tensorflow serving安装、部署、调用、多模型版本管理教程
说明:该文档使用typora写的,由于typora的markdown格式与CSDN有一定的出入,导致显示有点小瑕疵,懒得改了,勿喷。
1. 准备模型
使用tf.keras训练一个简单的线性回归模型,保存为protobuf文件。
import tensorflow as tf
from tensorflow.keras import models,layers,optimizers
## 样本数量
n = 800
## 生成测试用数据集
X = tf.random.uniform([n,2],minval=-10,maxval=10)
w0 = tf.constant([[2.0],[-1.0]])
b0 = tf.constant(3.0)
Y = X@w0 + b0 + tf.random.normal([n,1],
mean = 0.0,stddev= 2.0) # @表示矩阵乘法,增加正态扰动
## 建立模型
tf.keras.backend.clear_session()
inputs = layers.Input(shape = (2,),name ="inputs") #设置输入名字为inputs
outputs = layers.Dense(1, name = "outputs")(inputs) #设置输出名字为outputs
linear = models.Model(inputs = inputs,outputs = outputs)
linear.summary()
## 使用fit方法进行训练
linear.compile(optimizer="rmsprop",loss="mse",metrics=["mae"])
linear.fit(X,Y,batch_size = 8,epochs = 100)
tf.print("w = ",linear.layers[1].kernel)
tf.print("b = ",linear.layers[1].bias)
## 将模型保存成pb格式文件
export_path = "linear_model/"
version = "1" #后续可以通过版本号进行模型版本迭代与管理
linear.save(export_path+version, save_format="tf")
查看模型
saved_model_cli show --dir=‘linear_model/1’ --all
MetaGraphDef with tag-set: 'serve' contains the following SignatureDefs:
signature_def['__saved_model_init_op']:
The given SavedModel SignatureDef contains the following input(s):
The given SavedModel SignatureDef contains the following output(s):
outputs['__saved_model_init_op'] tensor_info:
dtype: DT_INVALID
shape: unknown_rank
name: NoOp
Method name is:
signature_def['serving_default']: # 注意signature_def
The given SavedModel SignatureDef contains the following input(s):
inputs['inputs'] tensor_info: # 注意inputs
dtype: DT_FLOAT
shape: (-1, 2)
name: serving_default_inputs:0
The given SavedModel SignatureDef contains the following output(s):
outputs['outputs'] tensor_info:
dtype: DT_FLOAT
shape: (-1, 1)
name: StatefulPartitionedCall:0
Method name is: tensorflow/serving/predict
WARNING:tensorflow:From /usr/local/lib/python3.6/site-packages/tensorflow_core/python/ops/resource_variable_ops.py:1786: calling BaseResourceVariable.__init__ (from tensorflow.python.ops.resource_variable_ops) with constraint is deprecated and will be removed in a future version.
Instructions for updating:
If using Keras pass *_constraint arguments to layers.
Defined Functions:
Function Name: '__call__'
Option #1
Callable with:
Argument #1
inputs: TensorSpec(shape=(None, 2), dtype=tf.float32, name='inputs')
Argument #2
DType: bool
Value: True
Argument #3
DType: NoneType
Value: None
Option #2
Callable with:
Argument #1
inputs: TensorSpec(shape=(None, 2), dtype=tf.float32, name='inputs')
Argument #2
DType: bool
Value: False
Argument #3
DType: NoneType
Value: None
Function Name: '_default_save_signature'
Option #1
Callable with:
Argument #1
inputs: TensorSpec(shape=(None, 2), dtype=tf.float32, name='inputs')
Function Name: 'call_and_return_all_conditional_losses'
Option #1
Callable with:
Argument #1
inputs: TensorSpec(shape=(None, 2), dtype=tf.float32, name='inputs')
Argument #2
DType: bool
Value: False
Argument #3
DType: NoneType
Value: None
Option #2
Callable with:
Argument #1
inputs: TensorSpec(shape=(None, 2), dtype=tf.float32, name='inputs')
Argument #2
DType: bool
Value: True
Argument #3
DType: NoneType
Value: None
注意:请牢记上面的signature_def值和inputs值及其shape,在grpc调用的时候需要用到。
2. tensorflow/serving docker方式安装
-
拉取镜像
docker pull tensorflow/serving:latest
在docker hub中有四中镜像。
- :latest
- :lasest-gpu
- :lasest-devel
- :lasest-devel-gpu
两种划分共有4种镜像。CPU、GPU、稳定版、开发版。稳定版在dockerfile中启动tensorflow_model_server服务,创建容器即启动服务。开发版需要在创建容器之后,进入容器,手动启动tensorflow_model_server服务。
以下都已稳定版为例。
-
启动容器
docker run -t -p 8501:8501 -p 8500:8500 -v /root/mutimodel/linear_model:/models/linear_model -e MODEL_NAME=linear_model tensorflow/serving
备注:路径只需到模型这一级,不能精确到版本级别,比如:/root/mutimodel/linear_model而不是/root/mutimodel/linear_model/1,服务会默认加载最大版本号的模型。
参数解释:
-
-p : 端口映射,tensorflow serving提供了两种调用方式:gRPC和REST,
gRPC的默认端口是8500,REST的默认端口是8501. -
-v:目录映射,需要注意的是,在新版的docker中,已经移除了–mount type=bind,source=%source_path,target=$target_path的挂载目录方式。
-
-e:设置变量。
- 可选参数: MODLE_NAME(默认值:model)
- 可选参数:MODEL_BASE_PATH(默认值/models)
启动容器之后,相当于在容器中启动服务:
tensorflow_model_server --port=8500 --rest_api_port=8501 --model_name=${MODEL_NAME} --model_base_path=${MODEL_BASE_PATH}/${MODEL_NAME}
如果需要修改相关参数配置,可以通过如下命令:
docker run -p 8501:8501 -v /root/mutimodel/linear_model:/models/linear_model -t --entrypoint=tensorflow_model_server tensorflow/serving --port=8500 --model_name=linear_model --model_base_path=/models/linear_model --rest_api_port=8501
参数解释:
- -t --entrypoint=tensorflow_model_server tensorflow/serving:如果使用稳定版的docker,启动docker之后是不能进入容器内部bash环境的,–entrypoint的作用是允许你“间接”进入容器内部,然后调用tensorflow_model_server命令来启动TensorFlow Serving,这样才能输入后面的参数。
tensorflow serving的详细参数如下:
Flags: --port=8500 int32 Port to listen on for gRPC API --grpc_socket_path="" string If non-empty, listen to a UNIX socket for gRPC API on the given path. Can be either relative or absolute path. --rest_api_port=0 int32 Port to listen on for HTTP/REST API. If set to zero HTTP/REST API will not be exported. This port must be different than the one specified in --port. --rest_api_num_threads=16 int32 Number of threads for HTTP/REST API processing. If not set, will be auto set based on number of CPUs. --rest_api_timeout_in_ms=30000 int32 Timeout for HTTP/REST API calls. --enable_batching=false bool enable batching --batching_parameters_file="" string If non-empty, read an ascii BatchingParameters protobuf from the supplied file name and use the contained values instead of the defaults. --model_config_file="" string If non-empty, read an ascii ModelServerConfig protobuf from the supplied file name, and serve the models in that file. This config file can be used to specify multiple models to serve and other advanced parameters including non-default version policy. (If used, --model_name, --model_base_path are ignored.) --model_name="default" string name of model (ignored if --model_config_file flag is set) --model_base_path="" string path to export (ignored if --model_config_file flag is set, otherwise required) --max_num_load_retries=5 int32 maximum number of times it retries loading a model after the first failure, before giving up. If set to 0, a load is attempted only once. Default: 5 --load_retry_interval_micros=60000000 int64 The interval, in microseconds, between each servable load retry. If set negative, it doesn't wait. Default: 1 minute --file_system_poll_wait_seconds=1 int32 Interval in seconds between each poll of the filesystem for new model version. If set to zero poll will be exactly done once and not periodically. Setting this to negative value will disable polling entirely causing ModelServer to indefinitely wait for a new model at startup. Negative values are reserved for testing purposes only. --flush_filesystem_caches=true bool If true (the default), filesystem caches will be flushed after the initial load of all servables, and after each subsequent individual servable reload (if the number of load threads is 1). This reduces memory consumption of the model server, at the potential cost of cache misses if model files are accessed after servables are loaded. --tensorflow_session_parallelism=0 int64 Number of threads to use for running a Tensorflow session. Auto-configured by default.Note that this option is ignored if --platform_config_file is non-empty. --tensorflow_intra_op_parallelism=0 int64 Number of threads to use to parallelize the executionof an individual op. Auto-configured by default.Note that this option is ignored if --platform_config_file is non-empty. --tensorflow_inter_op_parallelism=0 int64 Controls the number of operators that can be executed simultaneously. Auto-configured by default.Note that this option is ignored if --platform_config_file is non-empty. --ssl_config_file="" string If non-empty, read an ascii SSLConfig protobuf from the supplied file name and set up a secure gRPC channel --platform_config_file="" string If non-empty, read an ascii PlatformConfigMap protobuf from the supplied file name, and use that platform config instead of the Tensorflow platform. (If used, --enable_batching is ignored.) --per_process_gpu_memory_fraction=0.000000 float Fraction that each process occupies of the GPU memory space the value is between 0.0 and 1.0 (with 0.0 as the default) If 1.0, the server will allocate all the memory when the server starts, If 0.0, Tensorflow will automatically select a value. --saved_model_tags="serve" string Comma-separated set of tags corresponding to the meta graph def to load from SavedModel. --grpc_channel_arguments="" string A comma separated list of arguments to be passed to the grpc server. (e.g. grpc.max_connection_age_ms=2000) --enable_model_warmup=true bool Enables model warmup, which triggers lazy initializations (such as TF optimizations) at load time, to reduce first request latency. --version=false bool Display version容器启动成功。
…
tensorflow_serving/servables/tensorflow/saved_model_warmup.cc:105] No warmup data file found at /models/linear_model/1/assets.extra/tf_serving_warmup_requests
2020-03-19 01:25:24.979107: I tensorflow_serving/core/loader_harness.cc:87] Successfully loaded servable version {name: linear_model version: 1}
2020-03-19 01:25:24.982357: I tensorflow_serving/model_servers/server.cc:358] Running gRPC ModelServer at 0.0.0.0:8500 …
2020-03-19 01:25:24.982960: I tensorflow_serving/model_servers/server.cc:378] Exporting HTTP/REST API at:localhost:8501 …
[evhttp_server.cc : 238] NET_LOG: Entering the event loop …可以看到,启动了grpc的8500端口和RESR的8501端口。
-
2. REST调用
REST api方式调用很简单,可以通过curl或者postman发送一个post请求,也可以用python的requests模拟一个post请求。这里我们使用postman工具。
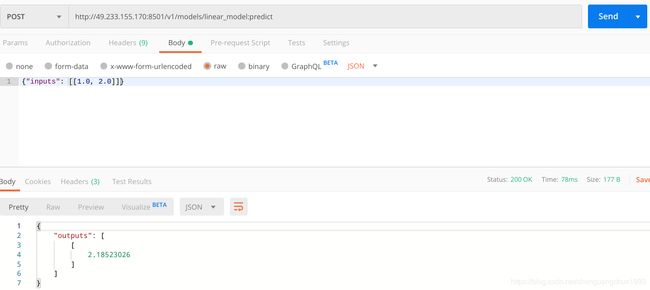
可以看到正确返回结果。
注意事项:
- 请求参数:“inputs”,这里对应于模型中的signature_def下面的inputs值。
- 参数形状:参见tensor_info的shape:(-1, 2)。
- 参数类型:参见tensor_info的dtype:DT_FLOAT(对应于np.float32)
3. grpc调用
-
安装相应的包
pip install tensorflow-serving-api
-
编写代码如下:
import grpc import tensorflow as tf from tensorflow_serving.apis import predict_pb2 from tensorflow_serving.apis import prediction_service_pb2_grpc options = [('grpc.max_send_message_length', 1000 * 1024 * 1024), ('grpc.max_receive_message_length', 1000 * 1024 * 1024)] channel = grpc.insecure_channel('ip:8500', options=options) stub = prediction_service_pb2_grpc.PredictionServiceStub(channel) x = [[1.0, 2.0]] request = predict_pb2.PredictRequest() request.model_spec.name = "linear_model" request.model_spec.signature_name = 'serving_default' request.inputs['inputs'].CopyFrom(tf.make_tensor_proto(x, shape=(1, 2))) response = stub.Predict(request, 10.0) output = tf.make_ndarray(response.outputs["outputs"])[0][0] print(output)注意事项:
- request.model_spec.name:模型名
- request.model_spec.signature_name:必须与模型中定义的一致,参照signature_def值(参见第一节查看模型)
- request.inputs[‘inputs’]:inputs的key参见tensor_info的inputs值(第一节查看模型)
4. 多模型部署
单一模型部署,上面的方式即可完成。对于多个模型统一部署,基本流程与单模型一致,不同之处在于需要借助模型的配置文件来完成。
- model.config
新建mutimodel文件夹,放置多个模型,并建一配置文件model.config.
mutimodel
├── linear_model
│ └── 1
│ ├── assets
│ ├── saved_model.pb
│ └── variables
│ ├── variables.data-00000-of-00001
│ └── variables.index
├── model.config
├── router_model
│ └── 1
│ ├── assets
│ ├── saved_model.pb
│ └── variables
│ ├── variables.data-00000-of-00001
│ └── variables.index
└── textcnn_model
└── 1
├── assets
├── saved_model.pb
└── variables
├── variables.data-00000-of-00001
└── variables.index12 directories, 10 files
model.conf配置如下:
model_config_list {
config {
name: 'linear',
model_platform: "tensorflow",
base_path: '/models/mutimodel/linear_model'
},
config {
name: 'textcnn',
model_platform: "tensorflow",
base_path: '/models/mutimodel/textcnn_model'
},
config {
name: 'router',
model_platform: "tensorflow",
base_path: '/models/mutimodel/router_model'
}
}
- 启动容器
docker run -p 8501:8501 -p 8500:8500 -v /root/mutimodel/:/models/mutimodel -t tensorflow/serving --model_config_file=/models/mutimodel/model.config
…
2020-03-19 0/models/mutimodel/router_model/1/assets.extra/tf_serving_warmup_requests
2020-03-19 02:42:58.197083: I tensorflow_serving/core/loader_harness.cc:87] Successfully loaded servable version {name: router version: 1}
2020-03-19 02:42:58.199987: I tensorflow_serving/model_servers/server.cc:358] Running gRPC ModelServer at 0.0.0.0:8500 …
2020-03-19 02:42:58.200632: I tensorflow_serving/model_servers/server.cc:378] Exporting HTTP/REST API at:localhost:8501 …
[evhttp_server.cc : 238] NET_LOG: Entering the event loop …
REST api 测试。

正常访问。
5. 版本控制
-
服务端配置
tensorflow serving服务默认只会读取最大版本号的版本(按数字来标记版本号),实际上,我们可以通过提供不同的版本的模型,比如提供稳定版、测试版,来实现版本控制,只需要在在配置文件中配置model_version_policy。
model_config_list { config { name: 'linear', model_platform: "tensorflow", base_path: '/models/mutimodel/linear_model' model_version_policy{ specific{ version: 1, version: 2 } } version_labels{ key: "stable", value: 1 } version_labels{ key: "test", value: 2 } } }这里我们同时提供版本号为1和版本号为2的版本,并分别为其取别名stable和test。这样做的好处在于,用户只需要定向到stable或者test版本,而不必关心具体的某个版本号,同时,在不通知用户的情况下,可以调整版本号,比如版本2稳定后,可以升级为稳定版,只需要将stable对应的value改为2即可。同样,若需要版本回滚,将value修改为之前的1即可。
启动服务
docker run -p 8501:8501 -p 8500:8500 -v /root/mutimodel/:/models/mutimodel -t tensorflow/serving --model_config_file=/models/mutimodel/model.config --allow_version_labels_for_unavailable_models=true说明:根据官方说明,添加别名只能针对已经加载的模型(先启动服务,再更新配置文件),若想在启动服务的时候设置别名,需要设置allow_version_labels_for_unavailable_models=true。
官方说明如下:
Please note that labels can only be assigned to model versions that are already loaded and available for serving. Once a model version is available, one may reload the model config on the fly to assign a label to it. This can be achieved using aHandleReloadConfigRequest RPC or if the server is set up to periodically poll the filesystem for the config file, as described above.
If you would like to assign a label to a version that is not yet loaded (for ex. by supplying both the model version and the label at startup time) then you must set the
--allow_version_labels_for_unavailable_modelsflag to true, which allows new labels to be assigned to model versions that are not loaded yet. -
客户端调用
特别说明:version_label设置别名的方式只适用于grpc调用方式,而不适用与REST调用。
-
REST 调用,直接制定版本号。
curl -d '{"inputs":[[1.0, 2.0]]}' -X POST http://localhost:8501/v1/models/linear/versions/1:predict { "outputs": [ [ 2.18523026 ] ] -
gRPC方式
使用别名:
channel = grpc.insecure_channel('49.233.155.170:8500') stub = prediction_service_pb2_grpc.PredictionServiceStub(channel) x = [[1.0, 2.0]] request = predict_pb2.PredictRequest() request.model_spec.name = "linear" request.model_spec.version_label = "stable" request.model_spec.signature_name = 'serving_default' request.inputs['inputs'].CopyFrom(tf.make_tensor_proto(x, shape=(1, 2))) response = stub.Predict(request, 10.0) output = tf.make_ndarray(response.outputs["outputs"])[0][0] print(output)使用版本号:
channel = grpc.insecure_channel('49.233.155.170:8500') stub = prediction_service_pb2_grpc.PredictionServiceStub(channel) x = [[1.0, 2.0]] request = predict_pb2.PredictRequest() request.model_spec.name = "linear" request.model_spec.version.value = 1 request.model_spec.signature_name = 'serving_default' request.inputs['inputs'].CopyFrom(tf.make_tensor_proto(x, shape=(1, 2))) response = stub.Predict(request, 10.0) output = tf.make_ndarray(response.outputs["outputs"])[0][0] print(output)区别:model_spec.version_label与model_spec.version.value。
-
6. 热更新
服务启动后,可以通过重新加载配置文件的方式来实现模型的热更新。可以通过一下两种方式来实现。
-
HandleReloadConfigRequest (grpc)
比如我们想新增模型textcnn和router。先更新其配置文件model.config为:
model_config_list { config { name: "linear" base_path: "/models/mutimodel/linear_model" model_platform: "tensorflow" model_version_policy { specific { versions: 1 versions: 2 } } version_labels { key: "stable" value: 1 } } config { name: "textcnn" base_path: "/models/mutimodel/textcnn_model" model_platform: "tensorflow" } config { name: "router" base_path: "/models/mutimodel/router_model" model_platform: "tensorflow" } }gRPC代码如下:
from google.protobuf import text_format from tensorflow_serving.apis import model_management_pb2 from tensorflow_serving.apis import model_service_pb2_grpc from tensorflow_serving.config import model_server_config_pb2 config_file = "model.config" stub = model_service_pb2_grpc.ModelServiceStub(channel) request = model_management_pb2.ReloadConfigRequest() # # read config file config_content = open(config_file, "r").read() model_server_config = model_server_config_pb2.ModelServerConfig() model_server_config = text_format.Parse(text=config_content, message=model_server_config) request.config.CopyFrom(model_server_config) request_response = stub.HandleReloadConfigRequest(request, 10) if request_response.status.error_code == 0: open(config_file, "w").write(str(request.config)) print("TF Serving config file updated.") else: print("Failed to update config file.") print(request_response.status.error_code) print(request_response.status.error_message)测试textcnn模型。
(train_data, train_labels), (test_data, test_labels) = datasets.imdb.load_data(num_words=10000) test_data = pad_sequences(test_data, maxlen=200) test_data = test_data.astype(np.float32) request = predict_pb2.PredictRequest() request.model_spec.name = 'textcnn' request.model_spec.signature_name = 'serving_default' request.inputs['input_1'].CopyFrom(tf.make_tensor_proto(np.array(test_data[0]), shape=(1, 200))) start = time.time() response = stub.Predict(request, 10.0) print("cost time = ", time.time() - start) res_from_server_np = tf.make_ndarray(response.outputs["dense"])[0][0] label = 1 if res_from_server_np > 0.5 else 0 print(label)cost time = 0.1668863296508789 0模型新增成功。
-
–model_config_file_poll_wait_seconds
在启动服务的时候,指定重新加载配置文件的时间间隔60s。
docker run -p 8501:8501 -p 8500:8500 -v /root/mutimodel/:/models/mutimodel -t tensorflow/serving --model_config_file=/models/mutimodel/model.config --allow_version_labels_for_unavailable_models=true --model_config_file_poll_wait_seconds=60
立即调用textcnn,可以看到报如下错误。很明显,此时服务并没有加载textcnn模型。
grpc._channel._Rendezvous: <_Rendezvous of RPC that terminated with:
status = StatusCode.NOT_FOUND
details = “Servable not found for request: Latest(textcnn)”
debug_error_string = “{“created”:”@1584608241.949779831",“description”:“Error received from peer ipv4:49.233.155.170:8500”,“file”:“src/core/lib/surface/call.cc”,“file_line”:1055,“grpc_message”:“Servable not found for request: Latest(textcnn)”,“grpc_status”:5}"
60s之后,观察到服务出现变化,显示已经加载模型textcnn和router。
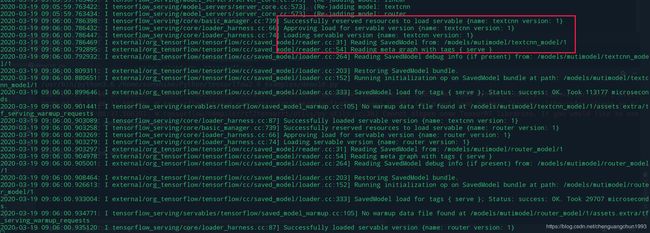
此时,再次调用textcnn模型
cost time = 0.1185760498046875
0
正确返回,模型更新成功。
引用:
https://blog.csdn.net/zong596568821xp/article/details/102953720
https://blog.csdn.net/weixin_44899143/article/details/90715186?depth_1-utm_source=distribute.pc_relevant.none-task&utm_source=distribute.pc_relevant.none-task#model_config_file_43
https://blog.csdn.net/JerryZhang__/article/details/86516428
https://stackoverflow.com/questions/54440762/tensorflow-serving-update-model-config-add-additional-models-at-runtime
https://www.tensorflow.org/tfx/serving/serving_config