Parallel Architecture\Multi-Core Cache Coherence
- Big Picture
- Multi-Core ProcessorMCP
- Multi-Computer ClusterMCC
- Multi-Core Cache Coherence
- Cache Coherence Problem
- Cache Coherence Protocols
- Write Update
- Write Invalidate
- Bus-based Snoopy Protocol
- MI Protocol
- MSI Protocol
- MESI Protocol
- MOESI Protocol
- Directory-Based Protocol
转载请注明出处:http://blog.csdn.net/c602273091/article/details/53558509
Big Picture
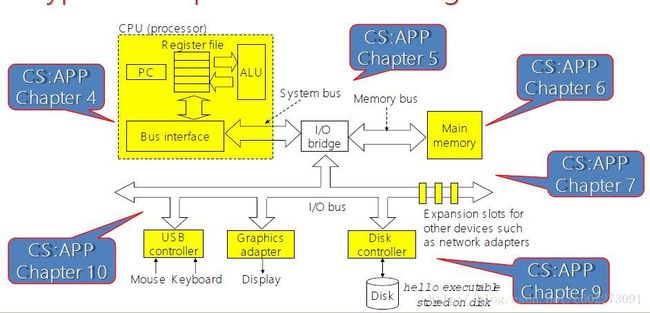
整个的计算机系统框架如下:

红色的线就是软硬件的分割线。
Multi-Core Processor(MCP)
Key: share memory.
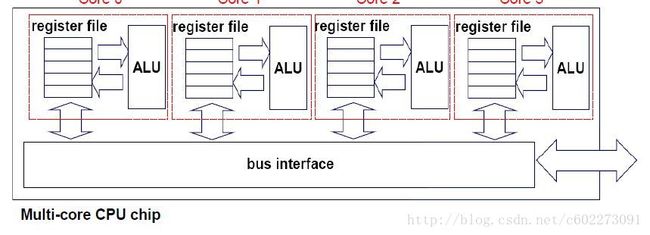
很多个cores,它们共享内存。它们协同工作,完成任务。
processor和core要注意它讲的场合,意思有些不同。
为什么需要多核呢?
04年之前处理器性能还是可以的,能够达到摩尔定律。这就是晶体管技术、更好的系统调度、更高的频率,减少了CPI,提高了IPC。但是这样的性能提高是有限的,功耗也越来越大。( P=CV2f )以及成本极大。一个OOO设计,需要100个工程师,3~5年,成本太大。05年以后,多核处理器就出现商用了。频率没有提高,功耗也没有提高,但是多核使得计算机性能大幅提高。
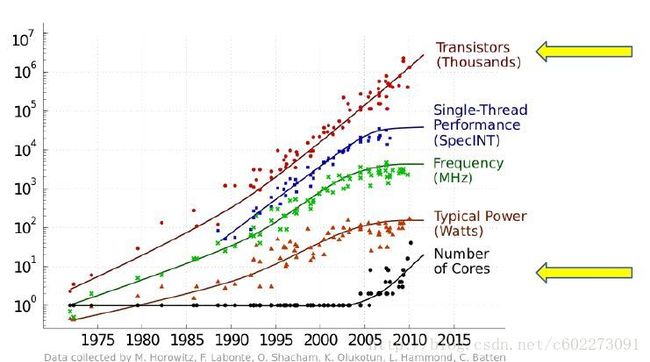
多核使用的优缺点?
优点就是计算机性能提高了。缺点就是程序设计从单线程变成了多线程。而且漏电电流还是比较大。

上图是Superscala和mcp的对比,可以看出,在可并行化不高的程序中,superscalar的加速更明显。在可以并行化更大的地方,mcp的加速更快。
在MCP设计中,比较重要的就是cache的设计。有以下的情况:

在MCP设计中,还需要考虑核与核之间的连接问题。

移动端需要处理的工作统计:

在mcp中,有一种特殊的存在:big.little。这种技术可以使得需要高性能的工作在大的处理器进行,小的工作在小核进行,这样就可以比较好节约功耗了。
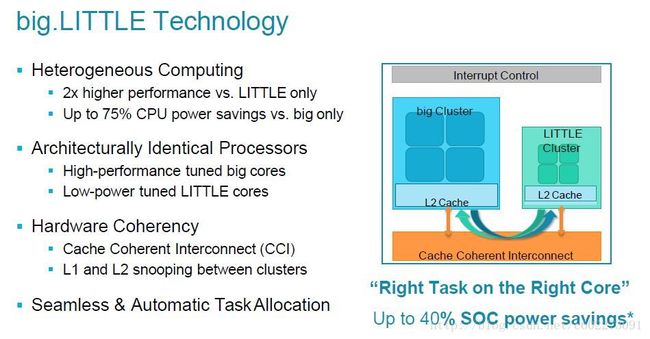
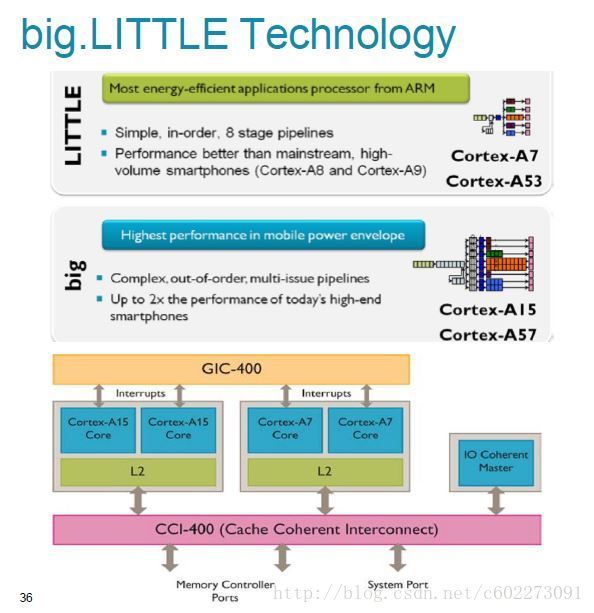
在三星note手机里的八核,就是4个大的核和四个小核。
Multi-Computer Cluster(MCC)
什么是MCC呢?

它们通过message passing进行消息传递。可以使用网络编程进行通信,这个在csapp的网络编程中有介绍具体细节。
Key: share file system.
很多个计算机协同计算,共享文件系统。比如比较出门的就是云计算系统。各个计算机之间通过网关进行通信。这些计算机可以有不同的系统,不同的架构。

在MCC架构中,有个需要具体介绍:Beowulf Cluster
Beowulf Cluster是由一个server节点和多个client节点组成的集群系统。client作为一个节点,每个节点都要一样的系统。

这种集群系统的属性如下:

它的应用:

对集群系统做一个总结,说一下需要注意的事情。

另外,说一下Google Cluster。
首先是设计原则:

当我们在浏览器输入google.com的时候,整个过程如下:

首先是通过DNS域名服务器把域名映射成IP地址。像twitter,它们的服务器就有好几个IP地址。然后映射成IP地址之后,就会通过socket建立链接。然后通过HTTP协议把在浏览器输入的请求发过去,直到被服务器接收。服务器解析请求,然后返回。现在的HTTP请求大都是GET,协议版本是1.1。
google服务器内部的架构大致如下:

通过网络爬虫,爬取各个文章的词的权重,组成等等。然后把请求的关键词和所有的数据进行匹配。然后根据匹配程度,把文档从服务器取出,以html格式封装好发送客户端。不过它的这种inverted index+map reduce的方法改了,现在是Caffeine + BigTable的方法。
这一节是书csapp上没有的,是John P. Shen他写的书上的一小部分。他算是给我们增长知识吧,懂得是这个东西。具体细节以及怎么实现那就要看自己有没有这方面的兴趣了。
Multi-Core Cache Coherence
Cache Coherence Problem
cache的问题就是数据同步的问题。
如下:
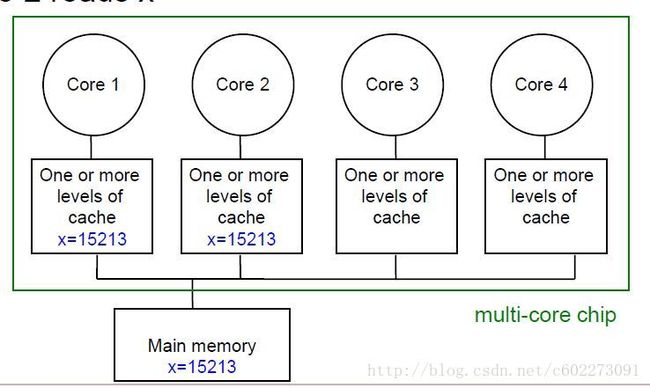
如果其中一个修改:
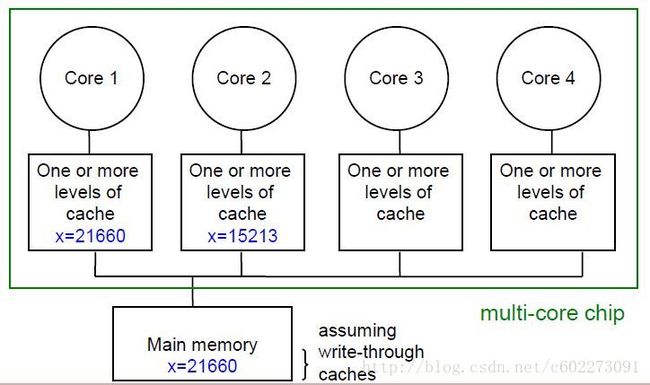
那么这种情况下,如何进行数据同步呢?core 2需要使用x的时候怎么才能用到正确的呢?
Cache Coherence Protocols
Cache同步协议就是使得各个核使用数据是有效的。想想可知,想要数据同步,那么就可以进行将更新的值发送给每个核;或者每个核会记录它里面的数据的有效性而进行更新。
Write Update
就是数据x在核a修改后,发送数据给有数据x的缓存的核进行更新。

Write Invalidate
如果数据x在核a被修改后,发送信号给由它缓存的核b等把这块的cache的无效化。然后b要用x的时候就会miss,从内存中获取。
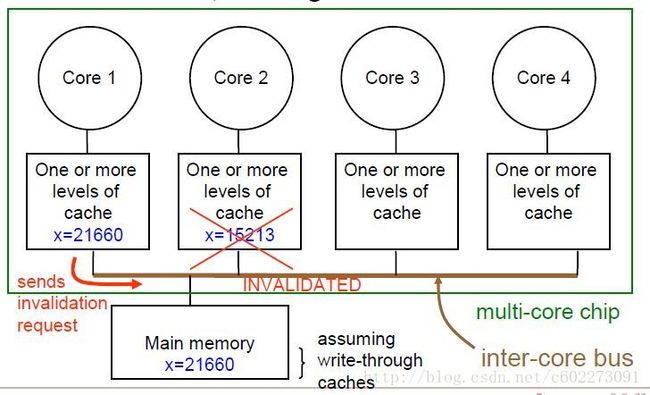
以上两种没有绝对的好坏,需要考虑到当前核的进程是否需要该数据,以及bus的带宽等等因素。
Bus-based Snoopy Protocol
基于监听的协议都会发信号广播在总线上,所有的核和内存都可以监听和反映。
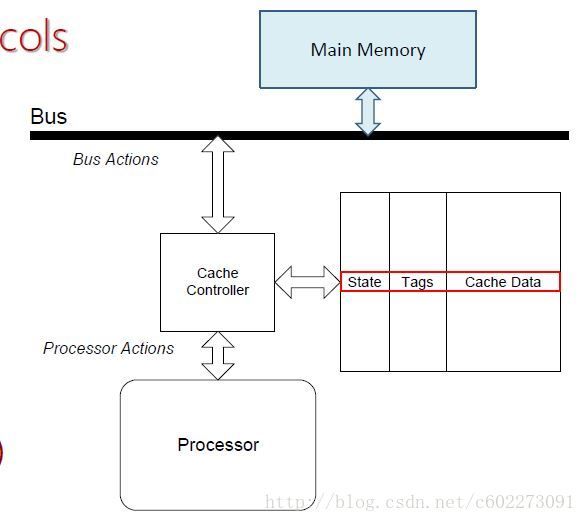
MI Protocol
MI协议用一个状态机表示:
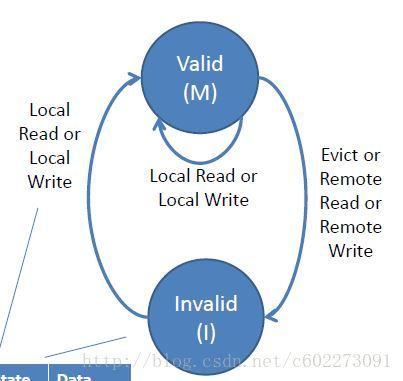
各个状态的描述:

这个协议很有问题,每次remote读一次,然后cache里的数据就无效了,极大的浪费。为了解决这个问题,在MI协议的基础上,增加了一个share state。请看下面。
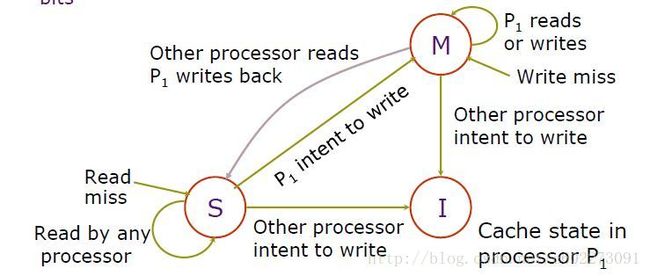
MSI Protocol
对于多核处理器中的其中一个核它的MSI协议可以写成以下FSM。这里注意的是如果cache miss,就从memory中把数据load进来,所以到了share状态。
cache的组成如下:

状态有三种所以需要2 bits。
看一个双核处理器:
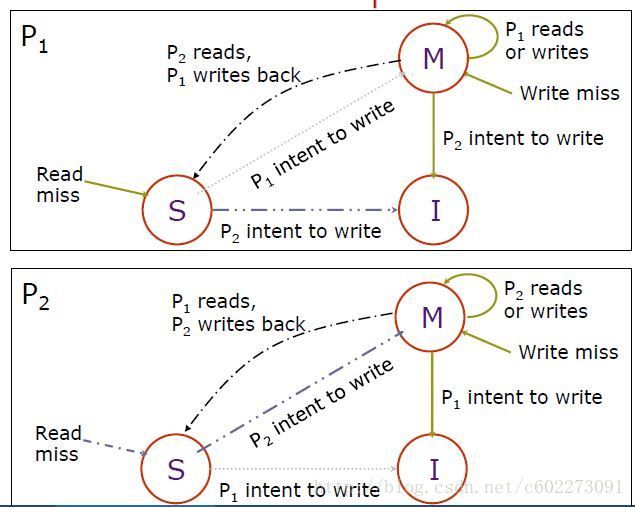
一个核的cache的状态由两边决定,一边是与core通信,一边是监听bus。
其状态机如下:

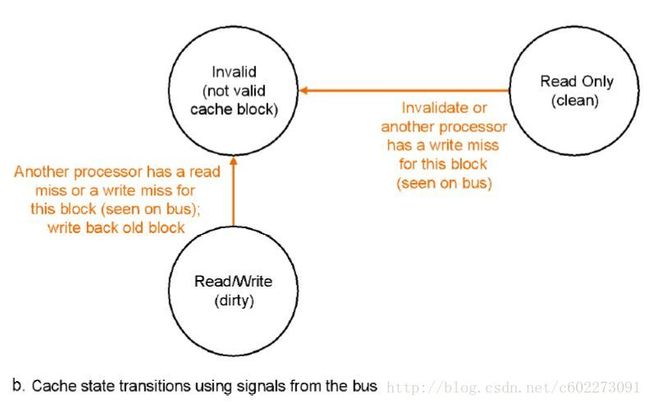
把以上写成状态表:
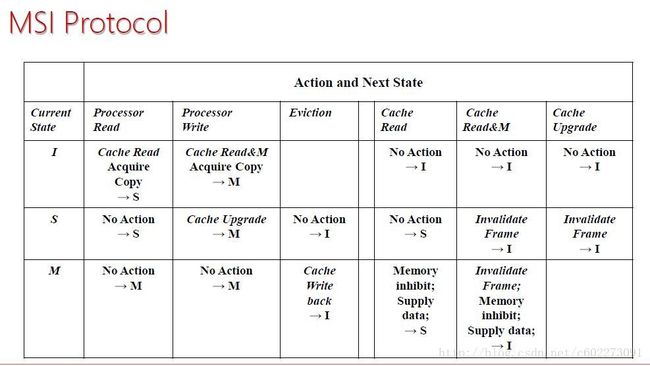
这个状态表是在上面状态机基础上得到。它要表现的是左边和处理器通信;右边表现的是它监听bus上的信号进行状态转换。
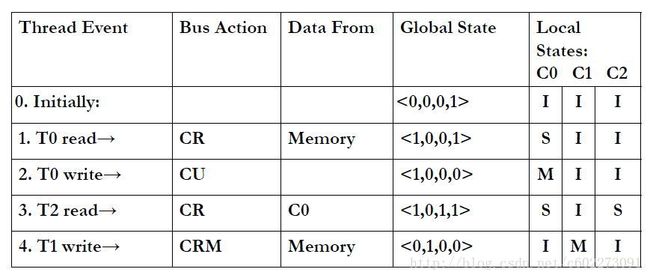
举个例子,加深对MSI的印象。四个global state最后一个是memory的状态。
MESI Protocol
在MSI协议的基础上,加入了写的exclusive状态。
它的操作就是:

这个协议用在了intel的多个处理器上,这门课的其中一个老师John. P. Shen曾经是intel micro-architecture lab的Director。(没想到他这么牛逼)
各个状态的表示:

MESI协议描述如下:
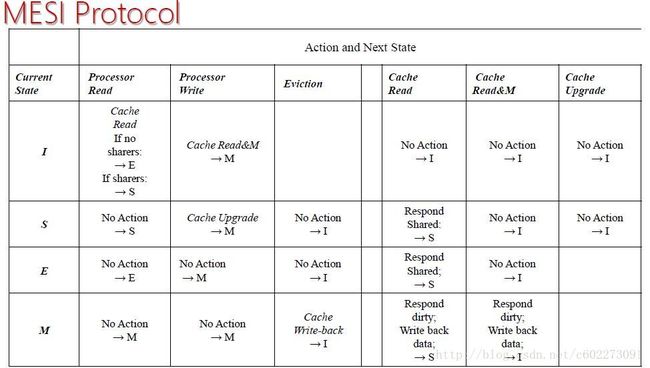
举一个例子:对照上面的表格很快就可以有答案。
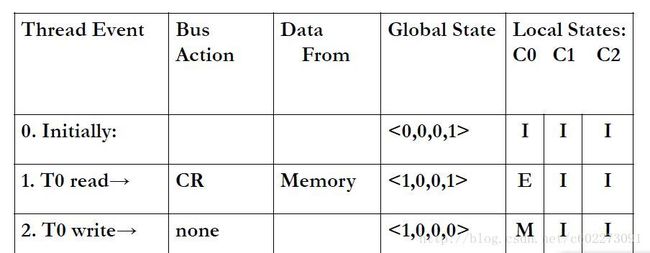
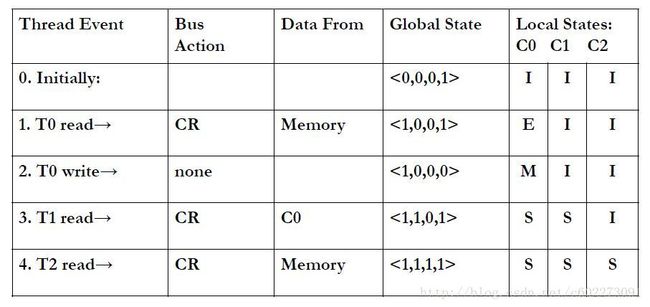
在数据传递的时候,各个核之间存在有的是有共享总线和没有共享总线的情况。根据共享情况不同,需要另外的核的core就需要以不同的方式获取它需要的数据。

再看一个例子:
MOESI Protocol
在MESI协议中,处于S状态的cache是不能进行cache-2-cache的传递,导致了有的core读数据需要从memory读取,这样很浪费。所以在MESI的基础上,增加了一个owner bit。
它的状态如下:


状态表:
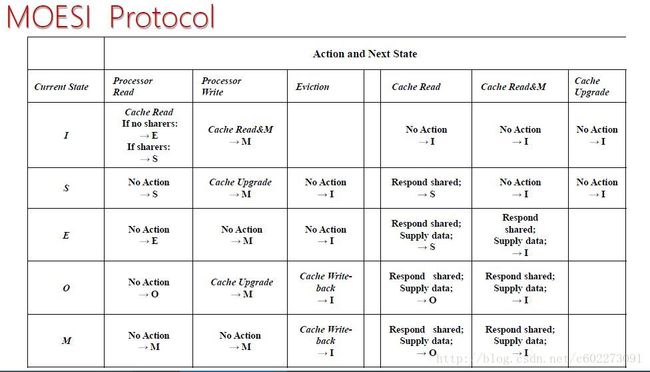
举一个例子:

我们可以发现,使用MOESI协议,在共享总线上如此多的信号,而且都是广播类型的。这样的话监听信号的core怎么分辨出来呢?
这里就用到了probe filter和directory-based Coherence。

Directory-Based Protocol

directory没有研究了,具体去看这门课的PPT或者去买Jhon. P. Shen写的书吧。
The image Is from CMU 18-600 course 18-600.
If U want to see the video, click here