手把手教用matlab做无人驾驶(八)-无迹Kalman滤波算法
1.KF、EKF、UKF都是高斯滤波,下面的介绍一下他们的优缺点:
KF优点:计算简单
KF缺点:高斯线性模型约束
EKF优点:可以近似非线性问题
EKF缺点:高斯噪声约束,线性化引入了误差会可能导致滤波发散,雅克比矩阵(一阶)及海塞矩阵(二阶)计算困难
UKF优点:模型无损失,计算精度高
UKF缺点:高斯噪声约束
前面的KF和EKF都是都将问题转化为线性高斯模型,所以可以直接解出贝叶斯递推公式中的解析形式,方便运算。但对于非线性问题,EKF除了计算量大,还有线性误差的影响,所以这里引入UKF。对于求解非线性模型的贝叶斯递推公式的主要困难在于如何解析的求解一步预测状态分布的概率、(观测方程得到的)似然函数分布密度以及后验条件概率的分布,EKF利用泰勒分解将模型线性化,在利用高斯假设解决了概率计算困难的问题。但是线性误差的引入降低了模型精度。那么我们换个思路,对于非线性模型,直接用解析的方式来求解贝叶斯递推公式比较困难主要很难解析的得到各个概率分布的均值和方差,但UT变换(一种计算非线性随机变量各阶矩的近似方法)却可以较好的解决这个问题,通过一定规律的采样和权重,可以近似获得均值和方差。而且由于不敏变换对统计矩的近似精度较高。
首先在介绍无迹kalman滤波算法之前,介绍一下UT变换

接下来要计算权值。对求期望来说,第一个sigma点的权值为:
![]()
对求方差来说,第一个sigma点的权值为如下,式子中的β也为一个常数

对于剩下的2n个sigma点来说求期望的权值和求方差的权值都相同:
![]()
上标表m为均值,c为协方差,下标为第几个采样点。参数![]() 。
。
因此,一共有三个常数(α,β,k)需要我们来设定。根据其它参考资料,选择参数的经验为:
其中a决定sigma点的散步程度,通常取一个小的正值,k通常取0,β用来描述x的分布信息,β最优值为2。
下面介绍无迹kalman滤波算法matlab实现步骤:
例子如下:


1.第一步,获取sigma点集:

这个对应matlab程序
function UKF
clc;clear;
T=1;
N=60/T;
X=zeros(4,N);
X(:,1)=[-100,2,200,20];
Z=zeros(1,N);
delta_w=1e-3;
Q=delta_w*diag([0.5,1]) ;
G=[T^2/2,0;T,0;0,T^2/2;0,T];
R=5;
F=[1,T,0,0;0,1,0,0;0,0,1,T;0,0,0,1];
x0=200;
y0=300;
Xstation=[x0,y0];
w=sqrtm(R)*randn(1,N);
for t=2:N
X(:,t)=F*X(:,t-1)+G*sqrtm(Q)*randn(2,1);
end
for t=1:N
Z(t)=Dist(X(:,t),Xstation)+w(t);
end
L=4;
alpha=1;
kalpha=0;
belta=2;
ramda=alpha^2*(L+kalpha)-L;
for j=1:2*L+1
Wm(j)=1/(2*(L+ramda));
Wc(j)=1/(2*(L+ramda));
end
Wm(1)=ramda/(L+ramda);
Wc(1)=ramda/(L+ramda)+1-alpha^2+belta;
%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%
Xukf=zeros(4,N);
Xukf(:,1)=X(:,1);
P0=eye(4);
for t=2:N
xestimate= Xukf(:,t-1);
P=P0;
cho=(chol(P*(L+ramda)))';
for k=1:L
xgamaP1(:,k)=xestimate+cho(:,k);
xgamaP2(:,k)=xestimate-cho(:,k);
end
Xsigma=[xestimate,xgamaP1,xgamaP2];上面通过
xestimate= Xukf(:,t-1);
P=P0;
cho=(chol(P*(L+ramda)))';
for k=1:L
xgamaP1(:,k)=xestimate+cho(:,k);
xgamaP2(:,k)=xestimate-cho(:,k);
end
Xsigma=[xestimate,xgamaP1,xgamaP2];
即可获得Xsigma对应上面公式了。这里chol是matlab把矩阵解为上三角和下三角两个解。
2.利用上面的Xsigma,带入模型中预测k时刻计算k+1时刻的状态:
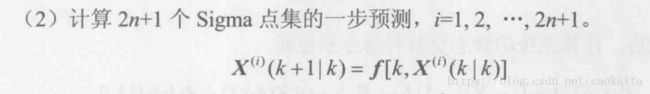
Xsigmapre=F*Xsigma;
其中, Xsigmapre=F*Xsigma;对应上面的公式。
3.通过权值对sigma点进行预测,计算均值与协方差,

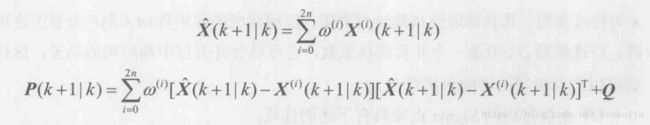
Xpred=zeros(4,1);
for k=1:2*L+1
Xpred=Xpred+Wm(k)*Xsigmapre(:,k);
end
Ppred=zeros(4,4);
for k=1:2*L+1
Ppred=Ppred+Wc(k)*(Xsigmapre(:,k)-Xpred)*(Xsigmapre(:,k)-Xpred)';
end其中Xpred=Xpred+Wm(k)*Xsigmapre(:,k)和 Ppred=Ppred+Wc(k)*(Xsigmapre(:,k)-Xpred)*(Xsigmapre(:,k)-Xpred)'分别对应上面公式。
4.根据预测值再做一次UT变换,等到新的sigma点集:

Ppred=Ppred+G*Q*G';
chor=(chol((L+ramda)*Ppred))';
for k=1:L
XaugsigmaP1(:,k)=Xpred+chor(:,k);
XaugsigmaP2(:,k)=Xpred-chor(:,k);
end
Xaugsigma=[Xpred XaugsigmaP1 XaugsigmaP2];5.计算观测均值和方差


for k=1:2*L+1
Zsigmapre(1,k)=hfun(Xaugsigma(:,k),Xstation);
end
Zpred=0;
for k=1:2*L+1
Zpred=Zpred+Wm(k)*Zsigmapre(1,k);
end
Pzz=0;
for k=1:2*L+1
Pzz=Pzz+Wc(k)*(Zsigmapre(1,k)-Zpred)*(Zsigmapre(1,k)-Zpred)';
end
Pzz=Pzz+R;6.计算Kalman增益:

K=Pxz*inv(Pzz);7.状态和方差更新:

xestimate=Xpred+K*(Z(t)-Zpred);
P=Ppred-K*Pzz*K';
P0=P;
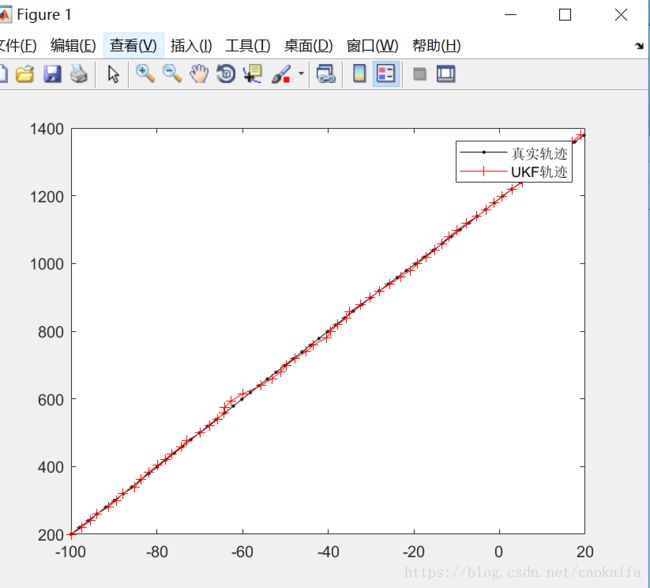
Xukf(:,t)=xestimate;最后,给出仿真结果:
完整代码下载地址:
https://download.csdn.net/download/caokaifa/10718818