区别VAN与GAN,LSGAN、WGAN、WGAN-GP、CGAN
训练”稳定”,样本的”多样性”和”清晰度”似乎是GAN的 3大指标 — David 9
VAE与GAN
聊到随机样本生成, 不得不提VAE与GAN, VAE用KL-divergence和encoder-decoder的方式逼近真实分布. 但这些年GAN因其”端到端”灵活性和隐式的目标函数得到广泛青睐. 而且, GAN更倾向于生成清晰的图像:

VAE与GAN生成对比
GAN在10次Epoch后就可以生成较清晰的样本, 而VAE的生成样本依旧比较模糊. 所以GAN大盘点前, 我们先比较一下VAE与GAN的结构差别:
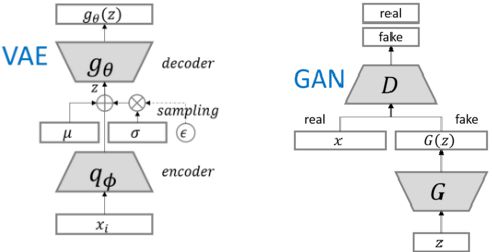
VAE与GAN结构比较
VAE训练完全依靠一个假设的loss函数和KL-divergence逼近真实分布:
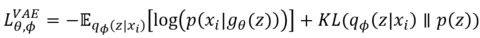 GAN则没有假设单个loss函数, 而是让判别器D和生成器G之间进行一种零和博弈, 一方面, 生成器G要以生成假样本为目的(loss评估), 欺骗判别器D误认为是真实样本:
GAN则没有假设单个loss函数, 而是让判别器D和生成器G之间进行一种零和博弈, 一方面, 生成器G要以生成假样本为目的(loss评估), 欺骗判别器D误认为是真实样本:
 另一方面, 判别器D要以区分真实样本x和假样本G(z)为最终目的(loss评估):
另一方面, 判别器D要以区分真实样本x和假样本G(z)为最终目的(loss评估):
 一般, 判别器D在GAN训练中是比生成器G更强的网络, 毕竟, 网络G要从D的判别过程中学到”以假乱真”的方法. 所以, 很大程度上, G是跟着D学习的.
一般, 判别器D在GAN训练中是比生成器G更强的网络, 毕竟, 网络G要从D的判别过程中学到”以假乱真”的方法. 所以, 很大程度上, G是跟着D学习的.
当然, 生成对抗网络也有一些问题, 比如经常很难训练(DCGAN试图解决), 有时候(特别是高像素图像), GAN生成图像不清晰, 还有时候, 生成图片多样性太差(只是对真实样本的简单改动).
这些问题, 催生出近年来各种有意思的GAN改进算法:
LSGAN(最小二乘GAN)
传统GAN中, D网络和G网络都是用简单的交叉熵loss做更新, 最小二乘GAN则用最小二乘(Least Squares) Loss 做更新:
选择最小二乘Loss做更新有两个好处, 1. 更严格地惩罚远离数据集的离群Fake sample, 使得生成图片更接近真实数据(同时图像也更清晰) 2. 最小二乘保证离群sample惩罚更大, 解决了原本GAN训练不充分(不稳定)的问题:
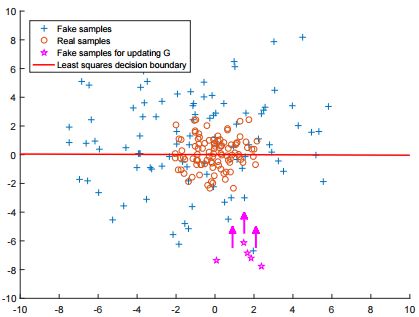
来自: https://arxiv.org/pdf/1611.04076.pdf
但缺点也是明显的, LSGAN对离离群点的过度惩罚, 可能导致样本生成的”多样性”降低, 生成样本很可能只是对真实样本的简单”模仿”和细微改动.
WGAN
DCGAN用经验告诉我们什么是比较稳定的GAN网络结构, 而WGAN告诉我们: 不用精巧的网络设计和训练过程, 也能训练一个稳定的GAN.
WGAN 通过剪裁D网络参数的方式, 对D网络进行稳定更新(Facebook采用了一种名叫”Earth-Mover“的距离来度量分布相似度).

来自: https://arxiv.org/pdf/1701.07875.pdf
但是, 有时一味地通过裁剪weight参数的方式保证训练稳定性, 可能导致生成低质量低清晰度的图片.
WGAN-GP
为了解决WGAN有时生成低质量图片的问题, WGAN-GP舍弃裁剪D网络weights参数的方式, 而是采用裁剪D网络梯度的方式(依据输入数据裁剪), 以下是WGAN-GP的判别器D的Value函数和生成器G的Value函数:

WGAN-GP在某些情况下是WGAN的改进, 但是如果你已经用了一些可靠的GAN方法, 其实差距并不大:

条件生成的GAN
许多情况下,我们需要生成指定类的随机样本,这时就需要条件生成的GAN:
CGAN
CGAN是对条件生成GAN的最先尝试,方法也比较简单,直接在网络输入加入条件信息c,用来控制网络的条件输出模式:
 公式也相对简单:
公式也相对简单:

这样,使得生成指定label的样本成为可能:

来自:https://arxiv.org/pdf/1411.1784.pdf
参考文献:
- https://github.com/hwalsuklee/tensorflow-generative-model-collections
- https://github.com/xunhuang1995/SGAN