BASNet: Boundary-Aware Salient Object Detection论文学习
Abstract
深度卷积神经网络在显著目标检测上已有应用,并取得了state of the art的性能。但是之前的绝大多数工作都关注在区域的准确率上,而不是边界的质量上。这篇论文提出了一个预测-优化的框架,BASNet,以及一个新的针对边界感知显著目标检测的混合损失。特别地,该框架由一个密集监督的encoder-decoder网络和一个残差优化模块构成,分别负责显著预测和特征图(saliency map)优化。混合损失将二元交叉熵、Structural SIMilarity、IoU损失结合起来,指导网络去学习输入图像和ground truth之间的变换,以三层级(像素-区块-特征图)的形式。有了这个混合损失,我们所提出的预测-优化框架就可以有效地对显著目标区域进行分割,用清晰的边界来准确地预测其结构。在6个公开的数据集的实验结果表明,在区域和边界评价上,我们的方法超过了state of the art的其它方法,我们的方法在单个GPU上的处理速度能达到25FPS。代码放在了:https://github.com/NathanUA/BASNet
1. Introduction
人类的视觉系统有一个非常有效的注意力机制,可以从视觉场景中选择最重要的信息。计算机视觉宗旨就是构建一个这样的机制,主要有两个分支:眼睛固定的检测[20]以及显著目标检测[3]。我们的工作主要放在第二个分支上,目的是能够在输入图像上准确地分割出显著物体的像素点。这些结果可以直接应用在图像分割、编辑上,以及视觉跟踪和用户界面优化上。
最近,全卷积神经网络开始用于显著目标检测。尽管和传统方法相比,这些方法取得的成绩很突出,它们预测的特征图在细微的结构和边界上仍然是有缺陷的(图1 c/d)。
显著目标检测要想提高准确率有两个主要的挑战:1. 显著性主要是由整张图像的全局的明暗对比度定义而来,而不是局部或像素点的特征。为了取得准确的结果,已有的显著目标检测方法不得不去理解整张图片的全局含义,以及目标物体的具体结构[6]。为了解决这个问题,我们就需要一个能够聚合多层级特征的网络。2. 绝大多数的显著目标检测方法都使用交叉熵作为训练损失函数。但是,用交叉熵损失训练出来的模型在判别边界像素点的时候,通常置信度都比较低,导致边界模糊。人们也针对不均衡数据集提出了其它的,如IoU损失函数,F-measure 损失和Dice-score损失,但它们都不是为细微结构而特别设计的。
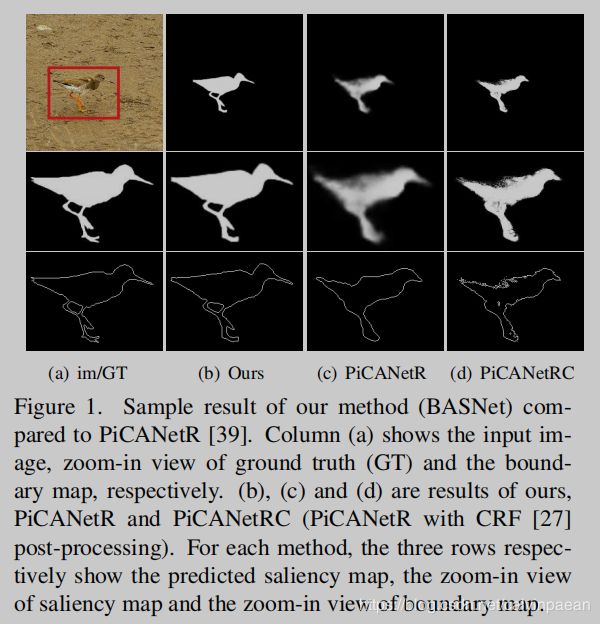
为了解决上述挑战,我们为显著目标检测提出了一个新的边界-感知网络,称作BASNet,取得了非常准确的显著物体分割效果,而且边界非常清晰(图1b)。
- 为了捕捉全局(粗糙)和局部(细致)的信息,我们提出了一个新的预测-优化网络。它将一个类似于U-Net的深度监督的encoder-decoder网络和一个新的残差优化模块组合起来。Encoder-decoder网络将输入图像转换为一个概率图,而优化模块则通过学习粗糙的特征图和ground truth之间的残差来优化预测的输出(看图2)。和[50,22,6]不同,它们在多个尺度上,对显著性预测或中间的特征图迭代式地使用优化模块,而我们的方法只在显著性预测时,在原始尺度上使用了该模块一次。
- 为了取得高置信度特征图以及清晰的边界,我们提出了一个混合损失函数,将二元交叉熵损失、Structural SIMilarity和IoU损失结合起来,它们分别在像素点-区块-特征图上,从ground truth信息中学习。我们没有使用显式的边界损失(NLDF+[41], C2S[36]),而是隐式地将准确的边界预测目标注入混合损失函数中,我们认为这可以帮助降低交叉传播图像边界和区域中学到的信息所带来的假错率(spurious error)。
本文的贡献主要如下:
- 一个新的边界-感知的显著目标检测网络:BASNet,由一个深度监督的encoder-decoder和一个残差优化模块构成。
- 一个新的混合损失函数,将二元交叉熵、SSIM、IoU损失结合起来,在三个层级上对显著目标检测的训练过程进行监督:像素级,区块级,特征图级。
- 此方法的详细评价包含了与15个state of the art的方法在6个数据集上的比较。我们的方法在区域评价指标、边界评价指标上都取得了state of the art的成绩。
2. Related Works
传统方法:早期的方法根据一个预先定义的显著性测度来搜索像素点,从而进行显著物体检测,该测度由人工特征计算得来。Borji等人在[3]中提供了详细的介绍。
Patch-wise 深度方法:受CNN在图像分类领域的启发,早期的深度显著目标检测方法都基于单尺度或多尺度提取的图像区块,对图像像素点或超像素点分类为显著或不显著,从而找到显著目标物体。这些方法输出的结果常常比较粗糙,因为空间信息在全卷积层中会丢失。
基于全卷积的方法:基于FCN的显著目标检测方法利用patch-wise深度方法取得了不错的效果,因为FCN可以捕捉更加丰富的空间和多尺度信息。Zhang等人[75]设计了一个新的dropout以及一个混合上采样模块,来降低反卷积算子的棋盘效应(checkboard artifact),以及将多层级卷积特征聚合起来,用于显著性检测。Hu等人[18]提出学习Level Set[48]函数来提高边界的准确性和显著区域的紧凑度。Luo等热[41]用一个 4 × 5 4\times 5 4×5的网格结构设计了一个新的网络NLDF+,将局部和全局信息结合起来,并且将交叉熵和边界IoU函数融合起来使用。Hou等人[17]通过在skip-layers中加入短路连接,使用了Holistically-Nested Edge Detector(HED),用于显著物体检测。Chen等人[4]迭代地利用逆向注意力模型优化HED的side-outputs。Zhang等人[73]提出了一个sibling 架构和一个新的结构损失函数,用清晰的边界来预测其显著性。Zhang等人[72]为了实现精确的预测,在浅层网络和深层网络之间提出了一个控制的、双向的特征传递。
深度递归和注意力方法:Kuen等人[30]提出了一个递归网络,在选定图像子区域上迭代地进行优化。Zhang等人[76]设计了一个递归显著检测模型,通过一个多路径的递归连接,将全局信息从较深的层传递至较浅的层。Wang等人[63]通过迭代纠正预测错误,设计了一个递归FCN来进行显著目标检测。Liu等人[39]利用contextual 注意力网络来预测像素点的注意力图,然后将它和U-Net架构融合起来,预测显著物体。
从粗略到精细的深度方法:为了捕捉更细微的结构和更准确的边界,人们提出了许多的优化策略。Liu等[38]就提出了一个深度层级显著网络,学习不同的全局结构化的显著特征,然后逐渐地优化特征图的细节信息。Wang等人[64]提出利用一个金字塔池化模块以及多阶段优化机制来捕捉全局信息,对特征图进行优化。受[50]启发,Amirul等[22]提出了一个encoder-decoder网络,利用优化单元来递归式地由低分辨率到高分辨率地对特征图进行优化。Deng[6]想出了一个递归残差优化网络,将浅层和深层特征结合起来进行特征图优化。Wang等人[65]提出要在全局范围内定位显著物体,然后利用一个局部边界优化模块来进行改良。尽管这些方法极大地提升了显著物体检测的效果,但在细微结构分割质量和边界回复准确度上仍有很大提升的空间。
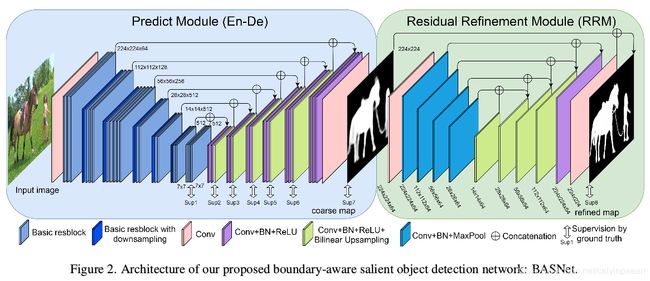
3. BASNet
这一章节首先将介绍我们提出的预测-优化模型,BASNet。我们首先在3.2节中介绍预测模块,然后是3.3节中我们最新设计的残差优化模块的细节内容。在3.4节是我们设计的混合损失函数。
3.1 网络结构的概览
BASNet由两个模块构成,如图2所示。预测模块是一个类似于U-Net的密集监督encoder-decoder网络,从输入图像中学习预测特征图。多尺度残差优化模块(RRM)通过学习特征图和ground truth之间的残差,优化预测模块最终的特征图。
3.2 预测模块
受U-Net和SegNet启发,我们设计了显著目标预测模块—一个encoder-decoder网络,因为这类结构能够同时获取高等级的全局信息和低等级的细节信息。受到HED[67](图2)启发,为了降低过拟合,每个decoder的最后一层都由ground truth来监督。Encoder部分有一个输入卷积层和6个由基本残差模块组成的stages构成。输入卷积层和前4个stages都直接用了ResNet-34中的层[16]。不同之处在于我们的层有64个滤波器,大小是 3 × 3 3\times 3 3×3,stride是1,而ResNet-34中的滤波器大小则是 7 × 7 7\times 7 7×7,步长是2。此外,在输入层之后没有池化操作。也就是说,第二个stage之前的特征图与输入图像有着相同的分辨率。这和原来的ResNet-34不同,它在第一个特征图的分辨率缩小到了 1 / 4 1/4 1/4大小。这个改动使得网络在早期阶段就能够获取更高的分辨率特征图,也可以降低整体的感受野。为了获得和ResNet-34一样的感受野,我们在ResNet-34第4个stage之后增加了2个额外的stages。这两个stages都由3个基础的残差模块构成,该模块在一个大小为2、不重叠的max pool层之后有512个滤波器。
为了进一步获取全局信息,我们在encoder和decoder之间增加了一个bridge stage。它由3个卷积层构成,每个卷积层有512个 3 × 3 3\times 3 3×3的空洞卷积[70] (dilation=2)组成。每个卷积层都跟着一个BN层和一个ReLU激活函数层。
我们的decoder几乎和encoder对称。每个stage由三个卷积层构成,每个卷积层后跟着一个BN和ReLU层。每个stage的输入都是前面stages和对应的encoder里的stages输出的上采样特征图 concat 起来的。为了获取特征图的side-ouptut,我们将每个decoder stage和bridge stage的多通道输出作为一个普通的 3 × 3 3\times 3 3×3卷积层的输入,后面跟着一个双线性上采样以及一个sigmoid 函数。因而,给定输入图像,我们的预测模块在训练过程中就产生7个特征图。尽管每个特征图都上采样至输入图像的大小,最后一个特征图的准确率是最高的,因此我们将最后一个特征图作为预测模块的最终输出,被传进优化模块中。
3.3 优化模块
优化模块[22,6]通常被设计为一个残差模块,通过学习特征图和ground truth之间的残差 S r e s i d u a l S_{residual} Sresidual来优化预测到的粗略的特征图 S c o a r s e S_{coarse} Scoarse:
S r e f i n e d = S c o a r s e + S r e s i d u a l S_{refined} = S_{coarse} + S_{residual} Srefined=Scoarse+Sresidual
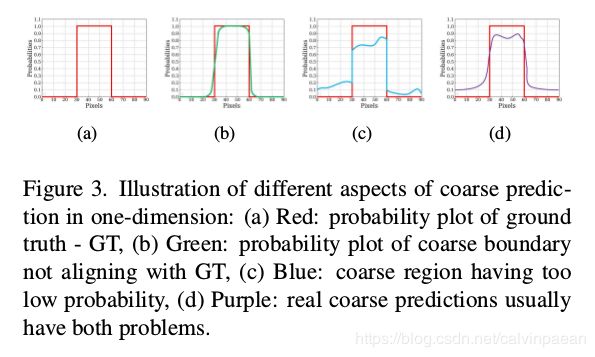
在介绍优化模块之前,我们必须定义一下“粗略”这个词。这里,“粗略”包括两个方面。一个是模糊和噪点的边界(参考图3b中的一维呈现)。另一个就是不均匀的预测的区域概率(图3c)。这两个方面在真实预测的粗略特征图很常见(图3d)。
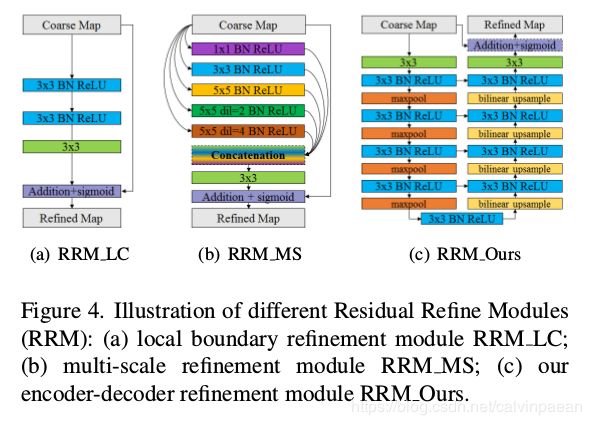
基于局部信息的残差优化模块(图4a)首次提出是用于边界优化[50]上。由于它的感受野比较小,Islam等人[22]和Deng等人[6]迭代式或递归式地将之在多个尺度上用于特征图优化。Wang等人[64]利用[15]里的金字塔池化模块,将三个尺度的金字塔池化特征concat起来。为了避免因为池化操作而丢失细节信息,RRM_MS(图4b)利用大小卷积核和dilations的卷积,来获取多层级信息。但是,这些模块都比较浅,很难获取高等级信息,用于优化。
为了优化粗略的特征图中存在的区域和边界缺陷,我们设计了一个新的残差优化模块。该RRM利用残差encoder-decoder架构,RRM_Ours(图2和图4c)。它主要的架构和预测模块的架构类似,但是要简单些。它包括一个输入层、encoder、bridge、decoder和输出层。和预测模块不同,encoder和decoder有4个stages。每个stage只有一个卷积层,每一层有64个滤波器,大小是 3 × 3 3\times 3 3×3,后面跟着一个BN层和一个ReLU层。Bridge stage有一个有64个滤波器的卷积层,大小是 3 × 3 3\times 3 3×3,后面跟着一个BN层和ReLU层。在下采样时,我们在encoder中使用了非重叠的max pooling层,然后在上采样decoder中,我们使用了双线性插值。这个RM模块的输出就是我们模型最终的特征图输出。
3.4 混合损失函数
我们的训练损失函数定义为所有输出的和:
L = ∑ k = 1 K α k l ( k ) L = \sum_{k=1}^K \alpha_k l^{(k)} L=k=1∑Kαkl(k)
其中, l ( k ) l^{(k)} l(k)是第k个side output的损失, K K K表示输出的个数, α k \alpha_k αk是每个损失的权重。如3.2和3.3节所描述,我们的显著目标检测模型由8个输出来监督,即 K = 8 K=8 K=8,包括7个从预测模型得来的输出已经1个从优化模块得到的输出。
为了获得高质量的区域分割和清晰的边界,我们定义了 l ( k ) l^{(k)} l(k)为混合损失函数:
l ( k ) = l b c e ( k ) + l s s i m ( k ) + l i o u ( k ) l^{(k)} = l^{(k)}_{bce} + l^{(k)}_{ssim} + l^{(k)}_{iou} l(k)=lbce(k)+lssim(k)+liou(k)
其中, l b c e ( k ) , l s s i m ( k ) , l i o u ( k ) l^{(k)}_{bce}, l^{(k)}_{ssim}, l^{(k)}_{iou} lbce(k),lssim(k),liou(k)分别表示交叉熵损失,SSIM损失,和IoU损失。
交叉熵损失在二元分类和分割任务上应用最广泛。定义如下:
l b c e = − ∑ ( r , c ) [ G ( r , c ) l o g ( S ( r , c ) ) + ( 1 − G ( r , c ) ) l o g ( 1 − S ( r , c ) ) ] l_{bce} = - \sum_{(r,c)} [G(r,c) log(S(r,c)) + (1-G(r,c)) log(1-S(r,c))] lbce=−(r,c)∑[G(r,c)log(S(r,c))+(1−G(r,c))log(1−S(r,c))]
其中, G ( r , c ) ∈ { 0 , 1 } G(r,c)\in \{0,1\} G(r,c)∈{0,1}是像素点 ( r , c ) (r,c) (r,c)的ground truth 标签, S ( r , c ) S(r,c) S(r,c)是目标显著的预测概率。
SSIM原先是为了图像质量评价而提出的[66]。它在一个图像中捕捉结构信息。因此,我们将它整合在损失函数中,学习显著物体ground truth的结构信息。 x = { x j : j = 1 , . . . , N 2 } , y = { y j : j = 1 , . . . , N 2 } x = \{x_j : j = 1,...,N^2\}, y=\{y_j : j = 1,..., N^2\} x={xj:j=1,...,N2},y={yj:j=1,...,N2}分别是从预测概率图 S S S和二元ground truth mask G G G上裁剪得到的两个对应区块的像素值(大小: N × N N\times N N×N), x x x和 y y y的SSIM定义为:
l s s i m = 1 − ( 2 μ x μ y + C 1 ) ( 2 σ x y + C 2 ) ( μ x 2 + μ y 2 + C 1 ) ( σ x 2 + σ y 2 + C 2 ) l_{ssim} = 1- \frac{(2\mu_x \mu_y + C_1)(2\sigma_{xy} + C_2)}{(\mu_x^2 + \mu_y^2 + C_1)(\sigma_x^2 + \sigma_y^2+ C_2)} lssim=1−(μx2+μy2+C1)(σx2+σy2+C2)(2μxμy+C1)(2σxy+C2)
其中, μ x , μ y \mu_x, \mu_y μx,μy和 σ x , σ y \sigma_x, \sigma_y σx,σy分别是 x , y x,y x,y的均值和标准方差。 σ x y \sigma_{xy} σxy是它们的协方差, C 1 = 0.0 1 2 , C 2 = 0.0 3 2 C_1 = 0.01^2, C_2 = 0.03^2 C1=0.012,C2=0.032是为了避免分母为0。
IoU最开始是用于计算两个集合的相似度,然后被用作为目标检测和分割的标准评估方法。最近,它也开始应用在训练损失函数中[56,42]。为了确保其可微性,我们使用了如下的IoU损失[42]:
L i o u = 1 − ∑ r = 1 H ∑ c = 1 W S ( r , c ) G ( r , c ) ∑ r = 1 H ∑ c = 1 W [ S ( r , c ) + G ( r , c ) − S ( r , c ) G ( r , c ) ] L_{iou} = 1 - \frac{\sum_{r=1}^H \sum_{c=1}^W S(r,c) G(r,c)}{\sum_{r=1}^H \sum_{c=1}^W [S(r,c) + G(r,c) - S(r,c)G(r,c)]} Liou=1−∑r=1H∑c=1W[S(r,c)+G(r,c)−S(r,c)G(r,c)]∑r=1H∑c=1WS(r,c)G(r,c)
其中, G ( r , c ) ∈ { 0 , 1 } G(r,c)\in \{0,1\} G(r,c)∈{0,1}是像素点 ( r , c ) (r,c) (r,c)的ground truth标签, S ( r , c ) S(r,c) S(r,c)是其为显著类别的预测概率。
我们在图5中展示了三种损失各自的作用。这些热力图显示了在训练过程中,每个像素点上损失的变化。三排分别对应于交叉熵损失、SSIM损失、IoU损失。三列表示不同stage的训练过程。交叉熵损失是逐个像素点的。它没有考虑临近区域的标签,它视前景和背景像素点同等重要,有助于所有像素点的收敛。
SSIM 损失是一个区块级的测度,考虑每个像素点的局部临近区域。它给边界赋予较高的权重,也就是在边界附近损失较高,当边界的预测概率和前景其余部分的概率是一样的。开始训练时,边界上的损失值是最大的(图5第2排)。它有助于优化过程关注在边界上。随着训练的继续,前景的SSIM损失逐渐降低,背景损失逐渐重要。但是,得等到背景像素点的预测非常接近ground truth了(预测值迅速地由1跌为0),背景损失才会在训练中发挥作用。这非常有帮助,因为只有在训练的后半段时(交叉熵损失变得非常平稳了),预测结果才会趋近于0。SSIM损失确保我们仍有足够的梯度来让模型学习。背景预测看上去更干净一些,因为概率值逐渐会变成0。
IoU损失是一个特征图级别的测度。但是出于展示目的,我们依据上面的等式将每个像素点的IoU plot了出来。随着前景网络预测置信度的上升,前景损失逐渐降至0。当我们将这三个损失结合起来时,我们利用交叉熵损失来对所有像素点保持其梯度平滑,用IoU损失来更多的关注在前景上。SSIM用于确保预测结果是符合原始图像结构的,在边界位置的损失较大。
4. Experiments
Pls read paper for more details.