LinQ&EF任我行(三)--LinQ to SQL
LinQ&EF任我行(三)--LinQ to SQL
(原创:灰灰虫的家http://hi.baidu.com/grayworm)
LinQ to SQL可以用来取代传统的基于SQL语句的查询操作。在以后的数据访问层(DAL)中,我们可以使用LinQ to SQL实现数据库的CRUD操作,在执行的时候.net框架会把LinQ to SQL查询表达式转换成对应的SQL语句再去执行。使用LinQ to SQL可以借助于LinQ语法大大简化我们数据访问的代码量,并且还具有编译检查、智能感知和强类型表达式等优点。
LinQ to SQL从严格意义上来说不能算是一个ORM框架,它只对SQL Server起作用,并不能实现对各种关系型数据库进行透明的映射,所以我们通常把LinQ to SQL称为SQL Mapping框架。
LinQ to SQL都是对Table
一、LinQ to SQL的ORM
LinQ to SQL不但仅仅实现了对象/关系之间的映射,还提供了一个简单易用的图形化界面工具。通过这个工具可以为SQL200X每个表生成一个实体类,并在底层有关联的表的实体类之间生成一个实体关联,把数据库中表和表之间的“关联关系”彻底转换为对象与对象之间的“关联关系”。通过此关联可以直接访问到该对象和与该对象相关联的其它对象,不用再通过Join子句来实现多表关联查询了。这种关联实体的功能是LinQ和实体框架的重要功能。
这种把数据库中的表和外键封装成类和类之间的关联的优势在于开发人员可以把数据库中的抽象数据设计成现实生活中的对象,依照现实生活中的对象来管理代码世界中的对象数据。
使用LinQ to SQL的图形化界面快速实现表与实体之间的映射
1.在项目中添加新项,选择"LinQ to SQL Classes"

《图1》
2.打开“服务器资源管理器(Server Explorer)”选中要映射的表,并把它们拖到.dbml的设计器界面中。

《图2》
通过上面两步,不用写代码就可以实现出表与实体之间的映射。下面我们看看生成的代码结构。
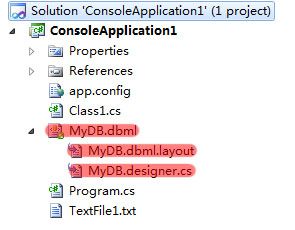
《图3》
从图中我们看出,在我们这简单的拖动过程中,VS为我们生成了三个文件:MyDB.dbml、MyDB.dbml.layout、MyDB.designer.cs
这三个类的代码分别如下所示:

《图4》
MyDB.dbml-XML文件,描述了表与实体之间的映射关系。如果我们直接从“服务器资源管理器”中向.dbml拖动表来使用LINQ的话,那些XML映射文件并不会起做用。因为LinQ还有映射方式:使用Attributes来映射,当我们从“服务器资源管理器”中直接拖动表到.dbml上去的时候,就是使用Attribute来映射的。在下面的MyDB.designer.cs文件中我们可以看到类和属性的上都带有Attributes属性,它用来描述实体类与表的映射关系。这种使用Attributes来实现映射,不是一种很好的映射方式,因为映射没有与代码完全分离,修改映射的过程本还需要对源代码进行修改,但这种使用LinQ的方式最为简单,所以也就成为大多数LinQ程序员的选择。
MyDB.dbml.layout-XML文件,描述了在LinQ to SQL图形化设计界面中图示的布局位置信息
MyDB.designer.cs-CSharp源代码文件,根据数据库的表结构,生成的实体类和DataContext类。
如果只从应用的角度上来讲,我们不用分析这三个文件的代码。但对于MyDB.designer.cs其中的类我们需要大体来看一下。
MyDB.desinger.cs文件中包含了系统自动生成的类,这些类大部份是数据库中表所对应的实体类,类的名子一般是以表名进行命名,如:Info,Family,Work,Nation,Title。另外还有一个类MyDBDataContext类,从字面意思上理解,该类是“MyDB数据上下文”,所谓的“上下文”就是指“硬盘上的关系型数据库”和“内存中的实体对象”,MyDBDataContext类的作用就是在“硬盘上的关系型数据库”和“内存中的实体对象”之间起一个桥梁的作用。这个类的代码中包含一系列的Table
在MyDB.desinger.cs文件的实体类中,包含诸多成员变量和属性的定义,这个成员变量除了对应于数据库中字段名,但还出现了EntitySet

《图5》
上面是Info表的实体类,除了_Code,_Name,_Sex,_Nation,_Birthday等数据库字段变量外,还有_Families和_Works,这两个成员变量对应Family表和Work表中,与当前对象相关联的实体对象的集合;而_Nation1则是与当前对象相关联的民族实体对象。
二、使用LinQ to SQL实现数据库的查询操作
LinQ to SQL的数据库操作是大多数程序员所钟情的功能,因为它能够把LinQ查询表达式自动转换为相应的SQL语句进行处理,这样就不用再花太多的时间去编写实体类和数据访问类了。LinQ to SQL的查询语句与LinQ to Objects语法很相似,只是LinQ to Objects是把LinQ表达式转换为中间语言,而LinQ to SQL是把LinQ表达式转换为SQL语句,送到数据库去执行。
下面以一个简单的例子来展示一下LinQ to SQL的使用,具体语法请参照上一篇文章。
示例:
在Info表中查询回族男生和汉族的女生中姓张的同学的信息
第一步:新建MyDB.dbml,并从服务器资源管理器中把相应的表拖进MyDB.dbml
第二步:添加新页面
第三步:实例化MyDBDataContext对象
MyDBDataContext context = new MyDBDataContext();
第三步:编写LinQ查询
var q = from p in context.Infos where p.Name.StartsWith("张") &&((p.Nation == "n002" && p.Sex == true) || (p.Nation == "n001" && p.Sex == false) ) select p;
或
var q = context.Infos.Where(p => p.Nation == "n002").Where(p => p.Sex == true).Concat(context.Infos.Where(p => p.Nation == "n001").Where(p => p.Sex == false)).Where(p=>p.Name.StartsWith("张"));
第四步:把查询序列转换成集合,并显示结果
var list = q.ToList();
foreach (Info item in list)
{
Console.WriteLine(item.Code + "/t" + item.Name + "/t" + (item.Sex.Value?"男":"女") + "/t" + item.Nation1.Name);
}
三、使用LinQ实现增、删、改操作
(一)添加操作
第一步:实例化DataContext对象
MyDBDataContext context = new MyDBDataContext();
第二步:生成实体对象
Info data = new Info
{
Code = "x004",
Name = "马大哈",
Sex = false,
Nation = "n001",
Birthday = new DateTime(1989, 12, 28)
};
第三步:向DataContext对象的Table
context.Infos.InsertOnSubmit(data);
也可以使用Table
第四步:使用DataContext对象提交更改
context.SubmitChanges();
(二)修改操作
第一步:实例化DataContext对象
MyDBDataContext context = new MyDBDataContext();
第二步:使用DataContext对象查询数据库中需要修改的内容,返回对应的实体对象
Info data = context.Infos.Where(p => p.Code == "x004").First();
第三步:修改上一步中实体对象中的值
data.Name = "马也";
data.Sex = true;
data.Nation = "n002";
第四步:使用DataContext对象提交更改
context.SubmitChanges();
修改数据时,由于要修改的数据本身就是数据库中现有的数据,所以不用像插入操作那样使用context.Infos.InsertOnSubmit(data)注册数据,直接修改数据并提交更改即可,
(三)删除操作
第一步:实例化DataContext对象
MyDBDataContext context = new MyDBDataContext();
第二步:使用DataContext对象查询数据库中需要修改的内容,返回对应的实体对象
Info data = context.Infos.Where(p => p.Code == "x004").First();
第三步:向DataContext对象的Table
context.Infos.DeleteOnSubmit(data);
也可以使用Table
第四步:使用DataContext对象提交更改
context.SubmitChanges();
上面的增、删、改查代码只有在context.SubmitChanges()调用的时候才提交数据库执行对应操作。我们可以在执行context.SubmitChanges()之前编写多项数据的增、删、改代码,然后使用context.SubmitChanges()实现一次性提交。context.SubmitChanges()方法自身带有事务功能,我们不必手动编写事务实现数据库的修改。
四、使用LinQ调用存储过程
在开发人员与DBA之间总是存在一种争论:使用在程序中使用存储过程是不是一种较好的解决方案?下面我们从四方面来看一下:
1.访问控制:
如果使用存储过程,可以为数据库创建自定义的用户或角色,并授权他们访问指定的存储过程,以提高数据操作的安全性。
2.SQL注入攻击
这种攻击通常是在执行动态SQL语句的时候发生,保存动态SQL语句的变量被恶意用户利用,通过输入的内容与原有SQL语句进行组合形成新的、具有攻击性的语句来对数据库操作。LinQ to SQL使用参数化查询方式来使用动态T-SQL语句,这种参数化的T-SQL语句能够很好的避免SQL注入攻击。所以并不是只有存储过程才能够解决SQL注入攻击。
3.性能
在SQL Server6.5或更早版本中,对存储过程可以实现部份编译的功能,当调用存储过程的时候可以加快SQL代码执行速度。在SQL Server7.0和以后的版本中对于存储过程和SQL语句都具有编译功能。因此,一般说来在SQL Server7.0以后的数据库版本,存储过程的执行与参数化的SQL代码执行效率没有什么太大的区别。
4.结构独立性
如果数据库的结构发生了变化,那与之相关的存储过程也需要重新编写、测试。如果软件升级时,不但需要重新编写、测试存储过程,还需要涉及到存储过程的更新。如果使用DAL来实现数据库操作的话,可以借助于代码生成工具,来实现数据访问代码的“半自动修改”,使用DAL层可以把数据库结构改变的影响控制在一个有限的局部范围内。
(一)添加存储过程
从服务器资源管理器中把存储过程直接拖放到.dbml界面中,在界面的右侧会出现相应的存储过程。

《图6》
右击.dbml界面中的存储过程,点击“属性”,打开属性面版,可以在这里修改存储过程的属性,在这里我们修改比较多的是Return Type,它代表存储过程的返回类型。

《图7》
在这个拖动过程中,会在.designer.cs中生成两段代码:一段是实体类,用来代表存储过程用到的实体对象(这个类只在调用增、删、改的存储过程中出现),如图8;另一段是在DataContext类中,用来实现存储过程的调用,如图9。

《图8》

《图9》
下面我们来看如何使用存储过程实现CRUD的操作。
(二)使用存储过程实现查询操作
1.把存储过程拖到.dbml界面中去。
2.编写代码调用存储过程

《图10》
在调用存储过程中,可以直接使用DataContext调用对应的存储过程调用方法,如果存储过程需要参数的话,我们可以把参数值直接传递给方法。
在LinQ中存储过程调用默认返回的类型是ISingleResult
(三)使用存储过程实现增、删、改操作
使用存储过程实现增、删、改操作可以有两种方式来实现:一种是使用DataContext对象直接调用存储过程调用方法。另一种是修改实体类的默认方法,把增、删、改操作默认方法指定为相当的存储过程。
第一种方法,使用DataContext对象直接调用存储过程的调用方法
1.把存储过程拖到.dbml界面中去。
2.编写代码调用存储过程

《图11》
第二种方法,修改实体类的默认方法
1.把存储过程拖到.dbml界面中去。
2.在.dbml文件中相应实体类上右击,选择“属性”,打开属性面版。

《图12》
3.在属性面版的Default Methods类别中单击相应的方法,打开对话框。

《图13》
在class下拉列表中选择要操作的实体类,在Behavior下拉列表中选择要对表进行的操作,在Customize下拉列表中选择对应的存储过程,在最下面的二维表格中选择存储过程参数与类的属性的对应关系。
4.编写代码对数据库进行增、删、改操作

《图14》
五、使LinQDataSource数据源控件
在Web应用程序中,可以使用数据源控件来向界面提供绑定的数据。LinQ to SQL能够为两种数据源对象提供数据:ObjectDataSource和LinqDataSource。
LinqDataSource控件是VS2008中的新增的数据源控件,它只能绑定到LinQ to SQL的DataContext.Table
ObjectDataSource控件也可以使用LinQ to SQL获取数据,因为DataContext.Table
下面我们一起来看一下,如何使用LinQ to SQL来实现数据绑定
第一步:添加LinQ to SQL类文件.dbml,并从“服务器资源管理器”拖动表到.dbml设计界面,生成LinQ to SQL类。
第二步:从工具箱中把LinqDataSource控件拖到界面中来。
第三步:在LinqDataSource控件的智能菜单中单击“配置数据源”,打开配置向导窗口。
第四步:在"Choose your context object"下拉列表中选择***DataContext。点击“Next”。

《图15》
第五步:在Table下拉列表中选择要在界面中显示的Table集合,在下面的列的列表中选择要显示的列。点击“Next”。

《图16》
第六步:(可选)如果想获取表中一部份数据的话,点击右侧的where按钮,在弹出对话框中来配置where表达式。这个配置界面与SqlDataSource和ObjectDataSource控件很像,在此不多说了。点击“OK”。

《图17》
第七步:(可选)如果要对显示的数据进行排序的话,请在图16中点击“OrderBy”按钮,在弹出对话框中设置排序规则。点击“OK”。

《图18》
第八步:(可选)如果想让LinqDataSource控件具有增、删、改的功能,在图16中点击“Advanced”按钮,在弹出下面对话框,在对话框中有三个复选框,只要选中它们,就可以实现增、删、改的功能。

《图19》
第九步:点击“Finish”按钮完成配置工作。
第十步:从工具箱中拖GridView到界面中来,设置DataSourceID为上面的LinqDataSource控件的ID。运行页面,出现效果如下:

《图20》
从图20中我们可以看出,表中的数据都被显示出来了,但是“Nation”这一列中显示的是代号,因为这一列是外键列,如何把它显示成民族名称呢。
在上面绑定数据的基础上,继续进行如下设置
第十一步:打开GridView的编辑列对话框。把EntityRef型字段(Nation1)添加到选中列中,再删除原有的Nation绑定列。

《图21》
第十二步:把Nation1转换为模板列。
第十三步:修改模板列的绑定代码如下:

《图22》
运行页面,看到民族名称显示出来了。

《图23》
至于Sex和Birthday字段的格式化显示,请参阅另外两篇文章:GridView详解 和 ListView详解
六、延迟加载与即时加载
延迟加载(Lazy Loading):只有在我们需要数据的时候才去数据库读取加载它。
优点:较好的性能,有效节省内存资源。
缺点:会产生多次与数据库之间的交互。
即时加载(Eager Loading):在加载数据时就把该对象相关联的其它表的数据一起加载到内存对象中去。
优点:能够一次性地把数据全加载到内存,不用反复与数据库之间进行交互操作
缺点:占用服务器内存较多,在加载相关联数据的时候,会用到连接查询,会降低性能。
在默认情况下,LinQ to SQL加载数据使用的是延迟加载。比如:在我加载某个Info对象的时候,并不会立即加载该Info对象的Works、Families和Nation1三个成员对象,只有在我们访问到该对象的这三个成员的时候才会动态加载该Info对象相对应的三个对象的内容。
与延迟加载密切相关的属性有两个:DataContext.DeferredLoadingEnabled和DataContext.LoadOptions
DataContext.DeferredLoadingEnabled:是否采用延迟加载。True-(默认值)采用延迟加载;False-不采用延迟加载(也不采用即时加载,加载的时候只加载当前对象的数据。当我们访问相关联子对象的时候也不会动态加载子对象的数据)
DataContext.LoadOptions:加载选项,用来指定那些子对象采用即时加载方式。
首先,我们来看看在默认情况下,即“延迟加载”的情况下,DataContext对象的结构:

《图24》
从图24我们可以看出,在默认情况下,DataContext对象DeferredLoadingEnabled=true,即采用了延迟加载的方式。LoadOptions=null,即没有对任何子对象进行即时加载操作。
下面我们再看看DataContext中Table

《图25》
从图25中我们可以看出,当我们访问Info对象的Works集合时,集合中会包含对应的数据,这些数据就是在访问该Works属性时动态从数据库中提取出来的。图中虽然有个IsDeffered=false,但这不代表该Works集合没有延迟加载,它代表Works集合是否正处于延迟状态,还未被执行查询。
再从生成的SQL语句中来看

《图26》
我们看到生成的SQL语句仅仅是对Info表的数据进行查询。并没有查询Works表和Families表中的数据,这两个表中的数据是在后面被延迟加载的。
下面我们再看看“非延迟加载”的情况。
需要大家注意的是:“非延迟加载”并不一定是“即时加载”,它两个不是一个概念。
要实现“非延迟加载”需要把DataContext对象的DeferredLoadingEnabled属性设为False。
然后我们再来看DataContext中的Table

《图27》
从上图中我们看出在“非延迟加载”情况下,并不会自动加载子对象的数据。
它所生成的语句与 图26是一样的。不一样的是,当我们访问Works集合时并没有动态加载相应的数据。
最后我们再来看看“即时加载”,“即时加载”与DataContext.DeferredLoadingEnabled的值没有太大的关系。它主要与DataContext.LoadOptions有关。
“即时加载”就是在加载Info对象的时候不只加载该对象的基本信息,它会把该对象的相关子对象(EntitySet和EntityRef)的数据一起加载出来,而不是等到用到的时候再加载。
下面我们看看如何使用“即时加载”来加载Info对象。

《图28》
从上图中我们可以看出,虽然DataContext.DeferredLoadingEnabled=false,但由于我使用了“即时加载”来加载了“Nation1”的数据,所以Nation1是有内容的。而Works和Families依然是Count=0
下面我们再看看“即时加载”生成的SQL语句

《图29》
从图中我们看到这是一个左连接的SQL语句,在查询的时候,不再只查Info表的数据,而是把相应的Nation表的数据一起查出来了。这就是即时加载的原理。
注意:对于一个DataContext对象,DataContext.LoadOptions属性只能赋一次值,一旦赋完值,我们将不能修改这个值了。因此,虽然DataLoadOptions提供了灵活的“即时加载”功能,但使用的时候一定要考虑清楚再使用。
附:LinQ的查询管道

《图30》