吴恩达深度学习课程笔记(三): 结构化机器学习项目2
吴恩达深度学习课程笔记(三): 结构化机器学习项目2
- 吴恩达深度学习课程笔记(三): 结构化机器学习项目2
- 第二周 机器学习(ML)策略(2)
- 2.1 进行误差分析
- 2.2 标签错误的数据
- 2.3 快速搭建你的第一个系统,并进行迭代
- 2.4 训练集和开发集、测试集不同分布
- 2.5 训练集和开发/测试集不同数据分布时候的偏差和方差
- 2.6 数据不匹配问题
- 人工数据合成:
- 2.7 迁移学习
- 2.8 多任务学习(并行学习)
- 2.9 什么是端到端的深度学习
- 2.10 是否要使用端到端的深度学习
- 第二周 机器学习(ML)策略(2)
第二周 机器学习(ML)策略(2)
2.1 进行误差分析
一个猫咪分类器,总是将一些狗识别成猫。为此,你想实现一个狗狗分类器,将狗狗识别出来,这可能会花费几个月的时间,真的必须这样做才能解决问题吗?
不是的。
应该先进行误差分析:
- 拿出100个误分类的开发集数据;
- 人工检查其中有多少只是狗。
假设有5只狗狗,也就是说,误分类的数据中有5%是狗,那么,即使解决狗的问题,误差也只能下降0.5%(假设原本误差为10%),即下降到9.5%。这样来看,花费几个月时间折腾狗的问题不值得。
误差分析给出的解决狗的问题的性能上限就是下降0.5%。
但如果有50只狗,那么,解决狗的问题,误差下降5%,从10%下降到5%。花费几个月时间去解决该问题是值得的。
误差分析可以找到提升性能的关键所在,从而节省大量时间。
并行评估多个想法:
- 找一组错误分类的数据(开发集or测试集),统计属于不同错误类型的错误数量 ,在这个过程中,可能会得到启发,归纳出新的误差类型。
总之,通过统计不同错误标记类型占总数的百分比,可以帮助你发现哪些问题需要优先解决。或者给你构思新的优化方向的灵感。

上图中,误差分析的统计结果显示,错误分类的类型中,模糊图片和其他猫科动物占得比重很大。那么,接下来的优化方向就是great cat 和 blurry images。
2.2 标签错误的数据
理想的数据集应该是标签都是正确的。但人工标准的数据总是有一部分数据是带着错误的标签。
训练集:
深度学习算法对训练集的随机误差有相当强的鲁棒性。只要错误标记的数据离随机误差不太远(即,近似随机误差,错误足够随机:标记者没注意、不小心按错键),就可以不用去考虑。
系统误差(一直将白色狗的图片打上猫的标签)对深度学习算法有很大的影响。需要修正。
开发集、测试集:
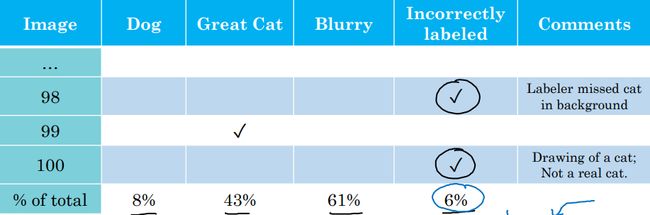
误差分析,分析标签错误占到总错误数的比重。
如果标签错误严重影响在开发集上评估算法的能力,那么就花时间去修正错误的标签。
如果没有严重影响到用开发集评估成本偏差的能力,那么就不处理。比如,在上图中,假设开发集的error=10%,那么由错误标签引起的占到0.6%,而由于其他原因(比如great cat占到4.3%)占到很大比重,那么应该把精力放在其他地方。
当其他误差已经解决掉的时候,比如此时开发集error=2%,那么错误标签在开发集误差中所占的百分比上升到30%,此时,应该集中精力解决标签错误问题。又比如,开发集的作用之一就是比较不同的模型的性能,如果模型A的误差为2.1%,模型B 为1.9%,那么似乎应该选择模型B。但由于开发集存在标签错误,上述误差中的0.6%是标签出错的误差,由于该错误的存在,没办法公正的评估两个模型的好坏,那么应该修正开发集的错误标签。
修正开发集、测试集标签误差的方针和原则:
- 用同样的手段修正开发集和测试集(因为开发集和测试集必须保持同一分布);
- 同时检查算法判断正确和判断错误的样例(标签错误。算法预测结果与标签不符,好判断;算法预测结果与标签相符合,这需要功夫去修正);——由于检查标签错误且算法预测结果与标签一致的工作量太大,所以通常这部分工作无法进行。只修改算法预测结果与标签不符合的数据。
- 训练集可以不修正(近似随机误差,算法具有鲁棒性),所以训练集和开发集、测试集的数据分布允许有轻微的不一致。

在构建深度学习算法的过程中,需要很多的人工误差分析。
有时候,必须花几个小时的时间去手工统计一小批数据,虽然无聊,但是有用。
2.3 快速搭建你的第一个系统,并进行迭代
尽快建立第一个系统原型,并快速迭代。
几乎所用的机器学习程序,可能会有几十个不同的方向可以前进,并且每个方向都是相对合理的,可以改善系统。
那么,如何选择一个方向集中精力处理?
- 快速设置开发集、测试集、指标;
- 快速建立原型系统;
- 用偏差方差分析、误差分析来决定下一步优先做什么;
Build your first system quickly, then iterate! Build your first system quickly, then iterate!
注:本建议不适用于在要做的东西上已经有很多经验的人,以及有大量文献的项目(比如人脸识别,由于可以阅读文献,然后一开始就可以搭建一个比较复杂的系统)。本建议适用于第一次做一个全新领域的机器学习项目的人,这时不应该考虑太多,不应该一开始就搞一个复杂的系统,而应该构建一些快速而“肮脏”的实现,然后一步一步的迭代。
2.4 训练集和开发集、测试集不同分布
算法训练需要大量的数据,要尽量的搜集数据,所以一般情况下训练集和开发集、测试集的数据分布不同。
如何处理训练集和开发集、测试集不同分布的情况?
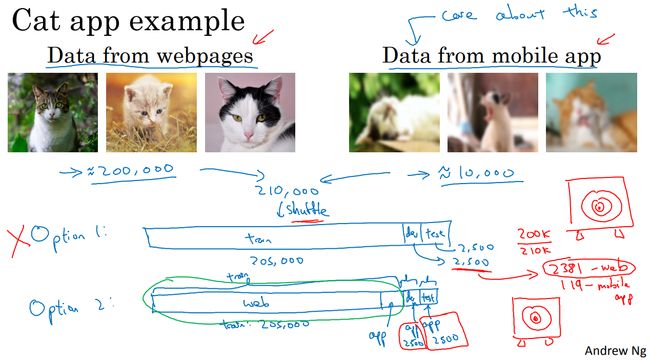
开发集就是算法要瞄准的目标,必须和现实一致。现实是要识别手机用户拍摄的照片,所以开发集和测试集的数据必须来自于手机app的用户数据。而训练集需要大量数据,除了少部分来自App用户的数据,大量图像都是来着网站爬取。训练集和开发集、测试集数据分布不一致。但是一般不会影响模型性能,反而由于其他来源的数据大大扩充了训练集,对模型的训练带来好处。
2.5 训练集和开发/测试集不同数据分布时候的偏差和方差
训练集和开发集、测试集不同分布,导致分析其偏差和方差的方式可能不一样。
对猫分类器:

- 训练集和开发集同分布,那么这是方差大的问题。训练集训练的算法无法很好的泛化到开发集(在训练集上过拟合)。
- 训练集和开发集不同分布,是什么问题?
- 可能在开发集上算法表现也很不错,但是由于图像是模糊图像,而训练集都是高质量图像。所以导致在开发集上误差大。所以很难界定这到底是一个高方差问题,还是说仅仅是开发集包含更难以准确分类的图像。
也就是说,在训练集和开发集不同分布的时候,无法区分是高方差还是由于不同分布导致的误差不同。
- 可能在开发集上算法表现也很不错,但是由于图像是模糊图像,而训练集都是高质量图像。所以导致在开发集上误差大。所以很难界定这到底是一个高方差问题,还是说仅仅是开发集包含更难以准确分类的图像。
训练集和开发集不同分布时,分析偏差、方差的解决办法:加入训练-开发集
- 训练-开发集:和训练集同分布,但不参与训练。
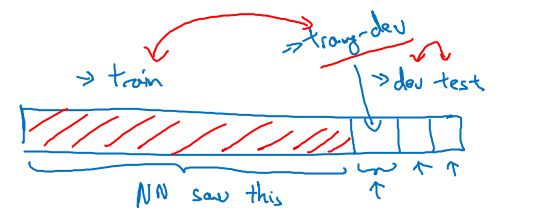
注:训练集和训练-开发集同分布;开发集和测试集同分布。
- 现在假设haman error = 0%
- training error = 1%
training-dev error = 9%
dev error = 10%
显然,存在方差问题。
即算法无法很好的泛化到来自同一分布,但以前没见过的数据中。 - training error = 1%
training-dev error = 1.5%
dev error = 10%
显然,不存在方差问题。
但存在数据不匹配问题(data mismatch problem)。
即算法擅长处理的数据分布和实际要处理的数据分布不一致。 - training error = 10%
training-dev error = 11%
dev error = 12%
存在可避免偏差问题。 - training error = 10%
training-dev error = 11%
dev error = 20%
存在可避免偏差问题、数据不匹配问题。
- training error = 1%
训练-开发集的作用:
- 区分是高方差问题和数据不匹配问题;

从上到下依次为:
- 可避免偏差;
- 方差;
- 数据不匹配程度;
- (算法)在开发集上过拟合程度。
如果在开发集上过拟合,应该去收集更多的开发集数据。
测试集不能用于算法开发过程,仅用于测试算法性能。否则会引入测试集过拟合问题,测试集应该是真实世界数据的代表,不应该被算法过拟合。
如果出现上图右侧情况,开发集、测试集误差小于训练集、训练-开发集误差,有可能是训练集、训练-开发集数据要比开发集、测试集难识别得多。
对这种情况,需要更普适的分析方法:
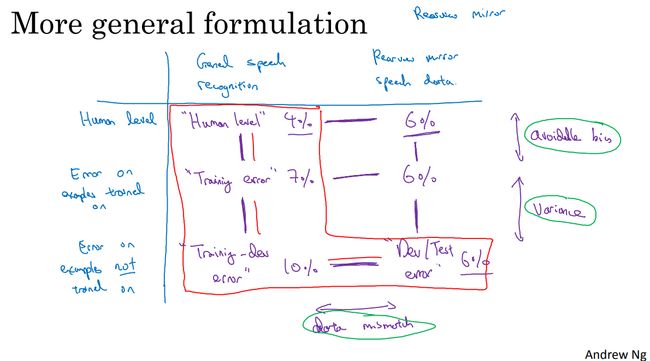
现在假设在开发一款后视镜语音助手。
横列:一般语音识别任务(训练集和训练开发集使用数据)、和后视镜有关的语音数据(开发集、测试集数据);
纵列:人类水平误差、参与训练数据的误差、未参与训练数据的误差。
注:dev/test error 是开发集误差= 6%,同时测试集误差= 6%。一个框内两个数据集的误差。在开发集和测试集之间也存在开发集过拟合程度。
先分析一般语音数据集,这部分数据集的大部分用于训练模型,如图所示,分析完红框内数据集之间的误差差距,发现存在可避免偏差、方差。但开发-测试集误差=10%,开发集误差=6%。不是一般的数据不匹配问题。
这时候,再去后视镜语音数据集的人类水平(发现即使是人类,后视镜语音识别误差也高于一般语音识别误差,说明确实难识别)。
将后视镜语音数据集放入训练集中,喂给同一个算法训练,然后测量该数据子集的误差=6%。也就是说其实已经在后视镜语音识别上算法达到人类水平了。
那么,训练-开发集误差高于开发集、测试集的原因也许就是之前训练的算法已经在后视镜语音识别这一部分做的很不错了。
一般情况下,能用到的就是上图中红色框部分。
2.6 数据不匹配问题
如何处理数据不匹配问题?
没有系解决数据不匹配问题的办法。
解决数据不匹配问题的一些方法:
对数据集做误差分析,了解训练集和开发集的数据分布的差异之处(为了避免对测试集过拟合,误差分析应该只看开发集,不看测试集)。
让训练集的数据分布更像开发/测试集:
- 收集更多类似开发/测试集的真实数据加入训练集;
- 人工数据合成;
人工数据合成:

人工数据合成可能会出现的问题:
现实世界中,后视镜语音数据存在噪声。那么,开发集、测试集数据跟现实世界数据为同一分布。但是收集到的训练集、训练-开发集数据没有噪声。为了让训练集、训练-开发集的数据分布更像开发/测试集,对训练集、训练-开发集进行人工合成数据。
上图中,对10000小时的训练集数据循环加入时长为1小时的汽车噪声。那么神经网络会出现噪声过拟合的问题,虽然人听不出,但是机器可以。这一个小时的噪声仅为整个现实世界噪声数据的一个小小的子集。
- 那么寻找到10000小时不重复的噪声数据和原始数据合成,可能效果就比1小时循环合成的好。
- 也就是说,在这个例子中,人工数据合成的挑战在于,人耳无法分辨10000小时噪声和1小时噪声的区别,所以有可能合成的数据是整个真实世界数据的一个小的多的子集。如上图紫色部分所示。
即,人工数据合成,有可能合成的数据仅为整个真实世界数据的一个很小的子集,但人很难凭自身去发现(肉眼、耳朵等),而算法却对这个合成的小子集过拟合。

针对数据不匹配问题,先进行误差分析,了解训练集和开发集的不同;之后,收集类似于开发集的数据,或者人工数据合成,人工数据合成的时候注意合成数据不能仅为真实世界的一个很小的子集。
2.7 迁移学习
迁移学习:从一个任务中学到知识,然后将这些知识用到另一个独立的任务中。
一个猫咪图像分类器,已经训练好后,它具有了图像识别的能力,比如线条检测,阳性物体检测等。
现在要训练一个放射科医学影像检测网络,为了尽快训练出该网络,或者放射科医学影像数据过少,那么可以使用迁移学习(等于是复用猫咪分类器已经学习到的一些能力)。
如果数据量少,可以只替换原网络最后一层(也可以是最后一两层,也可以添加新的层,改变替换层的单元个数),初始化最后一层的权重,其他层权重固定。然后用这些数据训练。
如果数据量多,可以在原网络(即猫咪分类器)的基础上,用放射科医学影像接着训练整个网络的权重。
训练猫咪分类器的过程叫做预训练,训练放射科医学影像数据的过程叫做微调。
迁移学习什么时候有意义?
迁移的来源有很多数据,迁移的目标数据很少。
比如图像识别任务中,有着几百万条数据,所以可以学习到低层次的特征。可以在神经网络的前几层学到如何识别很多有用的特征。
但放射图像识别任务,也许只有100个样本。
那么,就可以把图像识别任务中学到的很多知识迁移到放射图像任务。这样可以提升放射图像识别任务的性能。

2.8 多任务学习(并行学习)
和迁移学习的区别是:迁移学习是串行的,先用任务A训练,再迁移到任务B。而多任务学习是并行的,同时用多个任务训练,同时开始学习多个任务。用单个网络同时处理好多事情。同时希望每个任务都可以帮助到其他任务。
和softmax的区别:softmax是一个多分类器,网络每次的预测值是一个,比如一张图像预测的结果是猫。多任务学习可以同时预测图像中是否存在猫咪,行人等。即一个样本有多个标签。

上图中,多任务学习的图像标签表示,存在车和停车标志,不存在行人和交通信号灯。
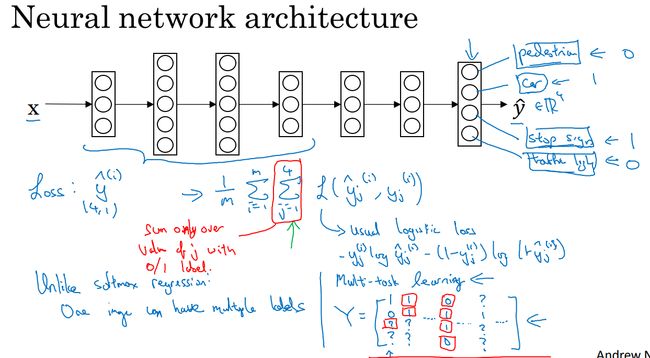
代价函数会增加 ∑4j=1 ∑ j = 1 4 ,即标签的四个分量之和。
一般情况下,损失函数是对数损失函数。

如果图像中标签值缺失,只需要将 ∑4j=1 ∑ j = 1 4 ,即分量,变成对为0/1 值的项进行求和即可。
在上例中,用一个网络预测四个任务,可以利用到神经网络的一些早期特征。这些早期特征在识别不同的物体时都会用到。这样一来,(在相同数据集的情况下)训练一个网络做四个任务比训练四个完全独立的网络分别做四个任务性能更好。
多任务学习有意义的地方:
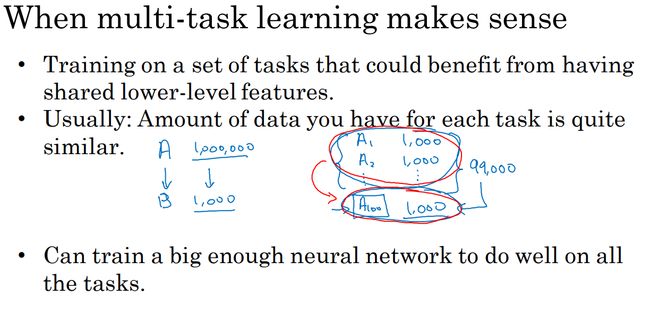
- 多个任务共享低层次特征;
- 一般来说,每个任务的数据量接近;
- 网络足够大。
2.9 什么是端到端的深度学习
以前的数据处理系统和学习系统需要多个阶段的处理。
而端到端只用一个神经网络。
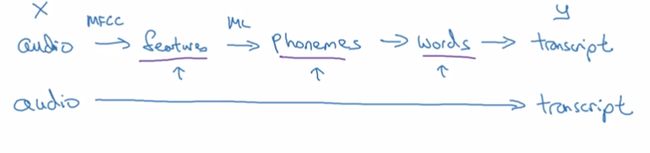
需要大量数据才能让端到端系统表现的良好。
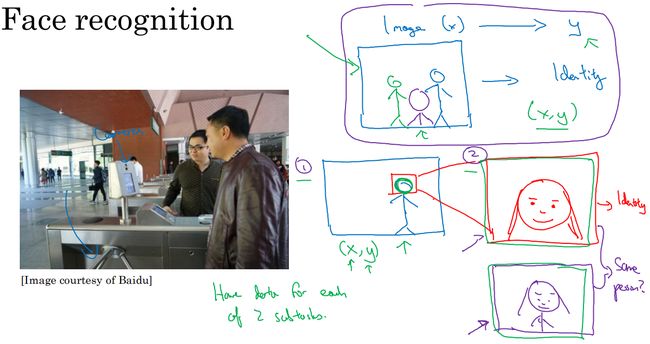
在人脸识别作为门禁的任务里边,直接将图片喂给单个网络,网络输出该人的身份。这样做的挑战是这种场景的图像太少了。
将问题一分为二。第一个任务,将图像中的人脸从环境中识别出来,然后裁剪居中。第二个任务将第一个任务处理完的图像拿来学习。这样,两个任务的数据量都很大。同时每个任务都足够简单。
也就是如果端到端算法所需要的数据不足,但是拆分成小的任务数据量足够,就可以拆分,不一定用端对端。
2.10 是否要使用端到端的深度学习

端对端优点:
- 让数据说话;
- 这样不会引入人类的成见。比如早期的语音识别系统用到了音位这个人类专家发明的概念。尽管用音位描述语言是合理的,但是最好还是不要强迫算法以音位为单位去思考。算法可能会找到更好的表达方法。
- 所需的手工设计组件更少;
- 这样能简化设计工作流程。
端对端缺点:
- 需要大量数据;
- 排除了可能有用的手工设计组件;
- 在数据量小的时候手工设计组件可以将人类知识直接注入到算法。算法通过数据和手工设计组件来获取知识。在数据量大的时候,可以忽略手工设计组件。但是数据量小的时候,将人类知识注入算法是有帮助的。手工设计组件是一把双刃剑,有可能非常有用,也有可能由于人类的局限性而伤害到算法表现。
是否使用端对端学习的关键问题是:
- 是否有足够的数据去直接学习出一个从x映射到y的足够复杂的函数。
尽管端对端的学习算法是听起来是激动人心的。但是在今天,无论是所能收集到的数据,还是能够用神经网络学习的数据类型,端到端都不是最有希望的办法。
在今天,端对端算法的前景不如复杂的多步方法。因为数据有限,训练神经网络的能力也有局限性。