redis
文章目录
- 通用命令
- 数据结构 -GEO
- 数据结构 -Stream
- redis解除安全模式
- 持久化
- 性能论
- RDB:内存快照
- Snapshotting快照
- AOF:命令记录
- 优缺点
- Rewrite
- 重写原理
- 重写触发机制
- aof文件损坏修复
- 内存管理
- 内存压缩
- 过期数据处理
- 数据恢复阶段过期数据的处理策略
- reids内存回收策略
- 主从复制
- 搭建主从复制
- 检查主从复制情况
- 主从复制流程
- 主从复制核心概念
- 主从复制应用场景
- 读写分离场景:
- 全量复制情况下:
- 复制风暴
- 写能力有限
- master故障情况
- master无持久化情况下宕机
- 带有效期的key
- 高可用哨兵(Sentinel)机制
- 客户端spring-data-redis实现哨兵
- 哨兵核心运作流程
- 哨兵的核心概念
- 1.哨兵如何直到redis主从信息(自动发现机制)
- 2.什么是master主观下线
- 3.什么是客观下线
- 4.哨兵之间如何通信(哨兵之间的自动发现)
- 5.哪个哨兵负责故障转移?(哨兵领导选举机制)
- 6.slave选举机制
- 7.最终主从切换过程
- 哨兵服务部署方案
- redis分布式锁实现
- redis可以实现锁机制简易版
- 秒杀场景高并发情况下分布式锁实现
- redlock算法
- 分布式锁实现方案
- redis集群分片存储
- 原理
- 集群关心的问题
- redis监控
- monitor命令
- 图形化监控工具-RedisLive
redis是C语言编写、支持网络、可基于内存也可持久化的日志型、key-value数据库,并支持多种api
它是一个单线程实例
因为Redis是基于内存的操作,CPU不是Redis的瓶颈,Redis的瓶颈最有可能是机器内存的大小或者网络带宽。既然单线程容易实现,而且CPU不会成为瓶颈,那就顺理成章地采用单线程的方案了(毕竟采用多线程会有很多麻烦!为什么麻烦请参考线程状态和原理…)。单线程可以避免线程切换, 也不需要考虑锁的问题
通用命令

数据结构 -GEO
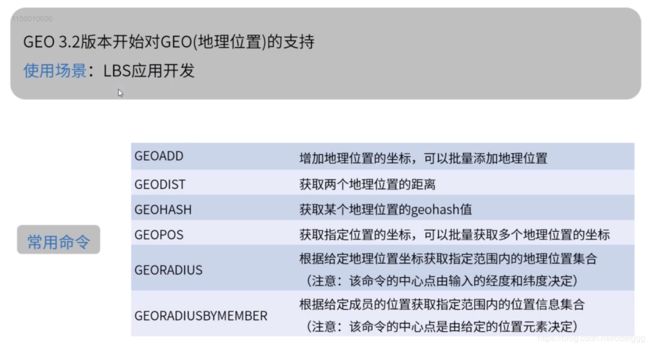
数据结构 -Stream

redis解除安全模式
当redis-server启动之后会进入安全模式,阻止第三方客户端访问,想要访问redis需要解除安全模式

bind后面改成0.0.0.0表示任何ip都可用 一般情况下是改为自己的ip ,不要把redis暴露在公网下,会有安全漏洞。
持久化
当dump.rdb与appendonly.aof同时存在时,redis启动时优先启用aof文件加载内存数据
Rdb和aof可以同时存在
性能论
RDB文件只用做后备,建议只在slave上持久RDB文件,一般15分钟备份一下就够,只保留save 900 1这条
如果Enable AOF,好处是一旦宕机,则只丢失不到2秒的数据,启动脚本只load自己的aof文件就可以了。代价:1.持续的持续的IO消耗资源;2.AOF rewrite的最后将rewrite过程中产生的新数据写到新文件造成的阻塞是不可避免的。只要硬盘许可,应该尽量减少AOF的rewrite频率,AOF重写的基础大小默认64m太小,实际工作中最少3G起步,一般调整到5G以上,而默认100%大小可以按需调整适当的数值。
如果不用 Enable AOF ,紧靠master-slave replication实现高可用性也可,能省下大笔IO开销,也减少了rewrite时带来的系统波动,代价是当master和slave同时宕机,会丢失十几分钟的数据,启动脚本也要比较两个master/slave的rdb文件,载入最新的rdb,新浪微博使用的就是这种架构
RDB:内存快照
将指定时间内的数据集快照写入磁盘,也就是snapshot,恢复时也是将快照文件读入内存。
Redis会单独创建(fork)一个子进程进行持久化,会先将数据写入一个临时文件,等持久化结束之后,再用临时文件替换上次持久化好的文件。整个过程中,主进程是不进行任何IO操作的,这确保了高性能,如果要大规模恢复数据,并且对数据完整性不是非常敏感,RDB比AOF更高效。
缺点:RDB最后一次持久化后的数据可能丢失
Fork:复制一份与当前进程一样的进程,所有数据全与原进程一致,但是是一个全新进程,并且是原进程的子进程。
持久化文件:dump.rdb
备份:
save 60 10000 1分钟1万次key操作 则备份
Save 300 10 5分钟10次key操作 则备份
Save 900 1 15分钟1次key操作 则备份
禁用RDB可以设置save “”或者不设置save
手动备份 直接打save
Save:阻塞式存储
Bgsave:非阻塞式异步存储
Flushall也会产生rdb 但是文件为空
Snapshotting快照
Save备份快照rdb
Stop-writes-on-bgsave-error:当保存时报错,则停止写操作 默认yes
Rdbcompression:对于存到磁盘的快照是否进行压缩,如果压缩则使用LZF算法,默认yes
Rdbchecksum:存快照之后让redis使用CRC64算法进行校验 默认yes
AOF:命令记录
已日志形势记录每一次操作,将redis执行过的所有写命令记录下来(读不记录),只许追加不可更改文件,redis启动之初会地区该文件重新构建数据,即redis重启的时候会根据日志文件内容将写命令从前到后执行一遍,从而完成数据恢复工作。
AOF存储文件:appendonly.aof
这种方式会是文件膨胀,默认方式no
持久化策略:
Always:同步持久化,当发生数据变更时会立刻记录到磁盘,完整性较好,性能较差
Everysec:默认此策略,每秒记录一秒内的操作,宕机时可能丢失1秒数据
No:不启动aof

优缺点

Rewrite
AOF采用文件追加方式,会使文件越来越大,为了避免此类情况,提供了重写机制,当aof文件大小超过设定阈值时,redis会启动aof文件内容压缩,只保留恢复数据最小指令集,可以使用命令bgrewriteaof重写。
重写原理
当AOF持续增加过大时,会fork出一条新的进程将文件重写(也是先写临时文件最后再rename覆盖)。遍历新进程内所有数据,每条记录使用set命令重写,并不读取旧aof文件,而是将整个内存数据内容使用命令方式重写一个aof文件,类似于rbd快照。
重写触发机制
Redis会记录上次重写aof时的aof文件大小,默认配置的是当AOF大小是上次rewrite后大小的一倍且文件大于64M时触发rewrite
在conf文件中 aof块
auto-aof-rewrite-percentage 100 //在大小比之前aof大100%的时候重写
Auto-aof-rewrite-min-size 64mb //在基准值为64mb时重写 实际生产时3G起步
aof文件损坏修复
Redis-chcek-aof --fixappendonly.aof 使用redis-check-aof校验aof中语法 来修复aof文件
内存管理

可以设置最大内存阈值maxmemory
达到最大阈值时的策略maxmemory-policy
内存压缩

过期数据处理

数据恢复阶段过期数据的处理策略

注意:过期数据的计算和计算机本身的时间是有直接联系的
reids内存回收策略
配置文件中设置:maxmemeory-policy noevivtion
动态调整:config set maxmemory-policy noeviction

LRU(least recently used,最近最少使用):根据数据的历史访问记录来进行淘汰数据

LFU(least frequently used)根据数据的历史访问频率来淘汰数据。

主从复制

主要解决单机的QPS有限以及redis-server单点故障;
主要应用场景:
读写分离场景,避免redis单机瓶颈
故障切换,master故障后还有slave节点可以使用
搭建主从复制
两种方式:
1.命令行:
#链接需要实现从节点的redis,执行下面命令
slaveof [ip] [port]
2.redis.conf配置文件
#配置文件中增加
slaveof [ip] [port]
#从服务器是否只读(默认yes)
slave-read-only yes
退出主从集群方式
Slaveof no one
新版本之后slave在逐步向replication转换。
在新版本里面slaveof [ip] [port] 也在从机上可以使用replicaof [masterip] [masterport] 来实现主从
检查主从复制情况

主从复制流程
1.从服务器通过psync命令发送服务器已有的同步进度(同步源ID、同步进度offset)
2.mastrer收到请求,同步源为当前master,则根据偏移量增量同步
3.同步源非当前master,则进入圈梁同步:master生成rdb,传输到slave,加载到slave内存。
主从复制核心概念
redis默认使用异步复制,slave和master之间异步确认处理的数据量
一个master可以拥有多个slave
slave可以接受其他slave的链接。slave可以有下级sub slave
主从同步过程在master、侧是非阻塞的
slave初次同步需要删除旧数据,加载新数据,会阻塞到来的链接请求。
主从复制应用场景
支持读写分离
slave服务器设定为只读,可以用在数据安全的场景下。
可以使用主从复制来避免master持久化造成的开销你。master关闭持久化,slave配置为不定期保存或启用aof。(注:重启master程序将从一个空数据集开始,如果一个slave试图与它同步,那么这个slave也会被清空)
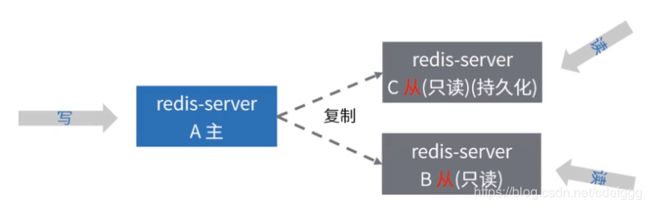
读写分离场景:
数据复制延迟导致督导过期数据或者读不到数据(网络原因、slave阻塞)
读写分离场景通过spring集成的data-redis工具包可以实现
//定义一个service
@Service
public class ReplicationExampleService {
@Autowired
private StringRedisTemplate template;
public void setByCache(String userId, String userInfo) {
template.opsForValue().set(userId, userInfo);
}
public String getByCache(String userId) {
return template.opsForValue().get(userId);
}
}
//添加master配置信息
@Configuration
@Profile("replication") // 主从模式
class ReplicationRedisAppConfig {
@Bean
public LettuceConnectionFactory redisConnectionFactory() {
// master:192.168.100.241 slave:192.168.100.242
// 默认slave只能进行读取,不能写入
// 如果你的应用程序需要往redis写数据,建议连接master
return new LettuceConnectionFactory(new RedisStandaloneConfiguration("192.168.100.241", 6379));
}
}
//添加slave配置信息
@Configuration
@Profile("replication-rw") // 主从 - 读写分离模式
class ReplicationRWRedisAppConfig {
@Bean
public LettuceConnectionFactory redisConnectionFactory() {
System.out.println("使用读写分离版本");
LettuceClientConfiguration clientConfig = LettuceClientConfiguration.builder()
.readFrom(ReadFrom.SLAVE_PREFERRED)
.build();
// 此处
RedisStandaloneConfiguration serverConfig = new RedisStandaloneConfiguration("192.168.100.242", 6379);
return new LettuceConnectionFactory(serverConfig, clientConfig);
}
}
如此就简单实现了主从的读写分离客户端。
全量复制情况下:
第一次建立主从关系或者runid不匹配会导致全量复制
故障转移的时候也会出现全量复制
复制风暴
master故障重启,如果slave节点较多,所有slave都要复制,对服务器性能,网络压力都有很大影响
如果一个机器部署了多个master,那么故障重启的时候多个master同时接收slave同步复制也会造成服务器压力增大。
写能力有限
主从复制还是只有一台master的情况,提供的鞋服务器能力有限。
master故障情况
如果master无持久化,slave开启持久化来保存数据的场景,建议不要配置redis自动重启。
启动redis自动重启,,master启动后,无备份数据,可能导致集群数据丢失的情况。
master无持久化情况下宕机
手动切换有持久化的slave为master
在slave服务器上
slaveof no one
![]()
在原master服务器上使用
slaveof [ip] [prot]
将原master编程当前master的slave
带有效期的key
slave不会让key过期,而是等待master让key过期
在lua脚本执行期间,不执行任何key过期操作
高可用哨兵(Sentinel)机制
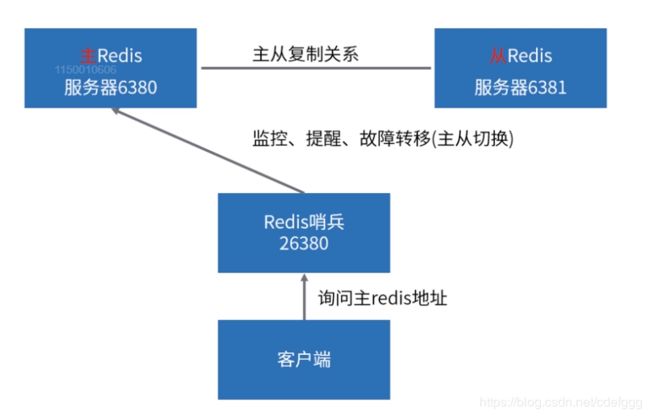
在编辑conf文件的时候容易出现乱码,建议将conf设置为utf-8无bom模式。
redis已经实现了多个哨兵之间的通信,所以可以搭建哨兵集群模式。通过多个哨兵同时确认来确定master是否故障,如3个哨兵中2个哨兵认为master可用才是真的可用。
客户端spring-data-redis实现哨兵
实现客户端与redis实例io的通信使用的是netty框架
@Configuration
@Profile("sentinel")
class SentinelRedisAppConfig {
@Bean
public LettuceConnectionFactory redisConnectionFactory() {
System.out.println("使用哨兵版本");
RedisSentinelConfiguration sentinelConfig = new RedisSentinelConfiguration()
.master("mymaster")
// 哨兵地址
.sentinel("192.168.100.241", 26380)
.sentinel("192.168.100.241", 26381)
.sentinel("192.168.100.241", 26382);
return new LettuceConnectionFactory(sentinelConfig);
}
}
测试程序
@RunWith(SpringJUnit4ClassRunner.class)
@ContextConfiguration("classpath:applicationContext.xml")
@ActiveProfiles("sentinel") // 设置profile
public class SentinelTests {
@Autowired
StringRedisTemplate stringRedisTemplate;
@Test
public void test() throws InterruptedException {
// 每个一秒钟,操作一下redis,看看最终效果
int i = 0;
while (true) {
i++;
stringRedisTemplate.opsForValue().set("test-value", String.valueOf(i));
System.out.println("修改test-value值为: " + i);
Thread.sleep(1000L);
}
}
}
当某一个redis实例宕机时,系统会提示连接不上,此时client会询问哨兵,要连接哪个redis实例,哨兵将新的可用master告知client进行连接。而当client与master正常连接时,哨兵如果宕机则没有任何影响,因为只有当client连接master出现问题时才会去询问哨兵。
当master挂掉,并且client访问的哨兵也挂掉,此时client会出现短暂的报错,然后重试其他哨兵,直到获取到master地址。
哨兵核心运作流程

哨兵的核心概念
启动命令:redis-server /path/to/sentinel.comf --sentinel
配置文件启动时指定,运行过程中会自动变更,记录哨兵的监测结果
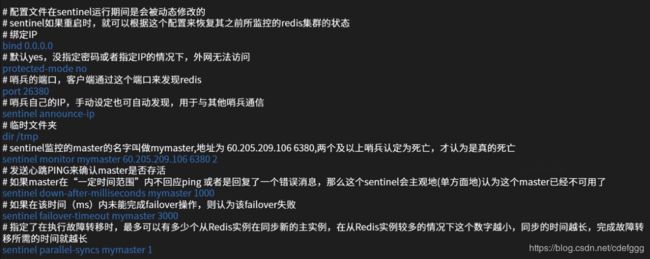
1.哨兵如何直到redis主从信息(自动发现机制)

哨兵配置文件中,保存着主从集群中的master信息,可以通过info命令,进行主从信息自动发现。
2.什么是master主观下线

主观下线:单个哨兵自身认为redis实例已经不能提供服务
检测机制:哨兵向redis发送ping命令请求,+PONG、-LOADING、-MASTERDOWN这三种情况视为正常,其他回复视为无效。
对应配置文件的配置项:sentinel down-after-milliseconds mymaster 1000
3.什么是客观下线
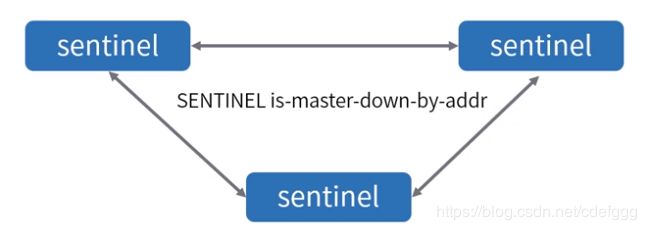
客观下线:一定数量的哨兵认为master已经下线。
检测机制:当哨兵主管认为master下线后,则会通过SENTINEL is-master-down-by-addr命令询问其他哨兵是否认为master已经下线,如果达成共识(达到quorum个数),就会认为master节点客观下线,开始故障转移流程。
对应配置文件配置项:sentinel monitor mymaster 60.205.209.106 6380 2
4.哨兵之间如何通信(哨兵之间的自动发现)
1.哨兵之间自动发现
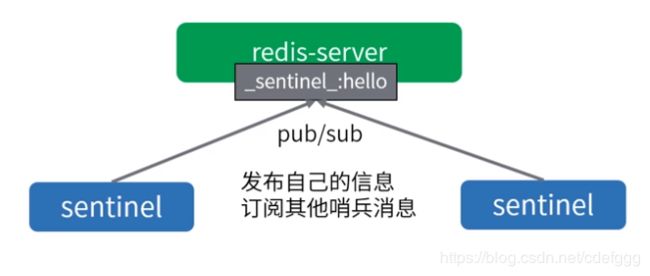
2.哨兵之间通过命令进行通信

3.哨兵之间通过订阅发布进行通信

5.哪个哨兵负责故障转移?(哨兵领导选举机制)
基于Raft算法实现的选举机制流程如下
1.拉票阶段:每个哨兵节点希望自己成为领导者;
2.sentinel节点收到拉票命令后,如果没有收到或同意过其他sentinel节点的请求,就同意该sentinel节点的请求(每个sentinel只持有一个同意票数)
3.如果sentinel节点发现自己的票数已经超过一半的数值,那么它将成为领导者,去执行故障转移;
4.投票结束后,如果超过failover-timeout的时间内,没进行实际的故障转移操作,则重新拉票选举。
注:raft协议算法推理:http://thesecretlivesofdata.com 了解为主,强烈建议。
6.slave选举机制
slave节点状态
非S_DOWN(主观下线),O_DOWN(客观下线),DISCONNECTED
判断规则:(down-after-milliseconds*10)+ milliseconds_since_master_is_in_SDOWN_state
SENTINEL slaves mymaster
优先级
redis.conf中的一个配置项:slave-priority值越小,优先级越高
数据同步情况
Replication offset processed
最小的run id
run id 比较方案:字典顺序,ASCII码
7.最终主从切换过程
针对于即将成为master的slave节点,将其撤出主从集群
自动执行 slaveof no one
针对其他slave节点,使他们成为新master的从属
自动执行:slaveof new_master_host new_master_port
哨兵服务部署方案
建议最少要1主2从,三个哨兵

但是在网络分区的情况下,如果第一个master与其他服务器失联,那么就会出现数据不一致性或者丢失,redis集群并非强一致,而是相对一致
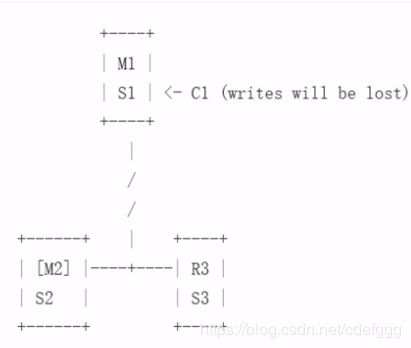
在m1重新回到集群中时 m1和m2的数据已经不一致了,redis集群需要做数据合并,那么必然有一个master会丢失数据,此时由于m2一致的网络一致正常,并且m2也是新选举出来的master,那么相对于m1来说m2的版本号要高于m1,此时会将m1的数据舍弃,来同步m2的数据
redis分布式锁实现
redis可以实现锁机制简易版
使用setnx插入指定key并设置失效时间,在key存在时,其他setnx是不能创建并插入key的。
秒杀场景高并发情况下分布式锁实现
发布订阅机制配合java锁实现分布式锁
1.首先利用redis发布订阅机制来实现java应用集群之间的分布式锁
启用订阅机制会建立一个通道
2.在java应用内部使用lock接口实现对于本应用内部抢锁操作的限制,从而降低对于redis服务器的压力
直接上代码
public class RedisLockImpl implements Lock {
StringRedisTemplate stringRedisTemplate; // redis工具类
String resourceName = null;
int timeout = 10;
ThreadLocal lockRandomValue = new ThreadLocal<>();
/**
* 构建一把锁
*
* @param resourceName 资源唯一标识
* @param timeout 资源锁定超时时间~防止资源死锁,单位秒
*/
public RedisLockImpl(String resourceName, int timeout, StringRedisTemplate stringRedisTemplate) {
this.resourceName = "lock_" + resourceName;
this.timeout = timeout;
this.stringRedisTemplate = stringRedisTemplate;
}
@Override
public boolean tryLock() {
Boolean lockResult = stringRedisTemplate.execute(new RedisCallback() {
@Override
public Boolean doInRedis(RedisConnection connection) throws DataAccessException {
// 随机设置一个值
lockRandomValue.set(UUID.randomUUID().toString());
Boolean status = connection.set(resourceName.getBytes(), lockRandomValue.get().getBytes(),
Expiration.seconds(timeout), RedisStringCommands.SetOption.SET_IF_ABSENT);
return status;
}
});
return lockResult;
}
Lock lock = new ReentrantLock();
// 多台机器的情况下,会出现大量的等待,加重redis的压力。 在lock方法上,加入同步关键字。单机同步,多机用redis
@Override
public void lock() {
lock.lock();
try {
while (!tryLock()) {
// 监听,锁删除的通知
// try {
// Thread.sleep(1000L); // 定时等待后续尝试
// } catch (InterruptedException e) {
// e.printStackTrace();
// }
stringRedisTemplate.execute(new RedisCallback() {
@Override
public Boolean doInRedis(RedisConnection connection) throws DataAccessException {
try {
CountDownLatch waiter = new CountDownLatch(1);
// 等待通知结果
connection.subscribe((message, pattern) -> {
// 收到通知,不管结果,立刻再次抢锁
waiter.countDown();
}, (resourceName + "_unlock_channel").getBytes());
// 等待一段时间,超过这个时间都没收到消息,肯定有问题
waiter.await(timeout, TimeUnit.SECONDS);
} catch (InterruptedException e) {
e.printStackTrace();
}
return true; //随便返回一个值都没问题
}
});
}
} finally {
lock.unlock();
}
}
@Override
public void unlock() {
// 释放锁。(底层框架开发者要防止被API的调用者误调用)
// 错误示范 stringRedisTemplate.delete(resourceName);
// 1、 要比对内部的值,同一个线程,才能够去释放锁。 2、 同时发出通知
if (lockRandomValue.get().equals(stringRedisTemplate.opsForValue().get(resourceName))) {
stringRedisTemplate.delete(resourceName); // 删除资源
stringRedisTemplate.execute(new RedisCallback() {
@Override
public Long doInRedis(RedisConnection connection) throws DataAccessException {
// 发送通知
Long received = connection.publish((resourceName + "_unlock_channel").getBytes(), "".getBytes());
return received;
}
});
}
// 还可以使用lua脚本实现
// if redis.call('get',KEYS[1]) == ARGV[1] then
// local result = redis.call('del',KEYS[1])
// redis.call('publish',KEYS[2], ARGV[2])
// return result
// else
// return 0
// end
}
@Override
public void lockInterruptibly() throws InterruptedException {
}
@Override
public boolean tryLock(long time, TimeUnit unit) throws InterruptedException {
return false;
}
@Override
public Condition newCondition() {
return null;
}
}
以上代码看起来已经基本解决了分布式锁的问题,然后这并不是结束,接下来出现了另一个问题,当我们的一个java应用抢到了lock,并且给lock设置了过期时间1s,此时由于这个应用运行效率慢,导致lock过期释放掉,而java应用的代码还没有跑完,另一个java应用在lock过期释放掉之后抢到了锁,并开始执行秒杀代码。此时两个java应用同时执行秒杀代码,如果库存只有1个那么就会出现超买现象。如何解决这个问题?这个问题没有暂时没有一个明确的解决办法。我们需要做的是给lock的过期时间设置得稍微长一些,让代码的运行完成后主动释放锁,其次设置系统监控,当代码运行时间超过lock过期时间时,默认代码运行失败。
redlock算法
redlock是redis作者设计用于redis的客户端分布式锁算法。该算法的目的是消除redis单点故障,基于具有故障转移的主从设置以实现分布式锁。更加可靠安全,具有非常低的复杂性和良好的性能。
redlock只是一个算法,你也可以使用mysql而不是redis来实现redlock
分布式锁实现方案
数据库实现(乐观锁)
基于zookeeper实现
基于redis实现
redis集群分片存储
原理
对每一个key都通过hash计算然后再取模得出一个对应的slot(槽),然后将这个key存入slot对应的服务器。

集群关心的问题
1.增加了slot槽的计算后,会不会比单机性能差?
共16384个槽,slots槽计算方式公开的,HASH_SLOT=CRC16(key)mod 16384.
为了避免每次都需要服务器计算重定向,优秀的java客户端都实现了本地计算,并且缓存服务器slots分配,有变动时再更新本地内容,从而避免了多次重定向带来的性能损耗。
2.redis集群大小,到底可以装多少数据?
理论上可以做到16384个槽,每个槽对应一个实例,但是redis官方建议是最大1000个实例。存储足够大了。
3.集群节点之间如何通信?
每个redis集群节点都有一个额外的tcp端口,每个节点使用tcp链接与每个其他节点链接。检测和故障转移这些步骤基本和哨兵模式类似.
4.ask和moved重定向的区别
重定向包括两种情况
1)若确定slot不属于当前节点,redis会返回moved。
2)若当前redis节点正在处理slot迁移,则代表此处请求对应的key暂时不在此节点,返回ask,告诉客户端本次请求重定向
5.数据倾斜和访问倾斜问题
倾斜导致集群中部分节点数据多吗,压力大。解决方案分为前期和后期:
前期是业务层面提前预测,那些key是热点,在设计的过程中规避。
后期是slot迁移,尽量将压力分摊(slot调整有自动rebalance、reshard和手动)
6.slot手动迁移如何做
流程如下
在迁移目的节点执行cluster setslotIMPORTING命令,知名需要迁移的slot和迁移源节点。
在迁移源节点执行cluster setslotMIGRATING命令,指明需要迁移的slot和迁移目的节点。
在迁移源节点反复执行cluster getkeysinslot获取该slot的key列表。
在迁移源节点对每个key执行migrate命令,该命令会同步把该key迁移到目的节点。
在迁移源节点反复执行cluster getkeysinslot命令,直到该slot的列表为空。
在迁移源节点和目的节点执行cluster setslotNODE,完成迁移操作。
7.节点之间会交换信息,传递信息包括槽的信息,带来带宽消耗。注意:避免使用一个大的集群,可以分为多个小集群。
8.pub/sub发布订阅机制
注意:对集群内任意的一个节点执行publish发布消息,这个消息会在集群中传播,其他节点收到发布的消息。
9.读写分离
redis-cluster默认所有从节点上读写,都会重定向到key对接槽的主节点上。
可以通过readonly设置当前连接可读,通过readwrite取消当前连接可读状态。
注意:主从节点依然存在数据不一致
redis监控
monitor命令
这是一个调试命令,返回服务器处理的每个命令。对于发现程序错误非常有用,出于安全考虑,某些特殊管理命令CONFIG不会记录到MONITOR输出。
运行一个monitor命令会降低50%的吞吐量,运行越多降低性能越多,需要谨慎使用。
图形化监控工具-RedisLive
