Lanenet 车道线检测网络模型学习(论文解读+官方模型)
本文讲解的是用于车道线检测的一个网络结构叫lanenet,
转载请备注,多谢哈|!
2018.2发表出来的,文章下载地址:https://arxiv.org/abs/1802.05591
github上代码:https://github.com/MaybeShewill-CV/lanenet-lane-detection
官方训练的模型文件(我下载的官方模型是2019.6.26 版本的)我上传至百度盘了(造福不了的朋友):
链接:https://pan.baidu.com/s/1xlELGM0O9K1U8bITlxUjnA 提取码:o3g3
论文标题:Towards End-to-End Lane Detection: an Instance Segmentation Approach
作者:Davy Neven Bert De Brabandere Stamatios Georgoulis Marc Proesmans Luc Van Gool ESAT-PSI, KU Leuven
摘要——当今很多车都带有辅助驾驶员的驾驶的功能,比如车道保持功能。该功能能使车辆保持在车道间的适当位置,这个功能对于有潜在车道偏离或者自动驾驶中的轨迹规划和决策都至关重要。传统的车道检测方法依赖于高度定义化,手工特征提取和启发式方法,通常是需要后处理技术,而这往往会使得计算量大,不利于道路场景多变下的应用扩展。最近越来越多的方法是借助深度学习建模,为像素级的车道分割做训练,即使当在大的感受野中并无车道标记的存在。尽管这类方法有他们的优势,但他们受限于检测一个预训练的,固定数量的车道线(比如本车道)问题,且无法处理车道变化。 本文,我们突破了前面提到的限制,将车道检测问题转为实例分割问题,从而每个车道线各自形成一个实例,这样就能够实现端到端的训练了。在分割车道线用于拟合车道之前,我们进一步提出采用一个已学习好的透视变换,在图像上做这种调整,与固定的鸟瞰图做对比。通过这么做,我们确保在道路平面变化下的车道线拟合的鲁棒性,不同于现有依赖于固定的且预先定义的透视变换矩阵的方法。总结就是,我们提出了一种快速车道检测的算法,运行帧率达50fps,能够处理多数车道和车道变换。本算法在tuSimple数据集中验证过且取得较有优势的结果。
1.介绍(本人不做一字不漏的翻译,挑重点的写出来)
传统车道线检测方法(如下)主要依赖于高度定义化,手工特征提取和启发式方法以确保车道线分割出来。
[4] A. Borkar, M. Hayes, M. T. Smith, A Novel Lane Detection System With Efficient Ground Truth Generation. IEEE Trans. Intelligent Transportation Systems, vol. 13, no. 1, pp. 365-374, 2012.
[9] H. Deusch, J. Wiest, S. Reuter, M. Szczot, M. Konrad, K. Dietmayer, A random finite set approach to multiple lane detection. ITSC, pp. 270-275, 2012.
[15] J. Hur, S.-N. Kang, S.-W. Seo, Multi-lane detection in urban driving environments using conditional random fields. Intelligent Vehicles Symposium, pp. 1297-1302, 2013.
[17] H. Jung, J. Min, J. Kim, An efficient lane detection algorithm for lane departure detection. Intelligent Vehicles Symposium, pp. 976-981, 2013.
[33] H. Tan, Y. Zhou, Y. Zhu, D. Yao, K. Li, A novel curve lane detection based on Improved River Flow and RANSA. ITSC, pp. 133-138, 2014.
[35] P.-C. Wu, C.-Y. Chang, C.-H. Lin, Lane-mark extraction for automobiles under complex conditions. Pattern Recognition, vol. 47, no. 8, pp. 2756-2767, 2014.
较为常见的手工特征提取是基于颜色的,结构的,bar filter, ridge feature等,结合hough 变换和粒子滤波或Kalman滤波。当识别出车道线之后,利用后处理技术过滤掉误检和成组分割在一起的情况以得到最终车道线。
整体的车道检测系统可参考这篇文章:[3] A. Bar-Hillel, R. Lerner, D. Levi, G. Raz, Recent progress in road and lane detection: a survey. Mach. Vis. Appl., vol. 25, no. 3, pp. 727-745, 2014.
最近出现的方法是用深度网络做dense 预测以替代人工提取特征的方法,比如像素级的车道线分割。下面是当前深度网络相关研究——
Gopalan等人用像素-层次结构特征描述子来做上下文信息建模并且用增强算法来选择相关上下文信息特征做车道标记检测。Kim and Lee 将CNN和RANSAC 算法结合从边缘图像来检测车道,他们用CNN主要是为了图像增强,而且只有在道路场景复杂情况下,例如路边树,栅栏或十字路口。
Huval等人提出现有的CNN模型能用于高速自动驾驶,得到端到端的CNN能够用于车道检测与分类。
He等人介绍了一种双视觉CNN网络-DVCNN,利用前视和俯视图像可排除误检和去除非车道结构的目标。
Li等人利用多目标深度卷积网络用于寻找车道的几何结构属性(如位置,方向)并结合RNN来检测车道线。
Lee等提出多任务网络能同时检测和识别车道和道路标记,即便在不好天气和低光照条件。
【上诉深度网络类方法的共性问题】然而产生的二值化车道线分割图仍需要分离到不同的车道实例中。为处理这个问题,一些方法采用后处理来解决,主要是用启发式的方法,比如几何特性。但启发式方法计算量大且受限于场景变化鲁棒性问题。另一条思路是将车道检测问题转为多类别分割问题,每条车道属于一类,这样能实现端到端训练出分类号的二进制图。但该方法受限于只能检测预先定义的,固定数量的车道线。此外,由于每个车道都有一个指定的类别,所以它无法处理车道的变化。
论文思路:受语义分割和实例分割任务中dense预测的启发,将车道检测问题转为实例分割问题,每个车道线形成独立的实例,但都属于车道线这个类别。我们设计了一个带分支结构的多任务网络,如车道实例分割,由一个车道分割分支和一个车道embedding分支构成能够实现端到端训练。车道分割分支输出两类:背景或车道线;车道embedding分支进一步将分割后得到的车道线分离成不同车道实例。
当得到车道实例(即知道哪些像素属于哪条车道)后,就需要对每条线做参数描述。曲线拟合算法作为这个参数描述,流行的拟合模型有三次多项式,样条曲线,回旋曲线。为了提高拟合质量且保持计算效率,通常将图像转到鸟瞰图后做拟合。最后再逆变换到原图即可。但有个问题是:这个透视变换矩阵会受地面线影响(如上坡)。本文在做曲线拟合前先训练一个网络用于生成透视变换矩阵系数以解决道路平面变动的影响。论文模型的主框架如下图:

文章作者对论文的总结如下:

2. 方法
A lanenet网络
二值化分割
上图中的下面那个分支就是用于训练输出得到一个二值化的分割图,白色代表车道线,黑色代表背景。为了构建GT分割图,我们将每天车道线的对应像素连成线,这么做的好处是即使车道线被遮挡了,网络仍能预测车道位置。给分割网络用标准的交叉熵损失函数做训练的。由于目标类别是2类(车道/背景)高度不平衡(我的理解就是背景较车道线的像素多太多),我们应用 bounded inverse class weighting。可参考论文:[29] A. Paszke, A. Chaurasia, S. Kim, E. Culurciello, ENet: A deep neural network architecture for real-time semantic segmentation. CoRR abs/1606.02147, 2016.
实例分割
当分割分支识别得到车道后,为了分离车道像素(就是为了知道哪些像素归这条,哪些归那条车道),我们训练训练了一个车道instance embedding分支网络(上图上面那个网络)。我们用基于one-shot的方法做距离度量学习(参考论文:[5] B. De Brabandere, D. Neven, L. Van Gool. CoRR abs/1708.02551, 2017.),该方法易于集成在标准的前馈神经网络中,可用于实时处理。利用聚类损失函数,instance embedding分支训练后输出一个车道线像素点距离,归属同一车道的像素点距离近,反之远,基于这个策略,可聚类得到各条车道线。具体实现的原理是

就是说有两股力在做较量,一股是方差项,主要是将每个embedding往某条车道线的均值方向拉(激活拉这个动作的前提是embedding太远了,远于阈值δv就开始pull),另一股是距离项,就是使两个类别的车道线越远越好(激活推这个动作的前提是两条车道线聚类中心的距离太近啦,近于阈值δd就push)。最后这个总损失函数L的公式如下:
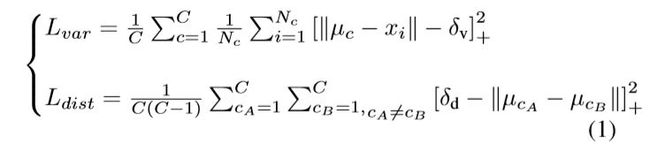
终止聚类的条件是:车道聚类(即各车道线间间距)中心间距离>δd,每个类(每条车道线)中包含的车道线像素离该车道线距离<δv。
Once the network has converged, the embeddings of lane pixels will be clustered together (see fig. 2), so that each cluster will lay further than δd from each other and the radius of each cluster is smaller than δv.
聚类
设置 δd > 6δv为迭代终止条件,使上述的loss做迭代。
架构
网络共享前面两个stage。分割分支输出单通道的图像。embedding分支输出N通道的图像。每个分支的权重相同。
LaneNet only shares the first two stages (1 and 2) between the two branches,leaving stage3 of the ENet encoder and the full ENet decoder as the backbone of each separate branch. The last layer of the segmentation branch outputs a one channel image (binary segmentation), whereas the last layer of the embedding branch outputs a N-channel image, with N the embedding dimension. This is schematically depicted in Fig. 2. Each branch’s loss term is equally weighted and back-propagated through the network.
B 用H-NET做车道线曲线拟合
lanenet网络输出的是每条车道线的像素集合。常规处理是将图像转为鸟瞰图,这么做的目的就是为了做曲线拟合时弯曲的车道能用2次或3次多项式拟合(拟合起来简单些)。关于这个变换矩阵的问题上面已经描述过了,意思就是通过H-Net网络学习得到的变换矩阵参数适用性更好(可看下图)。

其中转换矩阵H是拥有6个自由度的矩阵。

曲线拟合:

这部分讲的有点细,大致意思就是将原图上车道线像素点P通过H-Net学习得到的变换矩阵H,变换到俯视图下的像素点坐标P'。在变换后的图像上通过给定的y'算出对应的x',将x'通过H得到变换前原图上对应坐标x。拟合的思想是用最小平方项拟合。那么loss的定义就是反推回来的x和原图上真实的x的差方。

其中H-Net结构构件由连续的3x3卷积,batchnorm和ReLU构成,用的是最大池化,最后有2个全连接层。具体见下图——
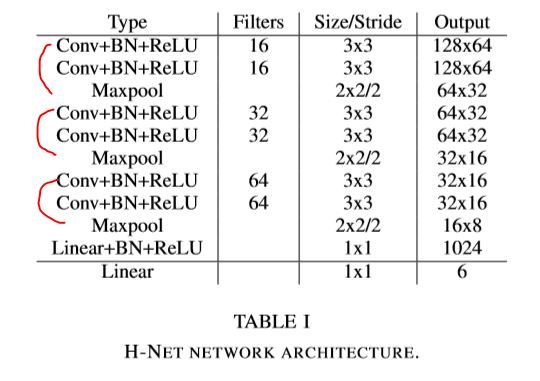
测试数据集
用的是TuSimple的车道线数据集,3626张训练图像和2782张测试图像,采集自较好和稍好的气候情况。包含白天不同时刻2,3,4车道或较多的高速道路。每张图都提供了该图前19帧图像(不过这19帧是未标注的),标注的图像是json格式的。指示在许多离散的y坐标上对应的x位置。每张图包含当前车道(左右车道)的车道线标准信息(共计4条线),测试集也如此,当改变车道时,会出现第5条车道线。
准确性的定义是每张图gt点数中正确点所占的比例。所谓预测正确的点是那些与gt点距离小于一定阈值的就认为预测准确。作者还给出False positive和false negative的定义作为模型好坏的评测标注。

模型网络设置(帧率达50fps)
LaneNet
embedding维度是4(输出4通道),δv=0.5,δd=3,输入图像resize到512x256,采用Adam优化器,batchsize=8,学习率=5e-4;
H-Net
3阶多项式,输入图像128x64,Adam优化器,batchsize=10,学习率=5e-5;
作者最后的结论就是用H-Net比用固定的转换矩阵要好,用3阶多项式拟合要比2阶好,用了透视变换比不用好~总之当前模型框架要出色。