后缀树
转自:http://www.cnblogs.com/gaochundong/p/suffix_tree.html
后缀树
在《字符串匹配算法》一文中,我们熟悉了字符串匹配问题的形式定义:
- 文本(Text)是一个长度为 n 的数组 T[1..n];
- 模式(Pattern)是一个长度为 m 且 m≤n 的数组 P[1..m];
- T 和 P 中的元素都属于有限的字母表 Σ 表;
- 如果 0≤s≤n-m,并且 T[s+1..s+m] = P[1..m],即对 1≤j≤m,有 T[s+j] = P[j],则说模式 P 在文本 T 中出现且位移为 s,且称 s 是一个有效位移(Valid Shift)。
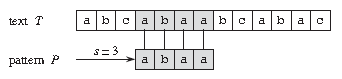
比如上图中,目标是找出所有在文本 T = abcabaabcabac 中模式 P = abaa 的所有出现。该模式在此文本中仅出现一次,即在位移 s = 3 处,位移 s = 3 是有效位移。
解决字符串匹配问题的常见算法有:
- 朴素的字符串匹配算法(Naive String Matching Algorithm)
- Knuth-Morris-Pratt 字符串匹配算法(即 KMP 算法)
- Boyer-Moore 字符串匹配算法
字符串匹配算法通常分为两个步骤:预处理(Preprocessing)和匹配(Matching)。所以算法的总运行时间为预处理和匹配的时间的总和。下图描述了常见字符串匹配算法的预处理和匹配时间。
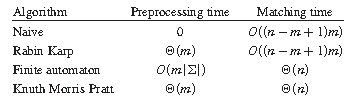
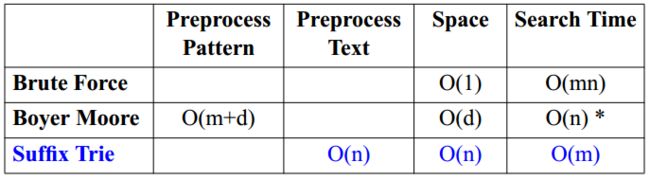
我们知道,上述字符串匹配算法均是通过对模式(Pattern)字符串进行预处理的方式来加快搜索速度。对 Pattern 进行预处理的最优复杂度为 O(m),其中 m 为 Pattern 字符串的长度。那么,有没有对文本(Text)进行预处理的算法呢?本文即将介绍一种对 Text 进行预处理的字符串匹配算法:后缀树(Suffix Tree)。
后缀树的性质:
- 存储所有 n(n-1)/2 个后缀需要 O(n) 的空间,n 为的文本(Text)的长度;
- 构建后缀树需要 O(dn) 的时间,d 为字符集的长度(alphabet);
- 对模式(Pattern)的查询需要 O(dm) 时间,m 为 Pattern 的长度;
在《字典树》一文中,介绍了一种特殊的树状信息检索数据结构:字典树(Trie)。Trie 将关键词中的字符按顺序添加到树中的节点上,这样从根节点开始遍历,就可以确定指定的关键词是否存在于 Trie 中。
下面是根据集合 {bear, bell, bid, bull, buy, sell, stock, stop} 所构建的 Trie 树。
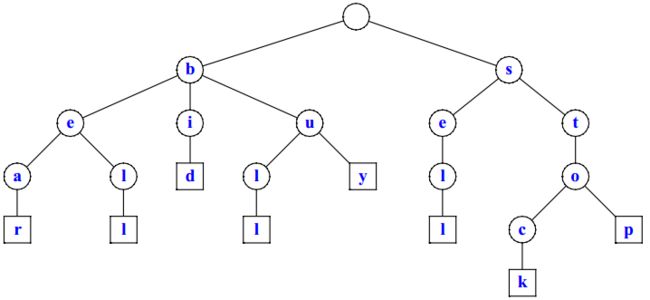
我们观察上面这颗 Trie,对于关键词 "bear",字符 "a" 和 "r" 所在的节点没有其他子节点,所以可以考虑将这两个节点合并,如下图所示。
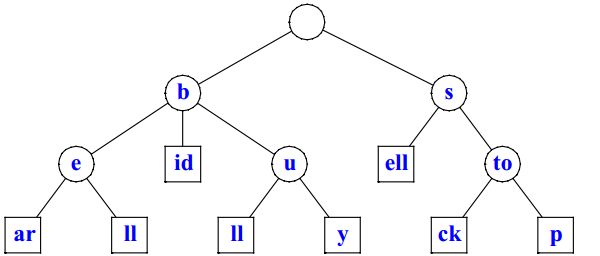
这样,我们就得到了一棵压缩过的 Trie,称为压缩字典树(Compressed Trie)。
而后缀树(Suffix Tree)则首先是一棵 Compressed Trie,其次,后缀树中存储的关键词为所有的后缀。这样,实际上我们也就得到了构建后缀树的抽象过程:
- 根据文本 Text 生成所有后缀的集合;
- 将每个后缀作为一个单独的关键词,构建一棵 Compressed Trie。
A suffix tree is a compressed trie for all the suffixes of a text.
比如,对于文本 "banana\0",其中 "\0" 作为文本结束符号。下面是该文本所对应的所有后缀。

banana\0 anana\0 nana\0 ana\0 na\0 a\0 \0
将每个后缀作为一个关键词,构建一棵 Trie。
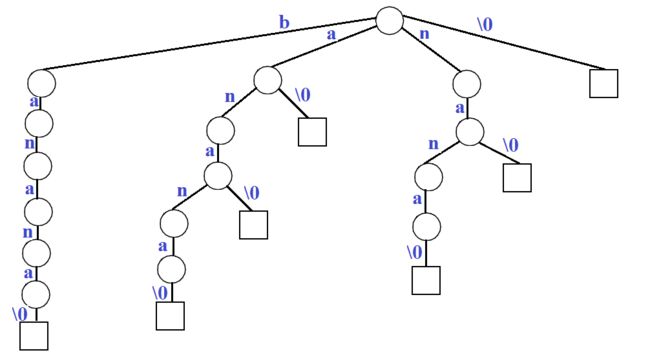
然后,将独立的节点合并,形成 Compressed Trie。
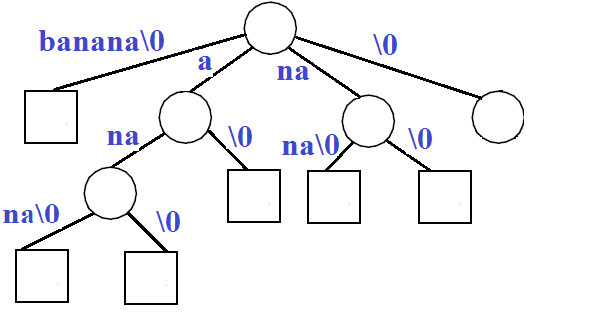
则上面这棵树就是文本 "banana\0" 所对应的后缀树。
现在我们先熟悉两个概念:显式后缀树(Explicit Suffix Tree)和隐式后缀树(Implicit Suffix Tree)。
下面用字符串 "xabxa" 举例说明两者的区别,其包括后缀列表如下。
xabxa
abxa
bxa
xa
a
我们发现,后缀 "xa" 和 "a" 已经分别包含在后缀 "xabxa" 和 "abxa" 的前缀中,这样构造出来的后缀树称为隐式后缀树(Implicit Suffix Tree)。

而如果不希望这样的情形发生,可以在每个后缀的结尾加上一个特殊字符,比如 "$" 或 "#" 等,这样我们就可以使得后缀保持唯一性。
xabxa$
abxa$
bxa$
xa$
a$
$
在 1995 年,Esko Ukkonen 发表了论文《On-line construction of suffix trees》,描述了在线性时间内构建后缀树的方法。下面尝试描述Ukkonen 算法的基本实现原理,从简单的字符串开始描述,然后扩展到更复杂的情形。
Suffix Tree 与Trie 的不同在于,边(Edge)不再只代表单个字符,而是通过一对整数 [from, to] 来表示。其中 from 和 to 所指向的是 Text 中的位置,这样每个边可以表示任意的长度,而且仅需两个指针,耗费 O(1) 的空间。
首先,我们从一个最简单的字符串 Text = "abc" 开始实践构建后缀树,"abc" 中没有重复字符,使得构建过程更简单些。构建过程的步骤是:从左到右,对逐个字符进行操作。
abc
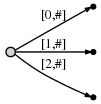
第 1 个字符是 "a",创建一条边从根节点(root)到叶节点,以 [0, #] 作为标签代表其在 Text 中的位置从 0 开始。使用 "#" 表示末尾,可以认为 "#" 在 "a" 的右侧,位置从 0 开始,则当前位置 "#" 在 1 位。
![]()
其代表的后缀意义如下。
![]()
第 1 个字符 "a" 处理完毕,开始处理第 2 个字符 "b"。涉及的操作包括:
- 扩展已经存在的边 "a" 至 "ab";
- 插入一条新边以表示 "b";

其代表的后缀意义如下。
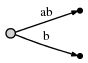
这里,我们观察到了两点:
- "ab" 边的表示 [0, #] 与之前是相同的,当 "#" 位置由 1 挪至 2 时,[0, #] 所代表的意义自动地发生了改变。
- 每条边的空间复杂度为 O(1),即只消耗两个指针,而与边所代表的字符数量无关;
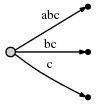
接着再处理第 3 个字符 "c",重复同样的操作,"#" 位置向后挪至第 3 位:
其代表的后缀意义如下。
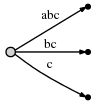
此时,我们观察到:
- 经过上面的步骤后,我们得到了一棵正确的后缀树;
- 操作步骤的数量与 Text 中的字符的数量一样多;
- 每个步骤的工作量是 O(1),因为已存在的边都是依据 "#" 的挪动而自动更改的,仅需为最后一个字符添加一条新边,所以时间复杂度为 O(1)。则,对于一个长度为 n 的 Text,共需要 O(n) 的时间构建后缀树。
当然,我们进展的这么顺利,完全是因为所操作的字符串 Text = "abc" 太简单,没有任何重复的字符。那么现在我们来处理一个更复杂一些的字符串 Text = "abcabxabcd"。
abcabxabcd
同上面的例子类似的是,这个新的 Text 同样以 "abc" 开头,但其后接着 "ab","x","abc","d" 等,并且出现了重复的字符。
前 3 个字符 "abc" 的操作步骤与上面介绍的相同,所以我们会得到下面这颗树:
当 "#" 继续向后挪动一位,即第 4 位时,隐含地意味着已有的边会自动的扩展为:
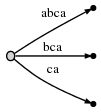
即 [0, #], [1, #], [2, #] 都进行了自动的扩展。按照上面的逻辑,此时应该为剩余后缀 "a" 创建一条单独的边。但,在做这件事之前,我们先引入两个概念。
- 活动点(active point),是一个三元组,包括(active_node, active_edge, active_length);
- 剩余后缀数(remainder),是一个整数,代表着还需要插入多少个新的后缀;
如何使用这两个概念将在下面逐步地说明。不过,现在我们可以先确定两件事:
- 在 Text = "abc" 的例子中,活动点(active point)总是 (root, '\0x', 0)。也就是说,活动节点(active_node)总是根节点(root),活动边(active_edge)是空字符 '\0x' 所指定的边,活动长度(active_length)是 0。
- 在每个步骤开始时,剩余后缀数(remainder)总是 1。意味着,每次我们要插入的新的后缀数目为 1,即最后一个字符。
# = 3, active_point = (root, '\0x', 1), remainder = 1
当处理第 4 字符 "a" 时,我们注意到,事实上已经存在一条边 "abca" 的前缀包含了后缀 "a"。在这种情况下:
- 我们不再向 root 插入一条全新的边,也就是 [3, #]。相反,既然后缀 "a" 已经被包含在树中的一条边上 "abca",我们保留它们原来的样子。
- 设置 active point 为 (root, 'a', 1),也就是说,active_node 仍为 root,active_edge 为 'a',active_length 为 1。这就意味着,活动点现在是从根节点开始,活动边是以 'a' 开头的某个边,而位置就是在这个边的第 1 位。这个活动边的首字符为 'a',实际上,仅会有一个边是以一个特定字符开头的。
- remainder 的值需要 +1,也就是 2。
# = 4, active_point = (root, 'a', 1), remainder = 2
此时,我们还观察到:当我们要插入的后缀已经存在于树中时,这颗树实际上根本就没有改变,我们仅修改了active point 和 remainder。那么,这颗树也就不再能准确地描述当前位置了,不过它却正确地包含了所有的后缀,即使是通过隐式的方式(Implicitly)。因此,处理修改变量,这一步没有其他工作,而修改变量的时间复杂度为 O(1)。
继续处理下一个字符 "b","#" 继续向后挪动一位,即第 5 位时,树被自动的更新为:
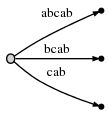
由于剩余后缀数(remainder)的值为 2,所以在当前位置,我们需要插入两个最终后缀 "ab" 和 "b"。这是因为:
- 前一步的 "a" 实际上没有被真正的插入到树中,所以它被遗留了下来(remained),然而我们又向前迈了一步,所以它现在由 "a" 延长到 "ab";
- 还有就是我们需要插入新的最终后缀 "b";
实际操作时,我们就是修改 active point,指向 "a" 后面的位置,并且要插入新的最终后缀 "b"。但是,同样的事情又发生了,"b" 事实上已经存在于树中一条边 "bcab" 的前缀上。那么,操作可以归纳为:
- 修改活动点为 (root, 'a', 2),实际还是与之前相同的边,只是将指向的位置向后挪到 "b",修改了 active_length,即 "ab"。
- 增加剩余后缀数(remainder)为 3,因为我们又没有为 "b" 插入全新的边。
# = 5, active_point = (root, 'a', 2), remainder = 3
再具体一点,我们本来准备插入两个最终后缀 "ab" 和 "b",但因为 "ab" 已经存在于其他的边的前缀中,所以我们只修改了活动点。对于 "b",我们甚至都没有考虑要插入,为什么呢?因为如果 "ab" 存在于树中,那么他的每个后缀都一定存在于树中。虽然仅仅是隐含性的,但却一定存在,因为我们一直以来就是按照这样的方式来构建这颗树的。
继续处理下一个字符 "x","#" 继续向后挪动一位,即第 6 位时,树被自动的更新为:
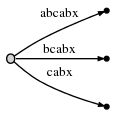
由于剩余后缀数(Remainder)的值为 3,所以在当前位置,我们需要插入 3 个最终后缀 "abx", "bx" 和 "x"。
活动点告诉了我们之前 "ab" 结束的位置,所以仅需跳过这一位置,插入新的 "x" 后缀。"x" 在树中还不存在,因此我们分裂 "abcabx" 边,插入一个内部节点:
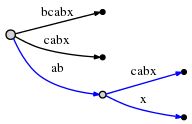
分裂和插入新的内部节点耗费 O(1) 时间。
现在,我们已经处理了 "abx",并且把 remainder 减为 2。然后继续插入下一个后缀 "bx",但做这个操作之前需要先更新活动点,这里我们先做下部分总结。
对于上面对边的分裂和插入新的边的操作,可以总结为 Rule 1,其应用于当 active_node 为 root 节点时。
Rule 1
当向根节点插入时遵循:
- active_node 保持为 root;
- active_edge 被设置为即将被插入的新后缀的首字符;
- active_length 减 1;
因此,新的活动点为 (root, 'b', 1),表明下一个插入一定会发生在边 "bcabx" 上,在 1 个字符之后,即 "b" 的后面。
# = 6, active_point = (root, 'b', 1), remainder = 2
我们需要检查 "x" 是否在 "b" 后面出现,如果出现了,就是我们上面见到过的样子,可以什么都不做,只更新活动点。如果未出现,则需要分裂边并插入新的边。
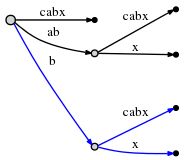
同样,这次操作也花费了 O(1) 时间。然后将 remainder 更新为 1,依据 Rule 1 活动点更新为 (root, 'x', 0)。
# = 6, active_point = (root, 'x', 0), remainder = 1
此时,我们将归纳出 Rule 2。
Rule 2
- 如果我们分裂(Split)一条边并且插入(Insert)一个新的节点,并且如果该新节点不是当前步骤中创建的第一个节点,则将先前插入的节点与该新节点通过一个特殊的指针连接,称为后缀连接(Suffix Link)。后缀连接通过一条虚线来表示。

继续上面的操作,插入最终后缀 "x"。因为活动点中的 active_length 已经降到 0,所以插入操作将发生在 root 上。由于没有以 "x" 为前缀的边,所以插入一条新的边:
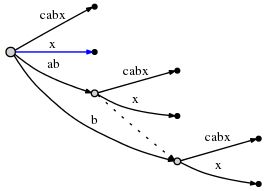
这样,这一步骤中的所有操作就完成了。
# = 6, active_point = (root, '\0x', 0), remainder = 1
继续处理下一个字符 "a","#" 继续向后挪动一位。发现后缀 "a" 已经存在于数中的边中,所以仅更新 active point 和 remainder。
# = 7, active_point = (root, 'a', 1), remainder = 2
继续处理下一个字符 "b","#" 继续向后挪动一位。发现后缀 "ab" 和 "b" 都已经存在于树中,所以仅更新 active point 和 remainder。这里我们先称 "ab" 所在的边的节点为 node1。
# = 8, active_point = (root, 'a', 2), remainder = 3
继续处理下一个字符 "c","#" 继续向后挪动一位。此时由于 remainder = 3,所以需要插入 "abc","bc","c" 三个后缀。"c" 实际上已经存在于 node1 后的边上。
# = 9, active_point = (node1, 'c', 1), remainder = 4
继续处理下一个字符 "d","#" 继续向后挪动一位。此时由于 remainder = 4,所以需要插入 "abcd","bcd","cd","d" 四个后缀。
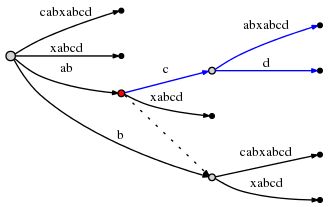
上图中的 active_node,当节点准备分裂时,被标记了红色。则归纳出了 Rule 3。
Rule 3
- 当从 active_node 不为 root 的节点分裂边时,我们沿着后缀连接(Suffix Link)的方向寻找节点,如果存在一个节点,则设置该节点为 active_noe;如果不存在,则设置 active_node 为 root。active_edge 和 active_length 保持不变。
所以,现在活动点为 (node2, 'c', 1),其中 node2 为下图中的红色节点:
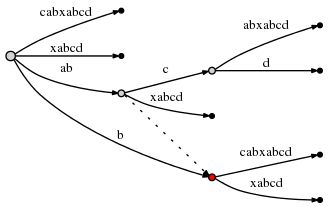
# = 10, active_point = (node2, 'c', 1), remainder = 3
由于对 "abcd" 的插入已经完成,所以将 remainder 的值减至 3,并且开始处理下一个剩余后缀 "bcd"。此时需要将边 "cabxabcd" 分裂,然后插入新的边 "d"。根据 Rule 2,我们需要在之前插入的节点与当前插入的节点间创建一条新的后缀连接。
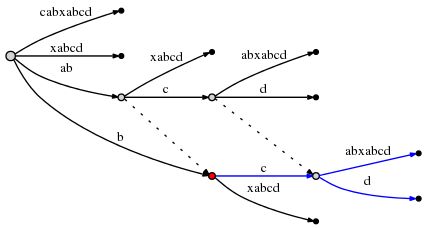
此时,我们观察到,后缀连接(Suffix Link)让我们能够重置活动点,使得对下一个后缀的插入操作仅需 O(1) 时间。从上图也确认了,"ab" 连接的是其后缀 "b",而 "abc" 连接的是其后缀 "bc"。
当前操作还没有完成,因为 remainder 是 2,根绝 Rule 3 我们需要重新设置活动点。因为上图中的红色 active_node 没有后缀连接(Suffix Link),所以活动点被设置为 root,也就是 (root, 'c', 1)。
# = 10, active_point = (root, 'c', 1), remainder = 2
因此,下一个插入操作 "cd" 将从 Root 开始,寻找以 "c" 为前缀的边 "cabxabcd",这也引起又一次分裂:
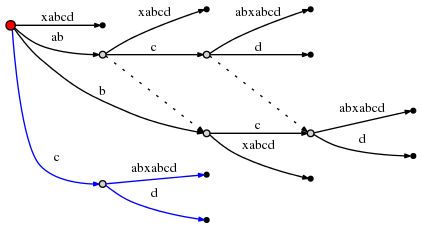
由于此处又创建了一个新的内部节点,依据 Rule 2,我们需要建立一条与前一个被创建内节点的后缀连接。
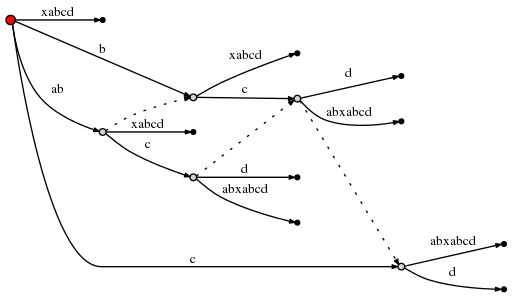
然后,remainder 减为 1,active_node 为 root,根据 Rule 1 则活动点为 (root, 'd', 0)。也就是说,仅需在根节点上插入一条 "d" 新边。
# = 10, active_point = (root, 'd', 0), remainder = 1
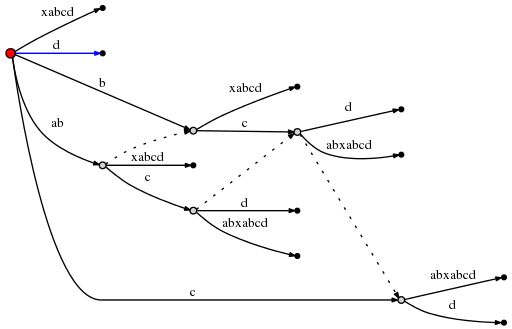
整个步骤完成。
总体上看,我们有一系列的观察结果:
- 在每一步中将 "#" 向右移动 1 位时,所有叶节点自动更新的时间为 O(1);
- 但实际上并没有处理这两种情况:
- 从前一步中遗留的后缀;
- 当前步骤中的最终字符;
- remainder 告诉了我们还余下多少后缀需要插入。这些插入操作将逐个的与当前位置 "#" 之前的后缀进行对应,我们需要一个接着一个的处理。更重要的是,每次插入需要 O(1) 时间,活动点准确地告诉了我们改如何进行,并且也仅需在活动点中增加一个单独的字符。为什么?因为其他字符都隐式地被包含了,要不也就不需要 active point 了。
- 每次插入之后,remainder 都需要减少,如果存在后缀连接(Suffix Link)的话就续接至下一个节点,如果不存在则返回值 root 节点(Rule 3)。如果已经是在 root 节点了,则依据 Rule 1 来修改活动点。无论哪种情况,仅需 O(1) 时间。
- 如果这些插入操作中,如果发现要被插入的字符已经存在于树中,则什么也不做,即使 remainder > 0。原因是要被插入的字符实际上已经隐式地被包含在了当前的树中。而 remainder > 0 则确保了在后续的操作中会进行处理。
- 那么如果在算法结束时 remainder > 0 该怎么办?这种情况说明了文本的尾部字符串在之前某处已经出现过。此时我们需要在尾部添加一个额外的从未出现过的字符,通常使用 "$" 符号。为什么要这么做呢?如果后续我们用已经完成的后缀树来查找后缀,匹配结果一定要出现在叶子节点,否则就会出现很多假匹配,因为很多字符串已经被隐式地包含在了树中,但实际并不是真正的后缀。同时,最后也强制 remainder = 0,以此来保证所有的后缀都形成了叶子节点。尽管如此,如果想用后缀树搜索常规的子字符串,而不仅是搜索后缀,这么做就不是必要的了。
- 那么整个算法的复杂度是多少呢?如果 Text 的长度为 n,则有 n 步需要执行,算上 "$" 则有 n+1 步。在每一步中,我们要么什么也不做,要么执行 remainder 插入操作并消耗 O(1) 时间。因为 remainder 指示了在前一步中我们有多少无操作次数,在当前步骤中每次插入都会递减,所以总体的数量还是 n。因此总体的复杂度为 O(n)。
- 然而,还有一小件事我还没有进行适当的解释。那就是,当我们续接后缀连接时,更新 active point,会发现 active_length 可能与 active_node 协作的并不好。例如下面这种情况:
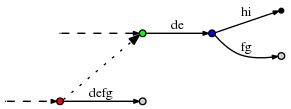
假设 active point 是红色节点 (red, 'd', 3),因此它指向 "def" 边中 "f" 之后的位置。现在假设我们做了必要的更新,而且依据 Rule 3 续接了后缀连接并修改了活动点,新的 active point 是 (green, 'd', 3)。然而从绿色节点出发的 "d" 边是 "de",这条边只有 2 个字符。为了找到合适的活动点,看起来我们需要添加一个到蓝色节点的边,然后重置活动点为 (blue, 'f', 1)。
在最坏的情况下,active_length 可以与 remainder 一样大,甚至可以与 n 一样大。而恰巧这种情况可能刚好在找活动点时发生,那么我们不仅需要跳过一个内部节点,可能是多个节点,最坏的情况是 n 个。由于每步里 remainder 是 O(n),续接了后缀连接之后的对活动点的后续调整也是 O(n),那么是否意味着整个算法潜在需要 O(n2) 时间呢?
我认为不是。理由是如果我们确实需要调整活动点(例如,上图中从绿色节点调整到蓝色节点),那么这就引入了一个拥有自己的后缀连接的新节点,而且 active_length 将减少。当我们沿着后缀连接向下走,就要插入剩余的后缀,且只是减少 active_length,使用这种方法可调整的活动点的数量不可能超过任何给定时刻的 active_length。由于 active_length 从来不会超过 remainder,而 remainder 不仅在每个单一步骤里是 O(n),而且对整个处理过程进行的 remainder 递增的总数也是 O(n),因此调整活动点的数目也就限制在了 O(n)。
代码示例
下面代码来自 GitHub 作者 Nathan Ridley。
1 using System; 2 using System.Collections.Generic; 3 using System.IO; 4 using System.Linq; 5 using System.Text; 6 7 namespace SuffixTreeAlgorithm 8 { 9 class Program 10 { 11 static void Main(string[] args) 12 { 13 var tree = new SuffixTree("abcabxabcd"); 14 tree.Message += (f, o) => { Console.WriteLine(f, o); }; 15 tree.Changed += (t) => 16 { 17 Console.WriteLine( 18 Environment.NewLine 19 + t.RenderTree() 20 + Environment.NewLine); 21 }; 22 tree.Build('$'); 23 24 //SuffixTree.Create("abcabxabcd"); 25 //SuffixTree.Create("abcdefabxybcdmnabcdex"); 26 //SuffixTree.Create("abcadak"); 27 //SuffixTree.Create("dedododeeodo"); 28 //SuffixTree.Create("ooooooooo"); 29 //SuffixTree.Create("mississippi"); 30 31 Console.ReadKey(); 32 } 33 } 34 35 public class SuffixTree 36 { 37 public char? CanonizationChar { get; set; } 38 public string Word { get; private set; } 39 private int CurrentSuffixStartIndex { get; set; } 40 private int CurrentSuffixEndIndex { get; set; } 41 private Node LastCreatedNodeInCurrentIteration { get; set; } 42 private int UnresolvedSuffixes { get; set; } 43 public Node RootNode { get; private set; } 44 private Node ActiveNode { get; set; } 45 private Edge ActiveEdge { get; set; } 46 private int DistanceIntoActiveEdge { get; set; } 47 private char LastCharacterOfCurrentSuffix { get; set; } 48 private int NextNodeNumber { get; set; } 49 private int NextEdgeNumber { get; set; } 50 51 public SuffixTree(string word) 52 { 53 Word = word; 54 RootNode = new Node(this); 55 ActiveNode = RootNode; 56 } 57 58 public event ActionChanged; 59 private void TriggerChanged() 60 { 61 var handler = Changed; 62 if (handler != null) 63 handler(this); 64 } 65 66 public event Action<string, object[]> Message; 67 private void SendMessage(string format, params object[] args) 68 { 69 var handler = Message; 70 if (handler != null) 71 handler(format, args); 72 } 73 74 public static SuffixTree Create(string word, char canonizationChar = '$') 75 { 76 var tree = new SuffixTree(word); 77 tree.Build(canonizationChar); 78 return tree; 79 } 80 81 public void Build(char canonizationChar) 82 { 83 var n = Word.IndexOf(Word[Word.Length - 1]); 84 var mustCanonize = n < Word.Length - 1; 85 if (mustCanonize) 86 { 87 CanonizationChar = canonizationChar; 88 Word = string.Concat(Word, canonizationChar); 89 } 90 91 for (CurrentSuffixEndIndex = 0; CurrentSuffixEndIndex < Word.Length; CurrentSuffixEndIndex++) 92 { 93 SendMessage("=== ITERATION {0} ===", CurrentSuffixEndIndex); 94 LastCreatedNodeInCurrentIteration = null; 95 LastCharacterOfCurrentSuffix = Word[CurrentSuffixEndIndex]; 96 97 for (CurrentSuffixStartIndex = CurrentSuffixEndIndex - UnresolvedSuffixes; CurrentSuffixStartIndex <= CurrentSuffixEndIndex; CurrentSuffixStartIndex++) 98 { 99 var wasImplicitlyAdded = !AddNextSuffix(); 100 if (wasImplicitlyAdded) 101 { 102 UnresolvedSuffixes++; 103 break; 104 } 105 if (UnresolvedSuffixes > 0) 106 UnresolvedSuffixes--; 107 } 108 } 109 } 110 111 private bool AddNextSuffix() 112 { 113 var suffix = string.Concat(Word.Substring(CurrentSuffixStartIndex, CurrentSuffixEndIndex - CurrentSuffixStartIndex), "{", Word[CurrentSuffixEndIndex], "}"); 114 SendMessage("The next suffix of '{0}' to add is '{1}' at indices {2},{3}", Word, suffix, CurrentSuffixStartIndex, CurrentSuffixEndIndex); 115 SendMessage(" => ActiveNode: {0}", ActiveNode); 116 SendMessage(" => ActiveEdge: {0}", ActiveEdge == null ? "none" : ActiveEdge.ToString()); 117 SendMessage(" => DistanceIntoActiveEdge: {0}", DistanceIntoActiveEdge); 118 SendMessage(" => UnresolvedSuffixes: {0}", UnresolvedSuffixes); 119 if (ActiveEdge != null && DistanceIntoActiveEdge >= ActiveEdge.Length) 120 throw new Exception("BOUNDARY EXCEEDED"); 121 122 if (ActiveEdge != null) 123 return AddCurrentSuffixToActiveEdge(); 124 125 if (GetExistingEdgeAndSetAsActive()) 126 return false; 127 128 ActiveNode.AddNewEdge(); 129 TriggerChanged(); 130 131 UpdateActivePointAfterAddingNewEdge(); 132 return true; 133 } 134 135 private bool GetExistingEdgeAndSetAsActive() 136 { 137 Edge edge; 138 if (ActiveNode.Edges.TryGetValue(LastCharacterOfCurrentSuffix, out edge)) 139 { 140 SendMessage("Existing edge for {0} starting with '{1}' found. Values adjusted to:", ActiveNode, LastCharacterOfCurrentSuffix); 141 ActiveEdge = edge; 142 DistanceIntoActiveEdge = 1; 143 TriggerChanged(); 144 145 NormalizeActivePointIfNowAtOrBeyondEdgeBoundary(ActiveEdge.StartIndex); 146 SendMessage(" => ActiveEdge is now: {0}", ActiveEdge); 147 SendMessage(" => DistanceIntoActiveEdge is now: {0}", DistanceIntoActiveEdge); 148 SendMessage(" => UnresolvedSuffixes is now: {0}", UnresolvedSuffixes); 149 150 return true; 151 } 152 SendMessage("Existing edge for {0} starting with '{1}' not found", ActiveNode, LastCharacterOfCurrentSuffix); 153 return false; 154 } 155 156 private bool AddCurrentSuffixToActiveEdge() 157 { 158 var nextCharacterOnEdge = Word[ActiveEdge.StartIndex + DistanceIntoActiveEdge]; 159 if (nextCharacterOnEdge == LastCharacterOfCurrentSuffix) 160 { 161 SendMessage("The next character on the current edge is '{0}' (suffix added implicitly)", LastCharacterOfCurrentSuffix); 162 DistanceIntoActiveEdge++; 163 TriggerChanged(); 164 165 SendMessage(" => DistanceIntoActiveEdge is now: {0}", DistanceIntoActiveEdge); 166 NormalizeActivePointIfNowAtOrBeyondEdgeBoundary(ActiveEdge.StartIndex); 167 168 return false; 169 } 170 171 SplitActiveEdge(); 172 ActiveEdge.Tail.AddNewEdge(); 173 TriggerChanged(); 174 175 UpdateActivePointAfterAddingNewEdge(); 176 177 return true; 178 } 179 180 private void UpdateActivePointAfterAddingNewEdge() 181 { 182 if (ReferenceEquals(ActiveNode, RootNode)) 183 { 184 if (DistanceIntoActiveEdge > 0) 185 { 186 SendMessage("New edge has been added and the active node is root. The active edge will now be updated."); 187 DistanceIntoActiveEdge--; 188 SendMessage(" => DistanceIntoActiveEdge decremented to: {0}", DistanceIntoActiveEdge); 189 ActiveEdge = DistanceIntoActiveEdge == 0 ? null : ActiveNode.Edges[Word[CurrentSuffixStartIndex + 1]]; 190 SendMessage(" => ActiveEdge is now: {0}", ActiveEdge); 191 TriggerChanged(); 192 193 NormalizeActivePointIfNowAtOrBeyondEdgeBoundary(CurrentSuffixStartIndex + 1); 194 } 195 } 196 else 197 UpdateActivePointToLinkedNodeOrRoot(); 198 } 199 200 private void NormalizeActivePointIfNowAtOrBeyondEdgeBoundary(int firstIndexOfOriginalActiveEdge) 201 { 202 var walkDistance = 0; 203 while (ActiveEdge != null && DistanceIntoActiveEdge >= ActiveEdge.Length) 204 { 205 SendMessage("Active point is at or beyond edge boundary and will be moved until it falls inside an edge boundary"); 206 DistanceIntoActiveEdge -= ActiveEdge.Length; 207 ActiveNode = ActiveEdge.Tail ?? RootNode; 208 if (DistanceIntoActiveEdge == 0) 209 ActiveEdge = null; 210 else 211 { 212 walkDistance += ActiveEdge.Length; 213 var c = Word[firstIndexOfOriginalActiveEdge + walkDistance]; 214 ActiveEdge = ActiveNode.Edges[c]; 215 } 216 TriggerChanged(); 217 } 218 } 219 220 private void SplitActiveEdge() 221 { 222 ActiveEdge = ActiveEdge.SplitAtIndex(ActiveEdge.StartIndex + DistanceIntoActiveEdge); 223 SendMessage(" => ActiveEdge is now: {0}", ActiveEdge); 224 TriggerChanged(); 225 if (LastCreatedNodeInCurrentIteration != null) 226 { 227 LastCreatedNodeInCurrentIteration.LinkedNode = ActiveEdge.Tail; 228 SendMessage(" => Connected {0} to {1}", LastCreatedNodeInCurrentIteration, ActiveEdge.Tail); 229 TriggerChanged(); 230 } 231 LastCreatedNodeInCurrentIteration = ActiveEdge.Tail; 232 } 233 234 private void UpdateActivePointToLinkedNodeOrRoot() 235 { 236 SendMessage("The linked node for active node {0} is {1}", ActiveNode, ActiveNode.LinkedNode == null ? "[null]" : ActiveNode.LinkedNode.ToString()); 237 if (ActiveNode.LinkedNode != null) 238 { 239 ActiveNode = ActiveNode.LinkedNode; 240 SendMessage(" => ActiveNode is now: {0}", ActiveNode); 241 } 242 else 243 { 244 ActiveNode = RootNode; 245 SendMessage(" => ActiveNode is now ROOT", ActiveNode); 246 } 247 TriggerChanged(); 248 249 if (ActiveEdge != null) 250 { 251 var firstIndexOfOriginalActiveEdge = ActiveEdge.StartIndex; 252 ActiveEdge = ActiveNode.Edges[Word[ActiveEdge.StartIndex]]; 253 TriggerChanged(); 254 NormalizeActivePointIfNowAtOrBeyondEdgeBoundary(firstIndexOfOriginalActiveEdge); 255 } 256 } 257 258 public string RenderTree() 259 { 260 var writer = new StringWriter(); 261 RootNode.RenderTree(writer, ""); 262 return writer.ToString(); 263 } 264 265 public string WriteDotGraph() 266 { 267 var sb = new StringBuilder(); 268 sb.AppendLine("digraph {"); 269 sb.AppendLine("rankdir = LR;"); 270 sb.AppendLine("edge [arrowsize=0.5,fontsize=11];"); 271 for (var i = 0; i < NextNodeNumber; i++) 272 sb.AppendFormat("node{0} [label=\"{0}\",style=filled,fillcolor={1},shape=circle,width=.1,height=.1,fontsize=11,margin=0.01];", 273 i, ActiveNode.NodeNumber == i ? "cyan" : "lightgrey").AppendLine(); 274 RootNode.WriteDotGraph(sb); 275 sb.AppendLine("}"); 276 return sb.ToString(); 277 } 278 279 public HashSet<string> ExtractAllSubstrings() 280 { 281 var set = new HashSet<string>(); 282 ExtractAllSubstrings("", set, RootNode); 283 return set; 284 } 285 286 private void ExtractAllSubstrings(string str, HashSet<string> set, Node node) 287 { 288 foreach (var edge in node.Edges.Values) 289 { 290 var edgeStr = edge.StringWithoutCanonizationChar; 291 var edgeLength = !edge.EndIndex.HasValue && CanonizationChar.HasValue ? edge.Length - 1 : edge.Length; // assume tailing canonization char 292 for (var length = 1; length <= edgeLength; length++) 293 set.Add(string.Concat(str, edgeStr.Substring(0, length))); 294 if (edge.Tail != null) 295 ExtractAllSubstrings(string.Concat(str, edge.StringWithoutCanonizationChar), set, edge.Tail); 296 } 297 } 298 299 public List<string> ExtractSubstringsForIndexing(int? maxLength = null) 300 { 301 var list = new List<string>(); 302 ExtractSubstringsForIndexing("", list, maxLength ?? Word.Length, RootNode); 303 return list; 304 } 305 306 private void ExtractSubstringsForIndexing(string str, List<string> list, int len, Node node) 307 { 308 foreach (var edge in node.Edges.Values) 309 { 310 var newstr = string.Concat(str, Word.Substring(edge.StartIndex, Math.Min(len, edge.Length))); 311 if (len > edge.Length && edge.Tail != null) 312 ExtractSubstringsForIndexing(newstr, list, len - edge.Length, edge.Tail); 313 else 314 list.Add(newstr); 315 } 316 } 317 318 public class Edge 319 { 320 private readonly SuffixTree _tree; 321 322 public Edge(SuffixTree tree, Node head) 323 { 324 _tree = tree; 325 Head = head; 326 StartIndex = tree.CurrentSuffixEndIndex; 327 EdgeNumber = _tree.NextEdgeNumber++; 328 } 329 330 public Node Head { get; private set; } 331 public Node Tail { get; private set; } 332 public int StartIndex { get; private set; } 333 public int? EndIndex { get; set; } 334 public int EdgeNumber { get; private set; } 335 public int Length { get { return (EndIndex ?? _tree.Word.Length - 1) - StartIndex + 1; } } 336 337 public Edge SplitAtIndex(int index) 338 { 339 _tree.SendMessage("Splitting edge {0} at index {1} ('{2}')", this, index, _tree.Word[index]); 340 var newEdge = new Edge(_tree, Head); 341 var newNode = new Node(_tree); 342 newEdge.Tail = newNode; 343 newEdge.StartIndex = StartIndex; 344 newEdge.EndIndex = index - 1; 345 Head = newNode; 346 StartIndex = index; 347 newNode.Edges.Add(_tree.Word[StartIndex], this); 348 newEdge.Head.Edges[_tree.Word[newEdge.StartIndex]] = newEdge; 349 _tree.SendMessage(" => Hierarchy is now: {0} --> {1} --> {2} --> {3}", newEdge.Head, newEdge, newNode, this); 350 return newEdge; 351 } 352 353 public override string ToString() 354 { 355 return string.Concat(_tree.Word.Substring(StartIndex, (EndIndex ?? _tree.CurrentSuffixEndIndex) - StartIndex + 1), "(", 356 StartIndex, ",", EndIndex.HasValue ? EndIndex.ToString() : "#", ")"); 357 } 358 359 public string StringWithoutCanonizationChar 360 { 361 get { return _tree.Word.Substring(StartIndex, (EndIndex ?? _tree.CurrentSuffixEndIndex - (_tree.CanonizationChar.HasValue ? 1 : 0)) - StartIndex + 1); } 362 } 363 364 public string String 365 { 366 get { return _tree.Word.Substring(StartIndex, (EndIndex ?? _tree.CurrentSuffixEndIndex) - StartIndex + 1); } 367 } 368 369 public void RenderTree(TextWriter writer, string prefix, int maxEdgeLength) 370 { 371 var strEdge = _tree.Word.Substring(StartIndex, (EndIndex ?? _tree.CurrentSuffixEndIndex) - StartIndex + 1); 372 writer.Write(strEdge); 373 if (Tail == null) 374 writer.WriteLine(); 375 else 376 { 377 var line = new string(RenderChars.HorizontalLine, maxEdgeLength - strEdge.Length + 1); 378 writer.Write(line); 379 Tail.RenderTree(writer, string.Concat(prefix, new string(' ', strEdge.Length + line.Length))); 380 } 381 } 382 383 public void WriteDotGraph(StringBuilder sb) 384 { 385 if (Tail == null) 386 sb.AppendFormat("leaf{0} [label=\"\",shape=point]", EdgeNumber).AppendLine(); 387 string label, weight, color; 388 if (_tree.ActiveEdge != null && ReferenceEquals(this, _tree.ActiveEdge)) 389 { 390 if (_tree.ActiveEdge.Length == 0) 391 label = ""; 392 else if (_tree.DistanceIntoActiveEdge > Length) 393 label = "<" + String + " (" + _tree.DistanceIntoActiveEdge + ")>"; 394 else if (_tree.DistanceIntoActiveEdge == Length) 395 label = "<" + String + ">"; 396 else if (_tree.DistanceIntoActiveEdge > 0) 397 label = "< >"; 398 else 399 label = "\"" + String + "\""; 400 color = "blue"; 401 weight = "5"; 402 } 403 else 404 { 405 label = "\"" + String + "\""; 406 color = "black"; 407 weight = "3"; 408 } 409 var tail = Tail == null ? "leaf" + EdgeNumber : "node" + Tail.NodeNumber; 410 sb.AppendFormat("node{0} -> {1} [label={2},weight={3},color={4},size=11]", Head.NodeNumber, tail, label, weight, color).AppendLine(); 411 if (Tail != null) 412 Tail.WriteDotGraph(sb); 413 } 414 } 415 416 public class Node 417 { 418 private readonly SuffixTree _tree; 419 420 public Node(SuffixTree tree) 421 { 422 _tree = tree; 423 Edges = new Dictionary<char, Edge>(); 424 NodeNumber = _tree.NextNodeNumber++; 425 } 426 427 public Dictionary<char, Edge> Edges { get; private set; } 428 public Node LinkedNode { get; set; } 429 public int NodeNumber { get; private set; } 430 431 public void AddNewEdge() 432 { 433 _tree.SendMessage("Adding new edge to {0}", this); 434 var edge = new Edge(_tree, this); 435 Edges.Add(_tree.Word[_tree.CurrentSuffixEndIndex], edge); 436 _tree.SendMessage(" => {0} --> {1}", this, edge); 437 } 438 439 public void RenderTree(TextWriter writer, string prefix) 440 { 441 var strNode = string.Concat("(", NodeNumber.ToString(new string('0', _tree.NextNodeNumber.ToString().Length)), ")"); 442 writer.Write(strNode); 443 var edges = Edges.Select(kvp => kvp.Value).OrderBy(e => _tree.Word[e.StartIndex]).ToArray(); 444 if (edges.Any()) 445 { 446 var prefixWithNodePadding = prefix + new string(' ', strNode.Length); 447 var maxEdgeLength = edges.Max(e => (e.EndIndex ?? _tree.CurrentSuffixEndIndex) - e.StartIndex + 1); 448 for (var i = 0; i < edges.Length; i++) 449 { 450 char connector, extender = ' '; 451 if (i == 0) 452 { 453 if (edges.Length > 1) 454 { 455 connector = RenderChars.TJunctionDown; 456 extender = RenderChars.VerticalLine; 457 } 458 else 459 connector = RenderChars.HorizontalLine; 460 } 461 else 462 { 463 writer.Write(prefixWithNodePadding); 464 if (i == edges.Length - 1) 465 connector = RenderChars.CornerRight; 466 else 467 { 468 connector = RenderChars.TJunctionRight; 469 extender = RenderChars.VerticalLine; 470 } 471 } 472 writer.Write(string.Concat(connector, RenderChars.HorizontalLine)); 473 var newPrefix = string.Concat(prefixWithNodePadding, extender, ' '); 474 edges[i].RenderTree(writer, newPrefix, maxEdgeLength); 475 } 476 } 477 } 478 479 public override string ToString() 480 { 481 return string.Concat("node #", NodeNumber); 482 } 483 484 public void WriteDotGraph(StringBuilder sb) 485 { 486 if (LinkedNode != null) 487 sb.AppendFormat("node{0} -> node{1} [label=\"\",weight=.01,style=dotted]", NodeNumber, LinkedNode.NodeNumber).AppendLine(); 488 foreach (var edge in Edges.Values) 489 edge.WriteDotGraph(sb); 490 } 491 } 492 493 public static class RenderChars 494 { 495 public const char TJunctionDown = '┬'; 496 public const char HorizontalLine = '─'; 497 public const char VerticalLine = '│'; 498 public const char TJunctionRight = '├'; 499 public const char CornerRight = '└'; 500 } 501 } 502 }
" + String.Substring(0, _tree.DistanceIntoActiveEdge) + " " + String.Substring(_tree.DistanceIntoActiveEdge) + "
运行结果
测试 Text = "abcabxabcd"。
=== ITERATION 0 === The next suffix of 'abcabxabcd' to add is '{a}' at indices 0,0 => ActiveNode: node #0 => ActiveEdge: none => DistanceIntoActiveEdge: 0 => UnresolvedSuffixes: 0 Existing edge for node #0 starting with 'a' not found Adding new edge to node #0 => node #0 --> a(0,#) (0)──a === ITERATION 1 === The next suffix of 'abcabxabcd' to add is '{b}' at indices 1,1 => ActiveNode: node #0 => ActiveEdge: none => DistanceIntoActiveEdge: 0 => UnresolvedSuffixes: 0 Existing edge for node #0 starting with 'b' not found Adding new edge to node #0 => node #0 --> b(1,#) (0)┬─ab └─b === ITERATION 2 === The next suffix of 'abcabxabcd' to add is '{c}' at indices 2,2 => ActiveNode: node #0 => ActiveEdge: none => DistanceIntoActiveEdge: 0 => UnresolvedSuffixes: 0 Existing edge for node #0 starting with 'c' not found Adding new edge to node #0 => node #0 --> c(2,#) (0)┬─abc ├─bc └─c === ITERATION 3 === The next suffix of 'abcabxabcd' to add is '{a}' at indices 3,3 => ActiveNode: node #0 => ActiveEdge: none => DistanceIntoActiveEdge: 0 => UnresolvedSuffixes: 0 Existing edge for node #0 starting with 'a' found. Values adjusted to: (0)┬─abca ├─bca └─ca => ActiveEdge is now: abca(0,#) => DistanceIntoActiveEdge is now: 1 => UnresolvedSuffixes is now: 0 === ITERATION 4 === The next suffix of 'abcabxabcd' to add is 'a{b}' at indices 3,4 => ActiveNode: node #0 => ActiveEdge: abcab(0,#) => DistanceIntoActiveEdge: 1 => UnresolvedSuffixes: 1 The next character on the current edge is 'b' (suffix added implicitly) (0)┬─abcab ├─bcab └─cab => DistanceIntoActiveEdge is now: 2 === ITERATION 5 === The next suffix of 'abcabxabcd' to add is 'ab{x}' at indices 3,5 => ActiveNode: node #0 => ActiveEdge: abcabx(0,#) => DistanceIntoActiveEdge: 2 => UnresolvedSuffixes: 2 Splitting edge abcabx(0,#) at index 2 ('c') => Hierarchy is now: node #0 --> ab(0,1) --> node #1 --> cabx(2,#) => ActiveEdge is now: ab(0,1) (0)┬─ab────(1)──cabx ├─bcabx └─cabx Adding new edge to node #1 => node #1 --> x(5,#) (0)┬─ab────(1)┬─cabx │ └─x ├─bcabx └─cabx New edge has been added and the active node is root. The active edge will now be updated. => DistanceIntoActiveEdge decremented to: 1 => ActiveEdge is now: bcabx(1,#) (0)┬─ab────(1)┬─cabx │ └─x ├─bcabx └─cabx The next suffix of 'abcabxabcd' to add is 'b{x}' at indices 4,5 => ActiveNode: node #0 => ActiveEdge: bcabx(1,#) => DistanceIntoActiveEdge: 1 => UnresolvedSuffixes: 1 Splitting edge bcabx(1,#) at index 2 ('c') => Hierarchy is now: node #0 --> b(1,1) --> node #2 --> cabx(2,#) => ActiveEdge is now: b(1,1) (0)┬─ab───(1)┬─cabx │ └─x ├─b────(2)──cabx └─cabx => Connected node #1 to node #2 (0)┬─ab───(1)┬─cabx │ └─x ├─b────(2)──cabx └─cabx Adding new edge to node #2 => node #2 --> x(5,#) (0)┬─ab───(1)┬─cabx │ └─x ├─b────(2)┬─cabx │ └─x └─cabx New edge has been added and the active node is root. The active edge will now be updated. => DistanceIntoActiveEdge decremented to: 0 => ActiveEdge is now: (0)┬─ab───(1)┬─cabx │ └─x ├─b────(2)┬─cabx │ └─x └─cabx The next suffix of 'abcabxabcd' to add is '{x}' at indices 5,5 => ActiveNode: node #0 => ActiveEdge: none => DistanceIntoActiveEdge: 0 => UnresolvedSuffixes: 0 Existing edge for node #0 starting with 'x' not found Adding new edge to node #0 => node #0 --> x(5,#) (0)┬─ab───(1)┬─cabx │ └─x ├─b────(2)┬─cabx │ └─x ├─cabx └─x === ITERATION 6 === The next suffix of 'abcabxabcd' to add is '{a}' at indices 6,6 => ActiveNode: node #0 => ActiveEdge: none => DistanceIntoActiveEdge: 0 => UnresolvedSuffixes: 0 Existing edge for node #0 starting with 'a' found. Values adjusted to: (0)┬─ab────(1)┬─cabxa │ └─xa ├─b─────(2)┬─cabxa │ └─xa ├─cabxa └─xa => ActiveEdge is now: ab(0,1) => DistanceIntoActiveEdge is now: 1 => UnresolvedSuffixes is now: 0 === ITERATION 7 === The next suffix of 'abcabxabcd' to add is 'a{b}' at indices 6,7 => ActiveNode: node #0 => ActiveEdge: ab(0,1) => DistanceIntoActiveEdge: 1 => UnresolvedSuffixes: 1 The next character on the current edge is 'b' (suffix added implicitly) (0)┬─ab─────(1)┬─cabxab │ └─xab ├─b──────(2)┬─cabxab │ └─xab ├─cabxab └─xab => DistanceIntoActiveEdge is now: 2 Active point is at or beyond edge boundary and will be moved until it falls insi de an edge boundary (0)┬─ab─────(1)┬─cabxab │ └─xab ├─b──────(2)┬─cabxab │ └─xab ├─cabxab └─xab === ITERATION 8 === The next suffix of 'abcabxabcd' to add is 'ab{c}' at indices 6,8 => ActiveNode: node #1 => ActiveEdge: none => DistanceIntoActiveEdge: 0 => UnresolvedSuffixes: 2 Existing edge for node #1 starting with 'c' found. Values adjusted to: (0)┬─ab──────(1)┬─cabxabc │ └─xabc ├─b───────(2)┬─cabxabc │ └─xabc ├─cabxabc └─xabc => ActiveEdge is now: cabxabc(2,#) => DistanceIntoActiveEdge is now: 1 => UnresolvedSuffixes is now: 2 === ITERATION 9 === The next suffix of 'abcabxabcd' to add is 'abc{d}' at indices 6,9 => ActiveNode: node #1 => ActiveEdge: cabxabcd(2,#) => DistanceIntoActiveEdge: 1 => UnresolvedSuffixes: 3 Splitting edge cabxabcd(2,#) at index 3 ('a') => Hierarchy is now: node #1 --> c(2,2) --> node #3 --> abxabcd(3,#) => ActiveEdge is now: c(2,2) (0)┬─ab───────(1)┬─c─────(3)──abxabcd │ └─xabcd ├─b────────(2)┬─cabxabcd │ └─xabcd ├─cabxabcd └─xabcd Adding new edge to node #3 => node #3 --> d(9,#) (0)┬─ab───────(1)┬─c─────(3)┬─abxabcd │ │ └─d │ └─xabcd ├─b────────(2)┬─cabxabcd │ └─xabcd ├─cabxabcd └─xabcd The linked node for active node node #1 is node #2 => ActiveNode is now: node #2 (0)┬─ab───────(1)┬─c─────(3)┬─abxabcd │ │ └─d │ └─xabcd ├─b────────(2)┬─cabxabcd │ └─xabcd ├─cabxabcd └─xabcd (0)┬─ab───────(1)┬─c─────(3)┬─abxabcd │ │ └─d │ └─xabcd ├─b────────(2)┬─cabxabcd │ └─xabcd ├─cabxabcd └─xabcd The next suffix of 'abcabxabcd' to add is 'bc{d}' at indices 7,9 => ActiveNode: node #2 => ActiveEdge: cabxabcd(2,#) => DistanceIntoActiveEdge: 1 => UnresolvedSuffixes: 2 Splitting edge cabxabcd(2,#) at index 3 ('a') => Hierarchy is now: node #2 --> c(2,2) --> node #4 --> abxabcd(3,#) => ActiveEdge is now: c(2,2) (0)┬─ab───────(1)┬─c─────(3)┬─abxabcd │ │ └─d │ └─xabcd ├─b────────(2)┬─c─────(4)──abxabcd │ └─xabcd ├─cabxabcd └─xabcd => Connected node #3 to node #4 (0)┬─ab───────(1)┬─c─────(3)┬─abxabcd │ │ └─d │ └─xabcd ├─b────────(2)┬─c─────(4)──abxabcd │ └─xabcd ├─cabxabcd └─xabcd Adding new edge to node #4 => node #4 --> d(9,#) (0)┬─ab───────(1)┬─c─────(3)┬─abxabcd │ │ └─d │ └─xabcd ├─b────────(2)┬─c─────(4)┬─abxabcd │ │ └─d │ └─xabcd ├─cabxabcd └─xabcd The linked node for active node node #2 is [null] => ActiveNode is now ROOT (0)┬─ab───────(1)┬─c─────(3)┬─abxabcd │ │ └─d │ └─xabcd ├─b────────(2)┬─c─────(4)┬─abxabcd │ │ └─d │ └─xabcd ├─cabxabcd └─xabcd (0)┬─ab───────(1)┬─c─────(3)┬─abxabcd │ │ └─d │ └─xabcd ├─b────────(2)┬─c─────(4)┬─abxabcd │ │ └─d │ └─xabcd ├─cabxabcd └─xabcd The next suffix of 'abcabxabcd' to add is 'c{d}' at indices 8,9 => ActiveNode: node #0 => ActiveEdge: cabxabcd(2,#) => DistanceIntoActiveEdge: 1 => UnresolvedSuffixes: 1 Splitting edge cabxabcd(2,#) at index 3 ('a') => Hierarchy is now: node #0 --> c(2,2) --> node #5 --> abxabcd(3,#) => ActiveEdge is now: c(2,2) (0)┬─ab────(1)┬─c─────(3)┬─abxabcd │ │ └─d │ └─xabcd ├─b─────(2)┬─c─────(4)┬─abxabcd │ │ └─d │ └─xabcd ├─c─────(5)──abxabcd └─xabcd => Connected node #4 to node #5 (0)┬─ab────(1)┬─c─────(3)┬─abxabcd │ │ └─d │ └─xabcd ├─b─────(2)┬─c─────(4)┬─abxabcd │ │ └─d │ └─xabcd ├─c─────(5)──abxabcd └─xabcd Adding new edge to node #5 => node #5 --> d(9,#) (0)┬─ab────(1)┬─c─────(3)┬─abxabcd │ │ └─d │ └─xabcd ├─b─────(2)┬─c─────(4)┬─abxabcd │ │ └─d │ └─xabcd ├─c─────(5)┬─abxabcd │ └─d └─xabcd New edge has been added and the active node is root. The active edge will now be updated. => DistanceIntoActiveEdge decremented to: 0 => ActiveEdge is now: (0)┬─ab────(1)┬─c─────(3)┬─abxabcd │ │ └─d │ └─xabcd ├─b─────(2)┬─c─────(4)┬─abxabcd │ │ └─d │ └─xabcd ├─c─────(5)┬─abxabcd │ └─d └─xabcd The next suffix of 'abcabxabcd' to add is '{d}' at indices 9,9 => ActiveNode: node #0 => ActiveEdge: none => DistanceIntoActiveEdge: 0 => UnresolvedSuffixes: 0 Existing edge for node #0 starting with 'd' not found Adding new edge to node #0 => node #0 --> d(9,#) (0)┬─ab────(1)┬─c─────(3)┬─abxabcd │ │ └─d │ └─xabcd ├─b─────(2)┬─c─────(4)┬─abxabcd │ │ └─d │ └─xabcd ├─c─────(5)┬─abxabcd │ └─d ├─d └─xabcd
后缀树的应用
- 查找字符串 Pattern 是否在于字符串 Text 中
- 方案:用 Text 构造后缀树,按在 Trie 中搜索字串的方法搜索 Pattern 即可。若 Pattern 在 Text 中,则 Pattern 必然是 Text 的某个后缀的前缀。
- 计算指定字符串 Pattern 在字符串 Text 中的出现次数
- 方案:用 Text+'$' 构造后缀树,搜索 Pattern 所在节点下的叶节点数目即为重复次数。如果 Pattern 在 Text 中重复了 c 次,则 Text 应有 c 个后缀以 Pattern 为前缀。
- 查找字符串 Text 中的最长重复子串
- 方案:用 Text+'$' 构造后缀树,搜索 Pattern 所在节点下的最深的非叶节点。从 root 到该节点所经历过的字符串就是最长重复子串。
- 查找两个字符串 Text1 和 Text2 的最长公共部分
- 方案:连接 Text1+'#' + Text2+'$' 形成新的字符串并构造后缀树,找到最深的非叶节点,且该节点的叶节点既有 '#' 也有 '$'。
- 查找给定字符串 Text 里的最长回文
- 回文指:"abcdefgfed" 中对称的字符串 "defgfed"。
- 回文半径指:回文 "defgfed" 的回文半径 "defg" 长度为 4,半径中心为字母 "g"。
- 方案:将 Text 整体反转形成新的字符串 Text2,例如 "abcdefgfed" => "defgfedcba"。连接 Text+'#' + Text2+'$' 形成新的字符串并构造后缀树,然后将问题转变为查找 Text 和 Text1 的最长公共部分。
参考资料
- Pattern Searching | Set 8 (Suffix Tree Introduction)
- 后缀树的构造方法-Ukkonen详解
- Ukkonen’s Suffix Tree Construction – Part 1
- Suffix Trees
- Compressed Trie
- Pattern Searching using a Trie of all Suffixes
- Algorithms on Strings, Trees, and Sequences
- C# Suffix tree implementation based on Ukkonen's algorithm
- Ukkonen's suffix tree algorithm in plain English?
- Ukkonen 的后缀树算法的清晰解释
- Fast String Searching With Suffix Trees
- Esko Ukkonen's Paper: On–line construction of suffix trees
- Graphviz - Graph Visualization Software
- a suffix tree algorithm for .NET written in C#
本文《后缀树》由 Dennis Gao 发表自博客园,未经作者本人同意禁止任何形式的转载,任何自动或人为的爬虫行为均为耍流氓。
»下一篇: 后缀数组