窥探当今AI芯片中的类脑模型

来源:脑人言
撰文丨邓 磊(加州大学-圣塔芭芭拉分校UCSB 博士后)
责编丨高茂森 Soma
排版丨夏獭
科学研究的动机,并非仅仅是出于能看到多酷炫的应用,而是因为我们尚有诸多未知世界需要探寻,这是一切应用的前提。

AI芯片如火如荼
AI芯片是当今人工智能热潮中不可或缺的一个名词,且受国际局势影响愈加受到重视。摩尔定律难以为继,通用处理器的性能提升速度大为减缓,在晶体管物理微缩和计算体系架构改进带来的收益之争中,后者渐处上风。
在此背景下,学术界和工业界纷纷将视野转向针对特定领域设计高性能的专用芯片,拟将架构设计发挥到极致。
AI芯片作为最为典型的领域专用芯片代表,受到国内外研发单位的高度关注。国外有谷歌、苹果、英特尔、IBM、英伟达等巨头领衔,国内也有寒武纪、地平线、深鉴、华为、阿里等公司响应,最近清华大学的天机芯更是登上了Nature杂志的封面[1],其形势可谓如日中天。![]()

然而,AI芯片中所谓的“智能”究竟源自于哪些模型,又和我们的大脑有何关系,他们的过去和未来将会怎样,本文带你一探究竟。
人工神经网络
基本模型
深度学习又是当今机器学习的宠儿,其以人工神经网络(Artificial Neural Network, ANN)为主要模型。
ANN由大量神经元(Neuron)通过突触(synapse)连接而成,从输入到输出呈现层级结构,当层数较多时则被称为深度神经网络(Deep Neural Networks)。
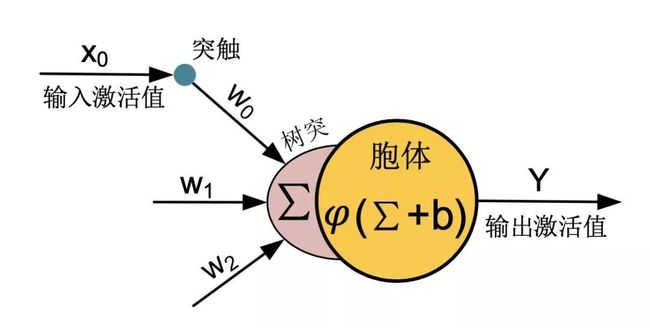 图1 人工神经元示意图
图1 人工神经元示意图
每个神经元的基本结构如图1所示,而基本的计算原理为
![]() ,其中x
,其中x![]() 和y
和y![]() 分别为输入和输出激活值、
分别为输入和输出激活值、![]()
![]() w为突触连接的权重值、
w为突触连接的权重值、![]() b为偏置值、
b为偏置值、![]() φ为非线性激活函数。
φ为非线性激活函数。![]()
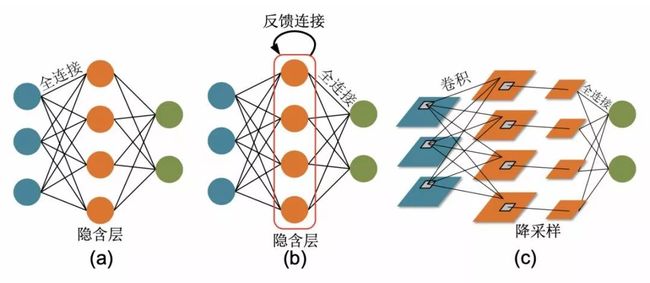
(a) 全连接神经网络;(b) 反馈神经网络;(c)卷积神经网络。
根据神经元的连接拓扑可以分为全连接神经网络、卷积神经网络、反馈神经网络等,如图2所示。
相比于全连接神经网络,卷积神经网络通过引入二维特征图与突触核的卷积操作获得了强大的局部特征提取能力,被广泛用于图像处理领域。
而反馈神经网络通过引入反馈连接,建立时序动力学模型,被广泛用于处理语音文本等时序数据。
其实,ANNs模型的建立也是在不同时期中分别借鉴了神经科学的知识:
![]()
人工神经网络的概念以及基本神经元模型于1943年就已提出[2],这正是试图模拟脑皮层以神经元网络形式进行信息处理的体现。
卷积神经网络的局部感受野是受到大脑视觉系统的启发。
深度神经网络的层级构建是源于脑皮层的分层通路。
只不过在深度学习的后续发展中,研究者更加偏重把神经网络视为一个黑匣,用于拟合从输入到输出的复杂映射关系:
![]()
只需要给网络的输出定义一个收敛目标(目标函数,比如每张图像的输出对应到正确的类别)并描述为一个优化问题,然后用梯度下降的方式去更新系统参数主要是突触权重,使得输出逐渐逼近想要的结果。
原则上网络越大,特征提取的能力就会越强,也就需要越多的数据来训练网络更新参数使网络收敛,因此计算量也大幅增加。
故而,深度学习也被称为数据和算力驱动的智能。虽然深度学习以解决实际应用为目标而与神经科学渐行渐远,但近两年也有科学家试图在大脑中找到梯度下降的证据和吸收新的脑科学成果[3-8]。
深度学习的腾飞之路
20世纪末到21世纪初很长一段时间内神经网络方法不被多数人看好,其表现也不如传统机器学习模型,多亏图灵奖得主Hinton、LeCun和Bengio三位前辈的坚持,才有了今天的成就。
深度学习的飞速发展主要归功于大型数据库的诞生(如ImageNet)、高性能计算平台(如GPUs)的出现、友好开发软件的耕耘(如Tensorflow/Pytorch等)和神经网络模型的改进(如卷积神经网中的VGG/Inception/ResNet/DenseNet),缺一不可。
由于成熟的算法、工具和应用场景,深度学习受到学术界和工业界的一致认可。深度学习加速器也现身各大学术顶会,并受到巨头公司和创业公司的青睐,这其中就包括研发TPU的谷歌、手机内置神经引擎的苹果以及国内的寒武纪、地平线、深鉴科技、华为、阿里等,当前主要热门方向为研制运行ANNs模型的高性能云计算平台和低功耗终端器件。
脉冲神经网络
基本模型
与深度学习不同,神经形态计算(neuromorphic computing)是目前智能模型中的又一大主要分支,它更加注重模拟大脑回路的行为,这里给大家介绍两类神经形态模型:脉冲神经网络(Spiking Neural Network, SNN)和神经动力学网络(Neural Dynamic Network)。
SNN与ANN主要有两大不同,其一是采用脉冲编码—spike code(0/1),其二是具有丰富的时间动力学。SNN神经元如图3所示,其模型可简单描述为:
![]()

其中,![]() (t)为时间步,t
(t)为时间步,t![]() 是时间常数,
是时间常数,![]() u为神经元膜电位,
u为神经元膜电位,![]() s为神经元的脉冲输出,
s为神经元的脉冲输出,
![]() 和
和![]()
 分别为神经元静息电位和重置电位,
分别为神经元静息电位和重置电位,![]()
 为脉冲发放阈值,
为脉冲发放阈值,
![]() 表示每个神经元会累加对应突触输入脉冲序列中一定时间窗
表示每个神经元会累加对应突触输入脉冲序列中一定时间窗
![]() 内的脉冲信号,
内的脉冲信号,![]()
 用于刻画时间衰减效应(距离当前时刻越近的脉冲输入对膜电位影响越大)。
用于刻画时间衰减效应(距离当前时刻越近的脉冲输入对膜电位影响越大)。
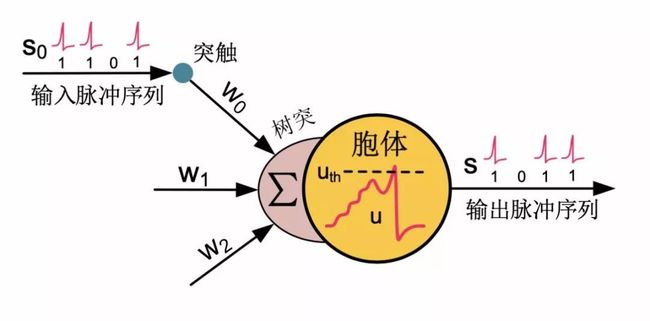
图3 脉冲神经元示意图
135编辑器
虽然上述以微分方程为基础的SNN神经元模型看起来比ANN模型更为复杂,但它已经是最为简化的SNN模型了,被称为泄漏积分发放模型(Leaky Integrate and Fire, LIF)[9],其它更为复杂的模型如Izhikevich[10]和Hodgkin & Huxley[11]仅凭借现有计算机还难以仿真大规模网络。
原理上,SNN的时间积分效应可以使得其能够处理时序问题,尤其是稀疏数据(事实上大脑神经元发放频率也是非常稀疏的);其膜电位泄漏和阈值发放效应,进一步使得其能够具有一定的去噪功能(事实上大脑脉冲信号也具有很多噪音,但大脑仍能正常工作)。
这两个特性,目前的ANN模型都不具备(反馈神经网络尽管具备时域处理能力,但与SNN很不相同)。虽然理论上有较大潜力,但由于SNN神经元的多变量时空动力学比较复杂,而脉冲发放活动又不可导,导致其无法使用具有全局性的梯度下降算法进行学习。
135编辑器
在相当长一段时间里,其主要的学习规则都是非监督的脑启发STDP(spike timing dependent plasticity)规则[12],仅利用突触两端神经元的局部脉冲响应来更新突触权重以满足学习目标。
虽然STDP具有一定的生物基础,但它太过于局部化,难以获得类似梯度下降算法的全局优化能力,导致其在诸多应用中表现差于ANN模型。
直到最近三年,才有研究者通过将预先采用梯度下降算法训练好的ANN模型转换为其SNN版本[13,14],或者通过对脉冲发放函数进行导数逼近,进而直接计算每个时刻膜电位和脉冲活动的梯度以实现基于梯度下降的有监督算法学习[15,16],这些努力逐渐使得SNN的应用性能接近目前的ANN模型。
争议丛生但未来可期
支持SNN的器件通常称为神经形态器件(如欧洲的SpiNNaker[17]和DYNAP[18],IBM的TrueNorth[19],Intel的Loihi[20]),其研究的动机主要是因为SNN的类脑特性使其更有希望通过构建大规模系统获得类脑智能。
不过从应用角度出发,目前的神经形态器件大多只能体现低功耗的特性,这是由于SNN神经元的输入输出信号为二值脉冲的缘故,可以去除输入和突触权重运算中的笨重乘法,再加之脉冲活动非常稀疏且允许事件驱动的异步电路设计。
而在功能方面,SNN所表现出的性能尚不能与深度学习匹敌,这也是工业界对神经形态方案的热情有所消退甚至持怀疑和观望态度的原因。
135编辑器
但笔者认为,目前的神经形态计算还有很大的提升空间,未来仍有可期:
一方面,深度学习的进步是数据、算力、软件和模型共同进步的结果,非一日之功,而神经形态计算在上述优化上还处于起步阶段。期待研究者们继续从各个子领域努力前行,逐步迭代发展。
神经动力学网络
基本模型
这类模型通常用于研究脑回路的响应特性,成果相对分散。这里给大家介绍比较典型的连续吸引子网络(Continuous Attractor Neural Network, CANN)[21,22],其神经元模型可以简单总结为如下:
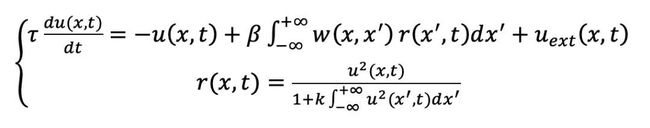
其中大多数变量含义与SNN类似。此外,![]() x为神经元在二维空间中的坐标位置(如图4所示,以二维CANN为例),
x为神经元在二维空间中的坐标位置(如图4所示,以二维CANN为例),
![]() 为两个对应位置神经元之间的突触连接权重,
为两个对应位置神经元之间的突触连接权重,![]() 是神经元发放频率,
是神经元发放频率,![]()
![]() 为外部刺激,β
为外部刺激,β![]() 和
和![]() k为常数。
k为常数。
可以看到,CANN把SNN中“从膜电位到脉冲信号”的转换调整为了“从膜电位到发放频率”的转换,公式中的除法归一化体现了大脑中普遍存在的神经元抑制作用,使得发放频率不会无限增长,整个系统趋于稳定。
135编辑器
在CANN中,突触权重通常配置为高斯峰形状,即
![]() ,相距越近的神经元连接越强,反之越弱,而α
,相距越近的神经元连接越强,反之越弱,而α![]() 控制着高斯峰的半径。如此,在没有外部刺激的时候,CANN模型的神经元发放频率响应也呈现稳定的高斯函数形状,称为响应波包(Bump),表示网络的一个吸引子状态。
控制着高斯峰的半径。如此,在没有外部刺激的时候,CANN模型的神经元发放频率响应也呈现稳定的高斯函数形状,称为响应波包(Bump),表示网络的一个吸引子状态。
CANN不仅有简洁的形式和特殊的动力学特性,在大脑中也具备生物学基础:
![]()
大脑中头朝向神经元在空间上沿着一个环分布构成一维CANN,神经元群活动可以预测头转动的趋势。
海马中的空间神经元(Place Cell)互相连接构成一个二维CANN,神经元活动的波包可以编码动物的空间位置,支持大脑的空间导航。
少数动物如蝙蝠的空间定位系统甚至会用到三维CANN。
关于CANN的计算原理、生物基础和应用场景的更多信息,感兴趣的读者可以参考北京大学吴思教授课题组微信公众号“吴思Lab计算神经科学及类脑计算”最近发布的CANN专帖【学术思想】连续吸引子神经网络:神经信息表达的正则化网络模型。
![]()

图4 二维CANN模型示意图
135编辑器
CANN的应用场景有很多,这里主要给大家详细描述目标追踪的实现[23]。当图4中二维神经元阵列对应到视频中的像素阵列、每个神经元的![]()
 接收对应位置像素强度的前后帧差分信号刺激时,网络便可实现目标追踪。
接收对应位置像素强度的前后帧差分信号刺激时,网络便可实现目标追踪。
详细而言,网络初始时对目标所在的方框区域初始化为高响应值,其他区域为0;开始运行后,网络所有神经元按照CANN规则进行计算,而目标所在区域的强差分输入会牵引着神经元响应波包平滑移动,波包位置对目标进行实时追踪。突触权重高斯峰的半径决定了追踪的性能:太宽则容易受邻近目标干扰,太窄则容易跟丢目标。
这种吸引子跟随外部输入的牵引而移动是CANN的特有动力学特性,对目标的追踪也非常平滑自然。除目标追踪的应用外,波包编码本身也是一种神经元群编码的体现,相比于单神经元编码,更具有鲁棒性。
另一方面,一簇CANN神经元可以处理某种模态信息的不同任务,也可以处理不同模态的信息,多簇CANN可以用长程连接进行信息交互,因此CANN也有潜力为大脑提供多模态信息处理的统一框架。
实际应用任重道远
前面讲述的深度学习和SNN都有对应的专用处理芯片,而神经动力学网络由于本身研究比较分散,应用也不成体系,在硬件中的实现仍较为少见。
MIT曾实现了十多个神经元的简单CANN模型[24],但并未引起重视。最近,清华大学的类脑芯片—天机芯通过对CANN模型突触连接的局部约束、数据的低精度化等硬件友好改造,实现了约800帧每秒的超快目标追踪[1,23]。
目前多数神经动力学网络还是以复现神经回路响应模式居多,距离实际应用还任重道远,需要持续不断地进行挖掘。
天机芯
跨域融合思想
上述模型各有特点和优缺点,孰优孰劣尚无定论。与现有深度学习加速器和神经形态器件分别支持ANN和SNN模型不同,天机芯[1]的目标是促进通用人工智能的发展,所以在保持专用芯片高效能的同时需要尽可能提高对上述模型支持的通用性。
由于不同模型的迥异计算原理、信息编码方式与应用场景,导致其所需的计算与存储架构以及优化目标相差较大,这点从现有深度学习加速器和神经形态器件的独立设计和应用体系可以看出来。这里需要注意的是,分别设计不同模型的专用模块再简单放置到一起是行不通的,原因如下。第一,很难确定各自的配置比例,因为现实应用中的工作负载往往是多变的;第二,面积和功耗都不高效,处理单一同构模型时,会导致总体利用率很低;第三,处理混合异构模型时,需要专门的信号转换单元,增加额外成本降低效率。
135编辑器
在天机芯的设计中,实现异构融合有两个关键点。首先,深入研究大多数目前的主流神经网络模型,包括人工神经网络、脉冲神经网络与神经动力学网络等,建立一个通用的模型描述框架,并把这些模型进行合理拆解后映射至包括轴突、树突、突触、胞体以及互连网络等基本模块上,归纳每个模块应具备的算子功能。每个模块都最大程度复用不同模型工作模式的存储和计算资源,所以最终面积只比单一模式高3%。
然后,基于现有神经形态芯片的众核可扩展架构(每个芯片中有许多个互相连接的基本功能核),并仔细设计上述几个基本模块,包括模式可独立配置的轴突和胞体(输入/输出模块),模式共享的树突和突触(运算模块),以及统一的路由协议和路由网络(连接模块)。当轴突和胞体工作在相同模式下,整个网络可支持典型单一同构模型;当轴突和胞体工作在不同模式下,整个网络可支持目前尚缺乏研究的混合异构模型,有望推动神经网络新模型的探索。
无人自行车应用演示
选择什么样的平台来演示天机芯的基本功能并非易事。首先,这应该是一个类似大脑的多模态系统,覆盖感知、决策和执行的完整链路,并能够为异构融合的多种模型提供任务支撑,这与目前很多AI系统演示的单一任务不同。其次,这应该是一个能够与现实环境交互的真实系统,而不是停留在机房实验。再者,这个系统最好对处理芯片有功耗和实时性要求,以体现专用芯片的优势。最后,这个系统必须是安全可控的,能够方便实验。综上所述,无人智能自行车平台应运而生,其具有语音识别、目标探测和追踪、运动控制、障碍躲避以及自主决策等功能,是一个运行在户外场景同时对功耗和实时性具有需求的一个嵌入式机器人,算得上是一个五脏俱全的小型类脑平台。
其中,目标探测采用的是ANN中的卷积神经网络,在相机采集的图像中探测目标位置;车身平衡控制采用的是ANN中的全连接神经网络,根据陀螺仪采集的车身姿态实现对转向电机的PID控制,保持自行车平衡;语音命令识别采用的是SNN模型,将语音信号转换为spike脉冲信号特征后进行命令分类;目标追踪便是前面介绍过的CANN模型;自主决策是一个有限状态机,实现上述不同模型的融合通信,因此是一个异构的混合模型。
135编辑器
总结
纵观当今的AI芯片,从计算机科学和神经科学角度寻求动机,采用了不同的神经网络模型,呈现了不同的硬件架构设计,应用和性能也各有所长。
笔者认为,在现阶段没有必要急着对各类途径分出胜负。
一方面应该继续保持研究的多样性,使各个领域迭代发展,毕竟每一条路线目前看来都不能保证成为终极方案。
另一方面,面对目前已知的各类神经网络模型,从数学根本上去探寻他们的表达能力差异从而寻求可控的大一统模型,也是很好的着力点。
科学研究的动机,并非仅仅是出于能看到多酷炫的应用,而是因为我们尚有诸多未知世界需要探寻,这是一切应用的前提。
参考文献
[1] Pei, Jing, Lei Deng, Sen Song, Mingguo Zhao, Youhui Zhang, Shuang Wu, Guanrui Wang et al. "Towards artificial general intelligence with hybrid Tianjic chip architecture." Nature 572, no. 7767 (2019): 106.
[2] McCulloch W S, Pitts W. A logical calculus of the ideas immanent in nervous activity. Bull Math Biophys, 1943, 5(4): 115–133.
[3] Sacramento, Joao, Rui Ponte Costa, Yoshua Bengio, and Walter Senn. "Dendritic error backpropagation in deep cortical microcircuits." arXiv preprint arXiv:1801.00062 (2017).
[4] Guerguiev, Jordan, Timothy P. Lillicrap, and Blake A. Richards. "Towards deep learning with segregated dendrites." ELife 6 (2017): e22901.
[5] Sabour, Sara, Nicholas Frosst, and Geoffrey E. Hinton. "Dynamic routing between capsules." In Advances in neural information processing systems, pp. 3856-3866. 2017.
[6] Roelfsema, Pieter R., and Anthony Holtmaat. "Control of synaptic plasticity in deep cortical networks." Nature Reviews Neuroscience 19, no. 3 (2018): 166.
[7] Marblestone, Adam H., Greg Wayne, and Konrad P. Kording. "Toward an integration of deep learning and neuroscience." Frontiers in computational neuroscience 10 (2016): 94.
[8] Ullman, Shimon. "Using neuroscience to develop artificial intelligence." Science 363, no. 6428 (2019): 692-693.
[9] Gerstner, Wulfram, Werner M. Kistler, Richard Naud, and Liam Paninski. Neuronal dynamics: From single neurons to networks and models of cognition. Cambridge University Press, 2014.
[10] Izhikevich, Eugene M. "Simple model of spiking neurons." IEEE Transactions on neural networks 14, no. 6 (2003): 1569-1572.
[11] Hodgkin, Alan L., and Andrew F. Huxley. "A quantitative description of membrane current and its application to conduction and excitation in nerve." The Journal of physiology117, no. 4 (1952): 500-544.
[12] Song, Sen, Kenneth D. Miller, and Larry F. Abbott. "Competitive Hebbian learning through spike-timing-dependent synaptic plasticity." Nature neuroscience 3, no. 9 (2000): 919.
[13] Diehl, Peter U., Daniel Neil, Jonathan Binas, Matthew Cook, Shih-Chii Liu, and Michael Pfeiffer. "Fast-classifying, high-accuracy spiking deep networks through weight and threshold balancing." In 2015 International Joint Conference on Neural Networks (IJCNN), pp. 1-8. IEEE, 2015.
[14] Sengupta, Abhronil, Yuting Ye, Robert Wang, Chiao Liu, and Kaushik Roy. "Going deeper in spiking neural networks: VGG and residual architectures." Frontiers in neuroscience 13 (2019).
[15] Wu, Yujie, Lei Deng, Guoqi Li, Jun Zhu, and Luping Shi. "Spatio-temporal backpropagation for training high-performance spiking neural networks." Frontiers in neuroscience 12 (2018).
[16] Wu, Yujie, Lei Deng, Guoqi Li, Jun Zhu, Yuan Xie, and Luping Shi. "Direct training for spiking neural networks: Faster, larger, better." In Proceedings of the AAAI Conference on Artificial Intelligence, vol. 33, pp. 1311-1318. 2019.
[17] Furber, Steve B., Francesco Galluppi, Steve Temple, and Luis A. Plana. "The spinnaker project." Proceedings of the IEEE102, no. 5 (2014): 652-665.
[18] Moradi, Saber, Ning Qiao, Fabio Stefanini, and Giacomo Indiveri. "A scalable multicore architecture with heterogeneous memory structures for dynamic neuromorphic asynchronous processors (dynaps)." IEEE transactions on biomedical circuits and systems 12, no. 1 (2017): 106-122.
[19] Merolla, Paul A., John V. Arthur, Rodrigo Alvarez-Icaza, Andrew S. Cassidy, Jun Sawada, Filipp Akopyan, Bryan L. Jackson et al. "A million spiking-neuron integrated circuit with a scalable communication network and interface." Science345, no. 6197 (2014): 668-673.
[20] Davies, Mike, Narayan Srinivasa, Tsung-Han Lin, Gautham Chinya, Yongqiang Cao, Sri Harsha Choday, Georgios Dimou et al. "Loihi: A neuromorphic manycore processor with on-chip learning." IEEE Micro 38, no. 1 (2018): 82-99.
[21] Wu, Si, Kosuke Hamaguchi, and Shun-ichi Amari. "Dynamics and computation of continuous attractors." Neural computation20, no. 4 (2008): 994-1025.
[22] Fung, CC Alan, KY Michael Wong, and Si Wu. "A moving bump in a continuous manifold: a comprehensive study of the tracking dynamics of continuous attractor neural networks." Neural Computation 22, no. 3 (2010): 752-792.
[23] Deng, Lei, Zhe Zou, Xin Ma, Ling Liang, Guanrui Wang, Xing Hu, Liu Liu, Jing Pei, Guoqi Li, and Yuan Xie. "Fast Object Tracking on a Many-Core Neural Network Chip." Frontiers in neuroscience 12 (2018).
脑人言,与大脑对话


张亚勤、刘慈欣、周鸿祎、王飞跃、约翰.翰兹联合推荐
这是一部力图破解21世纪前沿科技大爆发背后的规律与秘密,深度解读数十亿群体智能与数百亿机器智能如何经过50年形成互联网大脑模型,详细阐述互联网大脑为代表的超级智能如何深刻影响人类社会、产业与科技未来的最新著作。
《崛起的超级智能;互联网大脑如何影响科技未来》2019年7月中信出版社出版。刘锋著。了解详情请点击:【新书】崛起的超级智能:互联网大脑如何影响科技未来
未来智能实验室是人工智能学家与科学院相关机构联合成立的人工智能,互联网和脑科学交叉研究机构。
未来智能实验室的主要工作包括:建立AI智能系统智商评测体系,开展世界人工智能智商评测;开展互联网(城市)云脑研究计划,构建互联网(城市)云脑技术和企业图谱,为提升企业,行业与城市的智能水平服务。
如果您对实验室的研究感兴趣,欢迎加入未来智能实验室线上平台。扫描以下二维码或点击本文左下角“阅读原文”
