【论文解读 EMNLP 2019 | HMEAE】Hierarchical Modular Event Argument Extraction

论文题目:HMEAE: Hierarchical Modular Event Argument Extraction
论文来源:EMNLP 2019 清华、微信AI
论文链接:https://www.aclweb.org/anthology/D19-1584/
代码链接:https://github.com/thunlp/HMEAE
关键词:事件元素抽取(EAE),概念层次,attention,BERT,CNN
文章目录
- 1 摘要
- 2 引言
- 3 模型
- 3.1 Instance Encoder
- 3.2 Hierarchical Modular Attention
- 3.3 Argument Role Classifier
- 4 实验
- 5 总结
- 参考文献
1 摘要
本文解决的是事件元素抽取(EAE)任务。
现有的方法独立地对每个argument进行分类,忽视了不同argument roles间的概念相关性。本文提出了HMEAE(Hierarchical Modular Event Argument Extraction)模型处理EAE任务。
作者为概念层次(concept hierarchy)的每个基本单元设计了一个神经网络模块,然后使用逻辑操作,将相关的单元模块分层地组成一个面向角色的模块网络(modular network),对特定的argument role进行分类。
由于许多的argument roles共享相同的高层次(high-level)的单元模块,argument roles间的关联就得到了利用,有助于更好地抽取出特定的事件arguments。
实验证明了HMEAE可以有效地利用概念层次的知识,效果优于state-of-the-art baselines。
2 引言
(1)任务介绍
事件抽取(EE)通常看成由两个子任务构成:事件检测(ED)、事件元素抽取(EAE)。近些年来,EAE成了EE的瓶颈。
EAE的目的是识别出是事件arguments的实体并对该实体在事件中扮演的角色进行分类。
例如,在句子“Steve Jobs sold Pixar to Disney”中,“sold"触发了Transfer-Ownership事件。EAE的目的是识别出"Steve Jobs"是一个事件元素(event argument),并且该元素的角色为"Seller”。
(2)现有方法的不足
现有的方法都是将元素角色看成是彼此之间相互独立的,忽视了一些元素角色和其他元素的概念相似性。

以图1为例,相比于"Time-within",“Seller"在概念上和"Buyer"更接近,因为它们共享了相同的上级概念"Person"和"Org”。概念层次可以提供额外的有关元素角色间关联的信息,有助于元素角色的分类。
(3)作者提出
作者受先前的层次分类网络[1~3]和神经模块网络(NMNs)[4]的启发,提出了HMEAE模型,利用了概念层次的信息。
HMEAE模型采用了NMNs,模仿概念层次的结构,实现了一种灵活的网络结构,为更好的分类性能提供了有效的归纳偏差(inductive bias)。
如图1所示,作者将概念分为两类:表示抽象概念的上级概念;细粒度的元素角色(argument roles)。一个元素角色可以从属于多个上级概念。
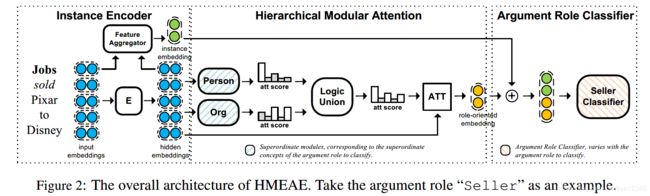
如图2所示,为每个概念设置了一个NMN,并将其组成了一个面向角色的模块网络,以预测每个实体的元素角色:
1)首先,对于每个上级概念,有一个上级概念模块(SCM)来突出和概念有关的上下文信息;
2)然后,对于每个元素角色,使用针对特定角色的逻辑模块整合和其相对应的SCMs,以得到统一的高层次的模块;
3)最终,使用元素角色分类器,预测实体是否扮演了给定的元素角色。
本文的模型将概念层次纳入考虑有以下好处:1)高层次的模块可以有效增强分类器性能;2)不同元素角色共享上级概念模块。
3 模型
HMEAE模型结构如图2所示,由3部分组成:
1)实例编码器(instance encoder):将句子编码成隐层嵌入,并使用特征聚合器将句子信息聚合成统一的实例嵌入;
2)分层模块的注意力(hierarchical modular attention component):生成面向角色的嵌入,以突出参数角色上级概念的信息;
3)元素角色分类器(argument role classifier):使用实例嵌入和面向角色的嵌入,针对该实例估计出特定元素角色的概率。
3.1 Instance Encoder
将一个实例表示为 n n n个单词的序列: x = { w 1 , . . . , t , . . . , a , . . . , w n } x={\{w_1, ..., t, ..., a, ..., w_n}\} x={w1,...,t,...,a,...,wn}, t , a t, a t,a分别表示触发词和候选元素。触发词是用已有的ED模型选择出来的,与本文无关。句子中的每个命名实体都是一个候选元素。
(1)句子编码器
将单词序列编码成隐层嵌入:
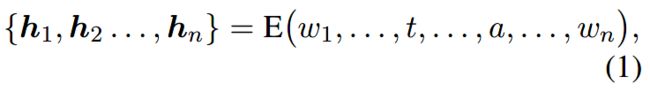
其中 E ( ⋅ ) E(\cdot) E(⋅)是一个神经网络,本文使用CNN和BERT作为编码器。
(2)特征聚合器
将隐层嵌入聚合成一个实例嵌入。本文使用dynamic multi-pooling作为特征聚合器:
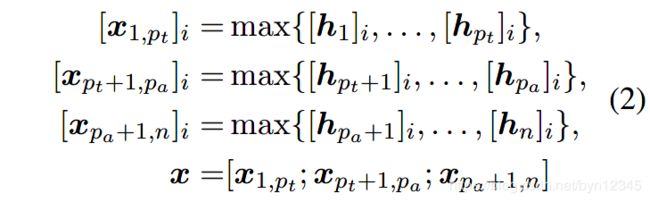
其中, [ ⋅ ] i [\cdot]_i [⋅]i表示向量的第 i i i个值; p t , p a p_t, p_a pt,pa分别是触发词 t t t和候选元素 a a a的位置。将3个piecewise max-pooling结果拼接起来作为实例的嵌入 x x x。
3.2 Hierarchical Modular Attention
如图2所示,给定隐层嵌入 { h 1 , h 2 , . . . , h n } {\{h_1, h_2,..., h_n}\} {h1,h2,...,hn},上级概念模块(SCM)为每个隐层嵌入给出了一个注意力得分,以建模其与特定上级概念的相关性。
由于一个元素角色可以从属于多个上级概念,所以使用一个逻辑模块(logic union module)以结合源于不同上级模块的注意力分值。
对于每个元素角色,将其上层概念模块组合成完整的hierarchical modular attention模块,构建面向角色的嵌入。
(1)上级概念模块(SCM)
对于特定的上级概念 c c c,使用可训练的向量 u c u_c uc表示其语义特征。作者采用了多层感知机(MLP)来计算注意力分值。
首先计算隐层状态:
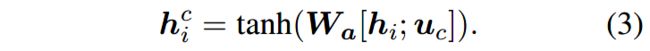
然后,进行softmax操作,为每个隐层嵌入 h i h_i hi得到对应的注意力分值:
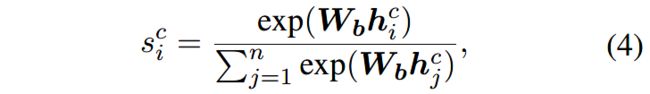
其中, W a , W b W_a, W_b Wa,Wb是可训练的矩阵,并且在不同的SCM间共享。
(2)Logic Union Module
给定一个元素角色 r ∈ R r\in \mathcal{R} r∈R,定义它的 k k k个上级概念为 c 1 , c 2 , . . . , c k c_1, c_2, ..., c_k c1,c2,...,ck,针对 h i h_i hi的相应的注意力分值为 s i c 1 , s i c 2 , s i c k s^{c_1}_i, s^{c_2}_i, s^{c_k}_i sic1,sic2,sick。
对这些注意力分值求均值,得到面向角色(role-oriented)的注意力分值:
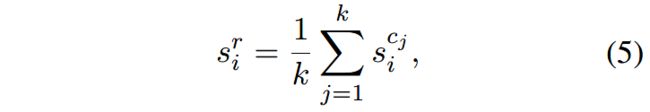
然后使用上面计算出的面向角色的注意力分值作为权重,对所有的隐层嵌入进行加权求和,得到面向角色的嵌入:
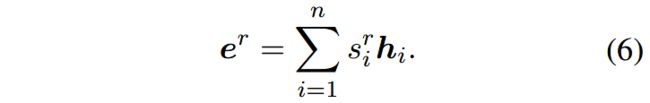
3.3 Argument Role Classifier
将实例嵌入 x x x和实例的面向角色的嵌入 e r e^r er作为分类器的输入,估计给定实例 x x x的条件下,角色 r ∈ R r\in \mathcal{R} r∈R的概率。其中, r \mathbf{r} r是元素角色 r r r的嵌入。
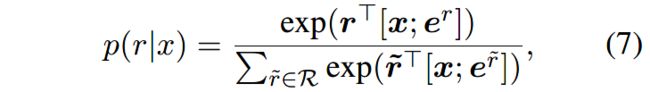
目标函数定义如下:
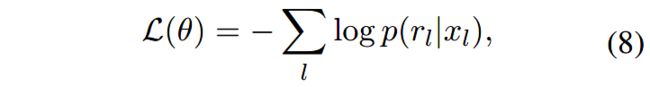
4 实验
(1)数据集
ACE 2005, TAC KBP 2016
(2)概念层次的设计
使用8个不同的上级概念,人工设计了概念层次。
(3)对比方法
1)基于特征的方法
- Li’s joint
- RBPB
2)神经网络方法
- DMCNN, DMBERT:和文本模型大致一样,但是缺少hierarchical modular attention模块。
- JRNN
- dbRNN:使用了句法信息
- HMEAE(CNN)
- HMEAE(BERT)
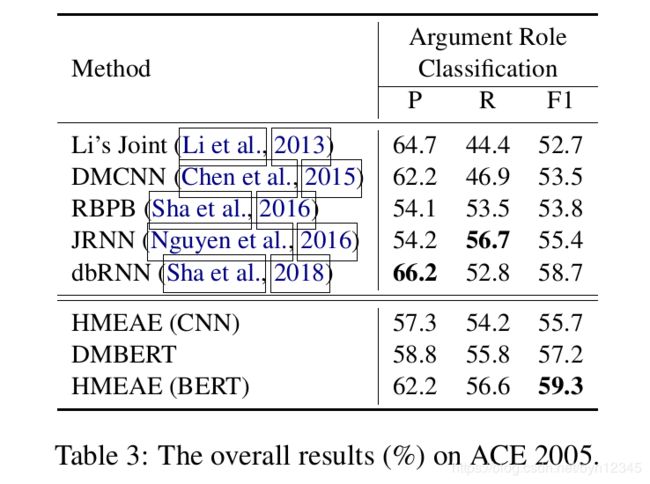
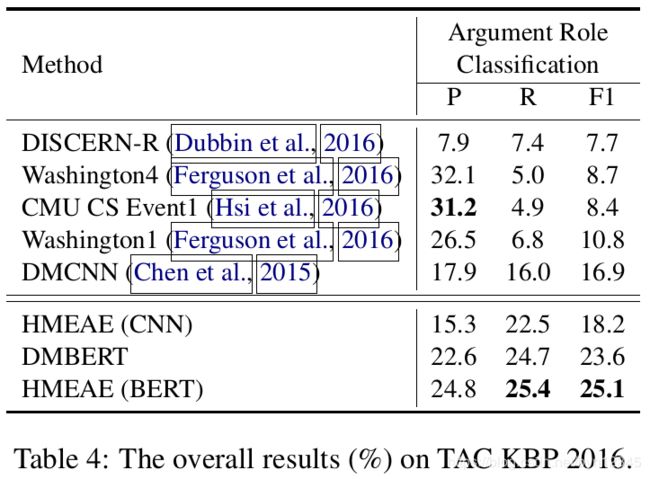
(4)实验结果
在两个数据集上进行实验,不同方法的结果如下:
从ACE 2005数据集中随机采样了一个句子,该句在HMEAE (BERT)模型中的注意力分值 s i c s^c_i sic可视化如图3所示。可以看出单词隐层嵌入的注意力分值,在与其相关的上级概念上得分较高。这表明,由于上级概念模块(SCM)是共享的,所以无需经过专门数据的训练,SCM就可以很好地捕获概念特征。

5 总结
本文提出了HMEAE模型,用于处理EAE(事件元素抽取)问题(面向的是argument roles的分类问题)。
采用灵活的模块网络(modular networks),利用了和元素角色(argument roles)相关的层次概念,作为有效的归纳偏置(inductive bias)。
实验证明了HMEAE的有效性,并在某些度量上超越了state-of-the-art。
未来工作:在使用本文模型的基础上,根据人的经验,利用更多样的inductive bias,来提升一些扩展任务。
这篇文章的亮点在于使用到了概念层次的信息,有助于EAE中的argument roles分类问题。
模型在建模的过程中以一个实例作为对象,也就是一个句子。先使用CNN或BERT将句子建模成隐层嵌入序列;然后根据触发词和候选元素(句中实体)的位置,使用dynamic multi-pooling进行了特征的聚合,得到了实例的嵌入。
接着,在上级概念模块(SCM)中使用注意力机制,给每个隐层嵌入分配一个注意力分值,表示该隐层嵌入和该上级概念的关联性程度。然后,给定角色,对隐层在不同上级概念中的注意力分值求平均,得到每个token i i i针对该角色的注意力分值。再使用这个注意力分值作为权重,对所有的隐层嵌入进行加权求和,得到输入实例(句子)的面向角色的嵌入。
最后,将实例的嵌入和实例的面向角色的嵌入拼接起来作为分类器的输入,和元素角色的嵌入相乘,再经过一层softmax,为输入的实例 x x x预测角色 r r r。
本人没有看过代码,光看论文个人感觉有一些不足之处。模型是对一个句子进行argument role的预测的,而一个句子中可能有多个argument。如果句子中有多个argument,分类器给句子分配了概率最大的role,那这个role对应哪个argument呢?如果是根据句子中的候选argument数 m m m选择前 m m m个概率最大的role,那这些role该怎么分配给对应的argument呢?我觉得作者忽视了这个问题,只考虑句子中有一个触发词、一个参数的情况。因为3.1节中定义输入序列时,是写了一个 t t t(触发词)和一个 a a a(argument),没有提到有多个 t t t或多个 a a a的情况。
参考文献
[1] Xipeng Qiu, Xuanjing Huang, Zhao Liu, and Jinlong Zhou. 2011. Hierarchical text classification with latent concepts. In Proceedings of ACL-HLT, pages 598–602.
[2] Kazuya Shimura, Jiyi Li, and Fumiyo Fukumoto. 2018. HFT-CNN: Learning hierarchical category structure for multi-label short text categorization. In Proceedings of EMNLP, pages 811–816.
[3] Xu Han, Pengfei Yu, Zhiyuan Liu, Maosong Sun, and Peng Li. 2018. Hierarchical relation extraction with coarse-to-fine grained attention. In Proceedings of EMNLP, pages 2236–2245.
[4] Jacob Andreas, Marcus Rohrbach, Trevor Darrell, and Dan Klein. 2016. Neural module networks. In Proceedings of CVPR, pages 39–48.