AutoGluon Tabular 表数据全流程自动机器学习 AutoML
论文链接:
https://arxiv.org/abs/2003.06505
代码链接:
https://github.com/awslabs/autogluon
背景
表数据的AutoML近几年很火,但是目前没有一个框架做到了集大成,各有一些特色,但效果也一言难尽,比赛中选手常常用到一些可以提升效果的技术,之前的AutoML框架也都没有过多关注,关注点主要放在了模型选择和超参数调节上。
这篇文章是awslab在前两天(13 Mar 2020)挂在了arxiv上,还没有看到机器之心,新智源等媒体的跟进,毕竟是又一大厂的力作,可能马上就又上头条了吧hh。
看完这篇文章的我的评价是:对当前的主流框架做了一个很好的梳理,给了一个不错的baseline给大家当靶子,关注了之前AutoML框架少关注的stacking的过程,效果还可以,接口设计的很优雅,做了比较贴心的数据预处理,支持断点恢复,支持约束训练时间。
接下来我按照pipeline串一下逻辑。
Pipeline
from autogluon import TabularPrediction as task
predictor = task.fit("train.csv", label="class")
predictions = predictor.predict("test.csv")
接口设计的比较优雅,但这其实大多数AutoML框架都可以,它的一个和之前不一样的点在于参数中指定了label,根据label列的内容推断任务类型,如果这一列有浮点数,那可能是回归,如果都是整数,或者字符串等,可能是分类任务,如果只出现了两种值就是二分类,否则就是多分类。
fit的接口可以支持配置五个主要的参数,是否调超参,是否stacking,训练时间限制,验证效果的metric。最后一个参数是否继续旧的训练,可以利用上一次训练留下的断点继续上一次的任务。
data preprocessing
根据label列自动推断任务类型。
然后分了两次数据预处理,model-agnostic 和 model-specific,字面意思,agnostic的数据预处理就是不论什么模型都要做,specific的数据预处理就和你后面要使用的模型有关,【这个名字起的好啊,我自己的代码里面一直都是1st 2nd来区分的,一直不知道叫什么】
model-agnostic
将数据类型进行分类 numeric, categorical, text, or date/time,
没有被分类的数据将会被删除,numeric, categorical, data/time都很好区分,text怎么区分呢?
超过三个不相邻的空格的字符串就是text,不然就是categorical。
text 列会被转换成 n-gram 连续值向量(取高频词),
data/time列会被转成统一的类型(原文是suitable numeric values),我自己的代码实现是直接转换成了时间戳。
对于缺失值,它会生成一列Unknown,就是我们平时的isnan特征。
model train
模型空间和其它框架差不多,就是大家常用的gbm,随机森林等等,但是有一个base model它有一点创新,就是经过一点改进的神经网络。
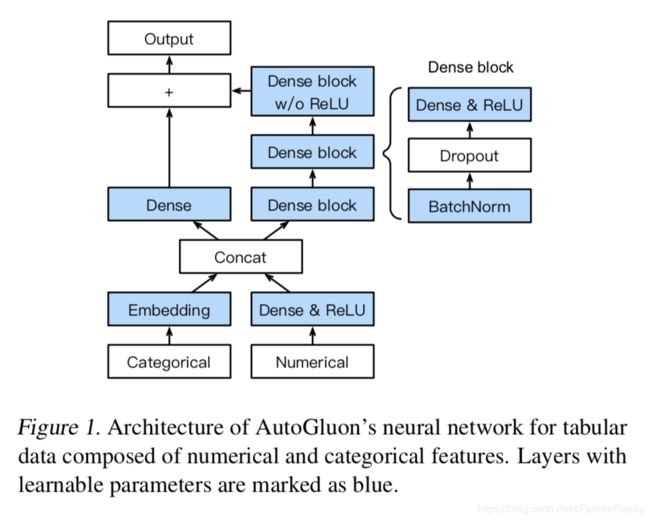
神经网络学到的决策边界和xx是很不一样的,所以将他们ensemble起来是可以对ensemble有比较大的提升,对每一个categorical特征,都单独进行embedding,embedding的维度取决于这个特征出现了多少种值,然后编码后的categorical的向量和numerical的向量concat起来,如上图,它会连到一个3层的feedforward network,也会通过linear skip-connection 直接连到输出。它是第一个通过对每个离散值进行编码并直接接到输出的AutoML框架。
model ensemble
这一部分是这个框架的重点:
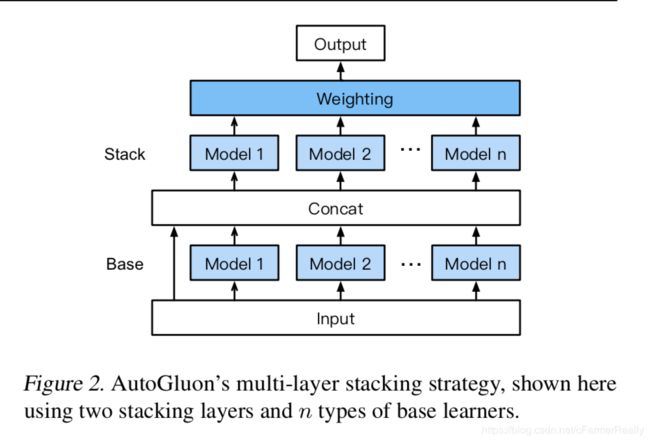
ensemble是拿到了多个模型的输出后,通过对这些输出的处理得到一个最终的结果,希望这个结果是结合了各个模型的优点,更稳定的,ensemble分多种方式,最简单的ensemble就是把每个模型的输出取平均。
stacking是比赛中经常会用到的ensemble技巧,可以简单的理解为是通过一个模型来学习拿到ensemble的过程,stacking非常容易过拟合,autogluon用两个技巧解决过拟合的问题。
如上图,ensemble分多层,每一层的输入是前一层模型的输出,为了防止过拟合,每一层的输入还包括上一层的输入,另一个点是它多了一个Repeated k-fold Bagging 的过程,就是说它通过将多次不同数据的切分的结果做一次平均来使得结果更稳定,伪代码如下:

在ensemble过程中,每个模型训练结束后都会落盘,这样程序即使以外终止退出,也可以从checkpoint恢复,模型训练开始时会预计训练时间,如果超过用户配置的训练时间,将会自动进行下一层的模型ensemble。
他们的多个模型的训练时串行的,因为并行的话很有可能导致内存的问题。