【论文解读 ICLR 2020 | 图上的预训练】STRATEGIES FOR PRE-TRAINING GRAPH NEURAL NETWORKS

论文题目:STRATEGIES FOR PRE-TRAINING GRAPH NEURAL NETWORKS
论文来源:ICLR 2020
论文链接:https://openreview.net/forum?id=HJlWWJSFDH¬eId=HJlWWJSFDH
代码链接:https://github.com/snap-stanford/pretrain-gnns/
关键词:GNN,GIN,预训练,迁移学习,图级别的任务,化学生物领域
文章目录
- 1 摘要
- 2 引言
- 3 PRELIMINARIES OF GNN
- 4 GNN预训练的策略
- 4.1 节点级别的预训练
- 4.1.1 上下文预测(context predicting):使用图结构的分布
- 4.1.2 属性遮掩(attribute masking):使用图属性的分布
- 4.2 图级别的预训练
- 4.2.1 有监督的图级别的属性预测
- 4.2.2 结构相似度预测
- 4.3 概览:预训练GNN和下游任务微调
- 5 相关工作
- 6 实验
- 7 总结
- 参考文献
1 摘要
本文解决的是图上的预训练问题。
预训练解决的问题是:针对特定任务的标签数据有限,可以在有充足数据的相关任务上进行模型的预训练,然后再针对下游任务进行微调。
在NLP、CV领域已经验证了预训练的有效性,如何在图上进行预训练呢?
本文提出一种新的GNN的预训练策略和自监督的方法。本文方法的关键是在单个节点以及整个图上进行预训练,这样GNN就可以同时学习到局部和全局的表示信息。
实验证明只在整张图上或者在单个节点上进行GNN的预训练,带来的提升很有限,甚至会在许多下游任务中带来负迁移。本文的策略避免了负迁移并且提升了多个下游任务的性能,在分子性质预测和蛋白质功能预测任务中超越了state-of-the-art。
2 引言
迁移学习指的是模型先在某些数据充足的任务上进行训练,然后在不同但相关的任务上重新使用。深度迁移学习已经在CV和NLP领域取得了巨大的成功,但是目前几乎没有在图数据上进行预训练的研究。
为什么要在图数据集上进行预训练?
(1)针对特定任务的有标签的数据非常有限。这个问题在化学生物等科学领域显得更加严重,这些领域的数据有限,而且标注起来非常耗时。
(2)来自真实世界应用的数据通常包含不均匀分布(out-of-distribution)的样本,也就是说训练集中的图和测试集中的图结构有很大的不同。例如要预测一个新合成的分子的属性信息,这个分子和训练集中所有出现的分子都不同。
然而,实现图数据上的预训练还是个挑战。一些研究表明成功的迁移学习需要和下游任务相关的大量的有标签的数据集,这就需要大量的领域专家选择和下游任务相关的样本并打标签。否则,很难把相关的预训练任务的知识泛化到新的下游任务,这被称为负迁移(negative transfer)[1],这限制了预训练模型的应用能力。
作者提出
使用预训练方法实现GNN上的迁移学习,用于图级别的属性预测。贡献如下:
(1)提出第一个对GNN预训练的系统的大规模研究策略。建立了两个大的预训练数据集:有2百万张图的化学数据集,有395K张图的生物数据集。作者还表明了大规模的特定领域的数据集对研究预训练的重要性,而现有的下游基线数据集都太小了不足以评估模型的可靠性。
(2)提出了有效的GNN预训练策略,并且证明了其有效性以及在难迁移问题上对out-of-distribution数据的泛化能力。
在系统的研究过程中,作者发现预训练GNN有时不能带来帮助。朴素的预训练策略会在许多下游任务中导致负迁移。看似强大的预训练策略(例如 使用state-of-the-art的GNN进行图级别的多任务的有监督预训练,用于图级别的预测任务),只能获得有限的性能提升。这种策略还会在许多下游任务中导致负迁移。
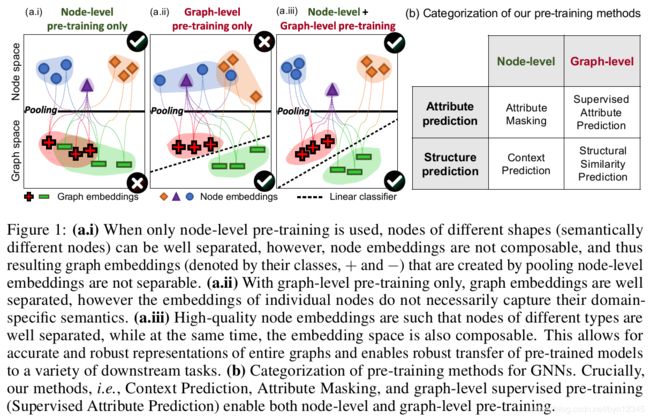
作者提出了有效的GNN预训练策略,关键思想是:使用易获得的节点信息,让GNN捕获关于节点和边的特定领域的知识,以及图级别的知识。这使得GNN学习到了全局和局部层面的表示信息,如图1 a.iii所示。并使得GNN可以生成鲁棒的可迁移到不同下游任务的图级别的表示(通过对节点表示的pooling得到),如图1所示。
在实验中和无预训练的GNN、使用图级别的多任务的有监督预训练进行了对比,在其基础上性能均有提升。还发现表示能力最强的的GIN[2]比表示能力较弱的模型,例如GCN、GraphSAGE、GAT更能从预训练中获益。并且,预训练GNN可以训练、微调地更快。
3 PRELIMINARIES OF GNN
(1)图上的监督学习
定义图为 G = ( V , E ) G=(V, E) G=(V,E),节点属性为 X v X_v Xv,边属性为 e u v e_{uv} euv。给定图的集合 { G 1 , . . . , G N } {\{G_1,..., G_N}\} {G1,...,GN}和标签 { y 1 , . . . , y N } {\{y_1,...,y_N}\} {y1,...,yN}。图上的有监督学习的任务是学习到图的向量表示 h G h_G hG为一个图预测标签: y G = g ( h G ) y_G=g(h_G) yG=g(hG)。
(2)GNN
GNN使用图上的连接已经节点和边的属性,为每个节点学习到向量表示 h v h_v hv。GNN通常是递归地聚合邻居信息和边的信息,更新目标节点的信息。 k k k次迭代后,目标节点 v v v的表示含有 k − h o p k-hop k−hop邻域的结构信息。第 k k k层的GNN定义为:
- h v ( k ) h^{(k)}_v hv(k)表示节点 v v v在第 k k k层的表示, h v ( 0 ) = X v h^{(0)}_v=X_v hv(0)=Xv;
- e u v e_{uv} euv表示节点 u , v u, v u,v之间连边的特征向量;
- N ( v ) \mathcal{N}(v) N(v)是节点 v v v的邻居集合。
(3)图表示学习
READOUT函数从最后一次迭代的输出中国得到整张图的表示 h G h_G hG:
READOUT函数是一种不随输入排序变化而改变的函数,例如平均操作或图级别的池化函数。
4 GNN预训练的策略
本文训练策略的核心是在单个节点层面以及整张图层面进行GNN的预训练,这使得GNN能捕获两个层面的针对领域的语义信息,如图1 a.iii所示。这和只使用整张图进行预训练(图1 a.ii)、只使用单个节点进行预训练(图1 a.i)形成对比。
4.1 节点级别的预训练
使用易得的无标签数据捕获图中特定领域的知识信息。作者提出两种自监督的方法:上下文预测(context prediction)和属性遮掩(attribute masking)。
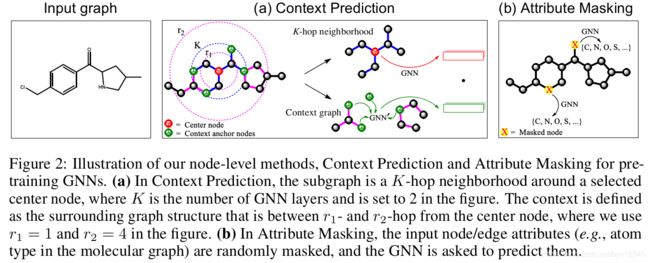
4.1.1 上下文预测(context predicting):使用图结构的分布
在上下文预测中,使用子图预测其周围的图结构。目标是训练出一个GNN可以将有着相似上下文结构的节点映射成相近的表示向量。
(1)邻居和上下文图
节点 v v v的** K − h o p K-hop K−hop邻居包含和 v v v距离不超过 K K K的所有节点和边**。节点 v v v的上下文图定义为 v v v邻居的图结构。用 K K K层的GNN聚合 v v v的 K K K阶邻居信息,得到节点嵌入 h v ( K ) h^{(K)}_v hv(K)。
上下文图由 r 1 , r 2 r_1, r_2 r1,r2两个参数描述,表示 v v v的 r 1 − h o p s r_1-hops r1−hops和 r 2 − h o p s r_2-hops r2−hops的子图(宽度为 r 2 − r 1 r_2-r_1 r2−r1的环)。
图2 a展示了邻居和上下文图。
其中, r 1 < K r_1
(2)使用辅助的GNN将上下文编码到向量中
由于图的组合特性,直接预测上下文图是很困难的。这不同于NLP,文本中的词语都是来源于一个有限的词表。
为了实现上下文的预测,作者使用辅助的GNN(context GNN)将上下文图编码成固定长度的向量,如图2 a中的 G N N ′ GNN^{'} GNN′所示。
如图2 a所示,应用上下文GNN得到上下文图的节点嵌入。然后对上下文锚节点的嵌入取平均,得到固定长度的上下文嵌入。节点 v v v对应的上下文嵌入表示为 c v G c^G_v cvG。
(3)使用负采样进行学习
使用负采样联合学习main GNN和context GNN。main GNN将邻居编码成节点嵌入,context GNN将上下文图编码成上下文的嵌入。
上下文预测的目标函数是一个二分类问题,判断特定的邻居和上下文图是否属于同一个节点:
![]()
- σ ( ⋅ ) \sigma(\cdot) σ(⋅)表示sigmoid函数
- 1 ( ⋅ ) \mathbf{1}(\cdot) 1(⋅)是指示函数
- 正样本对: v ′ = v , G ′ = G v^{'}=v, G^{'}=G v′=v,G′=G
- 负样本对:从随机选择的图 G ′ G^{'} G′中随机采样节点 v ′ v^{'} v′
- 负样本采样率为1,即正负样本数量相等,使用负对数似然函数作为损失函数。
预训练后的main GNN就是获得的预训练模型。
4.1.2 属性遮掩(attribute masking):使用图属性的分布
在属性遮掩中,目的是通过学习图结构上节点/边属性分布的规律,捕获到领域知识。
(1)Masking node and edges attributes
属性遮掩的预训练工作如下:mask掉节点/边的属性信息,基于邻域结构,使用GNN预测这些属性信息。图2 b展示了这一方法在分子图中的应用。
随机mask掉输入节点/边的属性,例如分子图中的原子类型,使用特殊的标志mask这些属性。然后使用GNN得到相应的节点/边的嵌入(边的嵌入可通过对边末尾连接的节点嵌入求和得到)。最后应用线性模型预测mask的节点/边的属性。注意使用的是非全连接的图来捕获不同图结构中节点/边的分布规律。
这种mask节点和边属性的方法可用于有丰富信息的图,例如:
(1)分子图,节点的属性对应于原子的类型。捕获到这些属性在图中是如何分布的,有助于GNN学习到简单的化学规则(例如 化合价)以及更复杂的化学现象。
(2)在蛋白质互作网络(PPI),边的属性对应于一对蛋白质中不同的互作关系。捕获这些属性在图中是如何分布的,有助于GNN学习到不同的交互是如何相互关联的。
4.2 图级别的预训练
有两种进行图级别的预训练方式:(1)对整张图的特定领域的属性做预测(例如 有监督的标签);(2)对图结构做预测。
4.2.1 有监督的图级别的属性预测
由于图级别的表示 h G h_G hG是直接用于下游预测任务的微调的,所以我们需要将特定领域的信息编码到 h G h_G hG中。
通过定义有监督的图级别的预测任务,我们将图级别特定领域的知识编码到预训练的嵌入表示中。具体来说是使用图级别的多任务的有监督预训练,联合预测多个图的标签(这些标签有真实值)。
例如,在蛋白质功能的预测中,目标是预测给定的蛋白质是否有给定的功能,可以预训练GNN来预测到目前为止已经被验证过的蛋白质的功能。
为了联合预测多个图属性,每个属性都对应于一个二分类任务,在得到图的表示后经过一个线性分类器。
仅仅使用多任务图级别的预训练进行迁移学习的效果可能并不好,因为一些有监督的预训练任务可能和下游任务不相关,甚至会对下游任务的性能产生负作用(负迁移)。一种方法是选择相关的有监督的预训练任务,并且在在这些任务上预训练GNN。但是这种方法通常不可取,因为选择出相关的任务需要专家的知识,而且预训练应该能应用于多个独立的不同的下游任务才对。
为了解决这一问题,作者只使用多任务的有监督预训练进行图级别的学习,不使用在此过程中生成的节点嵌入(如图1 a.ii所示)。这些无用的节点表示可能会加重负迁移问题,因为在节点的嵌入空间中,许多不同的预训练任务容易互相干扰。
所以,本文预训练的策略是:首先进行节点级别的预训练,然后再进行图级别的预训练。这种方法可以生产更具有可迁移能力的图表示,并且有鲁棒性,可以提高下游任务的性能,不需要专家人为选择有监督的预训练任务。
4.2.2 结构相似度预测
第二种图级别预测任务方法的目的是:建模两个图间结构的相似性。这样的任务有:建模图的编辑距离、预测图结构的相似性。然而找到图距离的真实值是很困难的,大规模的图数据集中节点对数量巨大。这个方法超出了本文的范围,将其作为未来的工作。
4.3 概览:预训练GNN和下游任务微调
本文提出的预训练策略是:首先进行节点级别的自监督预训练(4.1节),然后进行图级别的多任务有监督的预训练(4.2节)。
GNN的预训练结束后,将预训练得到的GNN模型在下游任务中进行微调。图级别的表示经过线性分类器后预测下游任务的图标签。
5 相关工作
使用无监督的方法学习图上的节点表示大致可分为两类:
(1)使用局部的基于随机游走的方法,预测边是否存在,进而重构图的邻接矩阵;
(2)Deep Graph Infomax方法,最大化局部节点表示和池化后的全局图的表示之间的互信息,训练得到节点编码器。
这些方法都是使得邻近的节点有相似的表示,在节点分类和链接预测任务中取得了很好的效果。但这种方法对于图级别的预测任务,可能不是最优的方法。在图级别的预测任务中,捕获局部邻域的结构相似性通常比捕获图中节点的位置信息更重要。本文的方法同时考虑了节点级别和图级别的预训练任务,并且在实验中证明了,对预训练模型同时使用这两种类型的任务可以显著提高其性能。
也有一些工作对不同任务间节点嵌入的迁移进行了研究。但是提出的方法都是对不同的子结构使用不同的节点嵌入,没有进行参数共享。这种方法天然就是transductive的,不能实现不同数据集间的迁移,不能进行端到端的微调,由于数据的稀疏性也不能捕获到大量多样的邻居/上下文信息。
本文的GNN预训练方法解决了上述挑战,编码了图级别的和节点级别的依赖关系以及结构信息,并且可以共享参数。
6 实验
数据集:
(1)预训练数据集
1、在化学领域
- 从ZINC15数据集中采样了2 million个未标注的分子,用于节点级别自监督的预训练。
- 使用ChEMBL数据集进行图级别的多任务的有监督预训练。
2、在生物领域
- 使用从PPI网络中获得的395K个未标注的蛋白质ego-networks进行节点级别的自监督的预训练。
- 使用88K个标注的蛋白质ego-netowrks进行图级别的多任务的有监督预训练,预测5000个coarse-grained biological functions。
(2)下游的用于分类任务的数据集
1、在化学领域
使用MoleculeNet中的8个二分类的数据集
2、在生物领域
从PPI网络中获取数据
实验任务:图分类(图级别的属性预测)
对比方法:
将本文的预训练策略和两种朴素的基线策略进行比较:(1)在相关的图级别任务上进行有限度的多任务预训练;(2)节点级别的自监督预训练。
实验结果:
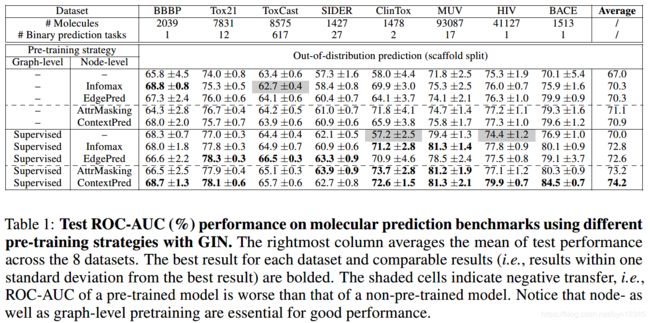
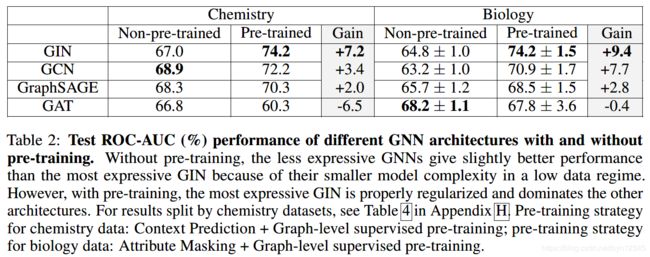
7 总结
本文提出了GNN预训练的策略,这一策略成功的关键在于在节点级别和图级别进行预训练并使用了表示能力强的GNN。
这就确保了节点的嵌入捕获到了局部邻居的语义信息,这些语义信息被汇聚到一起以得到有意义的图级别的表示,而这些图级别的表示又被用于下游任务。
在多个数据集,多个下游任务,使用多种GNN进行了实验,结果表明这一训练策略比没有经过预训练的模型,具有更强的对out-of-distribution的泛化能力。
本文是第一个对图上的预训练进行研究的工作,在图上的迁移学习领域中迈出了重要的一步。
未来的研究方向有:
(1)改进GNN的结构以及预训练和微调的方法,以进一步提高泛化能力。
(2)研究预训练模型学习到了什么有用的信息。
(3)将这一方法应用于其他领域,例如物理、材料科学、生物结构等。
(4)图级别预测的预训练任务中,是否能增加图结构相似性的预测任务。
参考文献
[1] Michael T Rosenstein, Zvika Marx, Leslie Pack Kaelbling, and Thomas G Dietterich. To transfer or not to transfer. In Advances in Neural Information Processing Systems (NeurIPS), Workshop on transfer learning, volume 898, pp. 1–4, 2005.
[2] Keyulu Xu, Weihua Hu, Jure Leskovec, and Stefanie Jegelka. How powerful are graph neural networks? In International Conference on Learning Representations (ICLR), 2019.