上多切分一些slice有助于在多核计算机上提高负载均衡能力。
2.但是过多的Slice切分会造成压缩效率降低。
在测试中,一个1080p的图像被分为一个slice和32个entropyslice,编码效率损失极小。
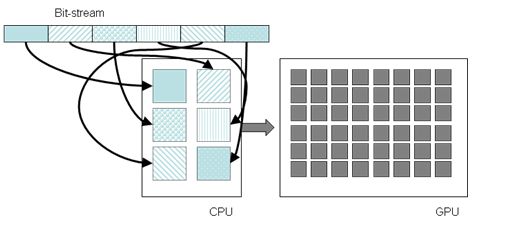
在提案中sharp还提出了一个CPU+GPU混合编码的方案,熵编码由多核CPU进行而重建则由GPU进行,可以大幅提高编码速度,如下图所示。
2) Slice
Slice是一帧中按光栅扫描顺序排列的CTU序列,一帧可以由多个slice组成,每个Slice可以独立解码,因为slice内像素的预测不能跨越slice的边界。每个slice可按照编码类型的不同分成I/P/B slice。该结构的主要目的是实现在传输中遭遇数据丢失后的重新同步。每个slice可携带的最大比特数通常受限,因此根据视频场景的运动程度,slice所包含的CTU数量可能有很大不同。

3) Dependent Slice
Dependent slice,其解码或编码的起始熵编码CABAC上下文状态是以上一个slice为基础,因此它不能完成数据丢失后的重新同步,该技术可以理解为对原先NALU数据的进一步拆分,可以适合更加灵活的打包方式。
(4)一幅图像可以被划分为若干个Slice,也可以划分为若干个Tile,两者划分的目的都是为了进行独立编码。某些Slice中可以包含多个Tile,同样某些Tile中也可以包含多个Slice。Tile包含的CTU个数和Slice中的CTU个数互不影响。
不同点:
划分方式:Tile为矩形,Slice为条带形。
组成结构:Slice由一系列的SS组成,一个SS由一系列的CTU组成。而Tile直接由一系列CTU组成。
WPP(Wavefront Parallel Processing)
上一行的第二个LCU处理完毕,即对当前行的第一个LCU的熵编码(CABAC)概率状态参数进行初始化,如图所示。因此,只需要上一行的第二个LCU编解码完毕,即可以开始当前行的编解码,以此提高编解码器的并行处理能力:
以一行LCU块为基本的并行单元,每一行LCU为一个子码流

Entropy Slice允许在一个slice内部再切分成多个EntropySlices,这样熵编解码器可以并行编码或解码,从而提高了并行处理能力。
需要注意的是一个entropy slice不能跨越slice边界,也就是一个slice可以含有多个entropy slice,但是一个entropy slice只能属于一个slice,如下图所示:

码率控制方法
CBR(Constant Bit Rate)是以恒定比特率方式进行编码,有Motion发生时,由于码率恒定,只能通过增大QP来减少码字大小,图像质量变差,当场景静止时,图像质量又变好,因此图像质量不稳定。这种算法优先考虑码率(带宽)。
这个算法也算是码率控制最难的算法了,因为无法确定何时有motion发生,假设在码率统计窗口的最后一帧发生motion,就会导致该帧size变大,从而导致统计的码率大于预设的码率,也就是说每秒统计一次码率是不合理的,应该是统计一段时间内的平均码率,这样会更合理一些。
VBR(Variable Bit Rate)动态比特率,其码率可以随着图像的复杂程度的不同而变化,因此其编码效率比较高,Motion发生时,马赛克很少。码率控制算法根据图像内容确定使用的比特率,图像内容比较简单则分配较少的码率(似乎码字更合适),图像内容复杂则分配较多的码字,这样既保证了质量,又兼顾带宽限制。这种算法优先考虑图像质量。