如何理解LSTM的输入输出格式
1. 定义LSTM结构
bilstm = nn.LSTM(input_size=10, hidden_size=20, num_layers=2, bidirectional=True)
定义一个两层双向的LSTM,input size为10,hidden size为20。
注:定义过LSTM的结构后,同一个程序下面的input_size,hidden_size,num_layers应该与这里的是一致的。
2. 输入格式
官方文档:

input = torch.randn(5, 3, 10)#(seq_len, batch, input_size)
(1) 如果要输入的数据是一维的数据,则:
seq_len表示每个batch输入多少数据
batch表示把数据分成了batch批
input_size此时为为1
例如:
我们有原始数据data = 1,2,3,4,5,6,7,8,9,10 一共10个sample,接下来要将这些数据放进LSTM中进行处理,在处理之前我们需要对数据的形式进行变换,首先我们设定seq_len是3,则此时的数据形式为:
1-2-3,2-3-4,3-4-5,4-5-6,5-6-7,6-7-8,7-8-9,8-9-10,9-10-0,10-0-0(最后两个数据不完整,进行补零)
然后设定batch_size为2。
那我们取出第一个batch为1-2-3,2-3-4。这个batch的size就是(2,3,1)了。我们把这个玩意儿喂进模型。
接下来第二个batch为3-4-5,4-5-6。
第三个batch为5-6-7,6-7-8。
第四个batch为7-8-9,8-9-10。
第五个batch为9-10-0,10-0-0。我们的数据一共生成了5个batch。
(2)如果要输入的数据为二维数据
seq_len表示每个batch输入多少数据
batch表示把数据分成了batch批
input_size表示每个数据的属性向量的长度
例如:
data_ = [[1, 10, 11, 15, 9, 100],
[2, 11, 12, 16, 9, 100],
[3, 12, 13, 17, 9, 100],
[4, 13, 14, 18, 9, 100],
[5, 14, 15, 19, 9, 100],
[6, 15, 16, 10, 9, 100],
[7, 15, 16, 10, 9, 100],
[8, 15, 16, 10, 9, 100],
[9, 15, 16, 10, 9, 100],
[10, 15, 16, 10, 9, 100]]
seq_len=3,batch=2,input_size=6
这时我们的第一个batch为:
tensor([[[ 1., 10., 11., 15., 9., 100.],
[ 2., 11., 12., 16., 9., 100.],
[ 3., 12., 13., 17., 9., 100.]],
[[ 2., 11., 12., 16., 9., 100.],
[ 3., 12., 13., 17., 9., 100.],
[ 4., 13., 14., 18., 9., 100.]]])
最后一个batch为:
tensor([[[ 9., 15., 16., 10., 9., 100.],
[ 10., 15., 16., 10., 9., 100.],
[ 0., 0., 0., 0., 0., 0.]],
[[ 10., 15., 16., 10., 9., 100.],
[ 0., 0., 0., 0., 0., 0.],
[ 0., 0., 0., 0., 0., 0.]]])
3. 输出格式
官方文档:
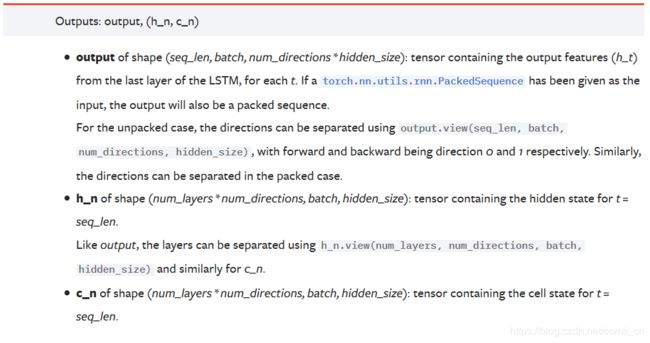 注解:
注解:
∙ \bullet ∙ output形状为(seq_len,batch,num_directions*hidden_size):这个张量包含着LSTM最后一层的每个周期的输出特征(h_t)。如果是双向LSTM,每个time step的输出h = [h正向, h逆向] (同一个time step的正向和逆向的h连接起来)
∙ \bullet ∙h_n保存了每一层,最后一个time step的输出h,如果是双向LSTM,单独保存前向和后向的最后一个time step的输出h。
∙ \bullet ∙c_n与h_n一致,只是它保存的是c的值
分析:
∙ \bullet ∙ output是一个三维的张量,第一维表示序列长度,第二维表示一批的样本数(batch),第三维是 hidden_size(隐藏层大小) * num_directions ,其中num_directions根据是“否为双向”取值为1或2。因此,我们可以知道,output第三个维度的尺寸根据是否为双向而变化,如果不是双向,第三个维度等于我们定义的隐藏层大小;如果是双向的,第三个维度的大小等于2倍的隐藏层大小。
∙ \bullet ∙ h_n是一个三维的张量,第一维是num_layersnum_directions,num_layers是我们定义的神经网络的层数,num_directions在上面介绍过,取值为1或2,表示是否为双向LSTM。第二维表示一批的样本数量(batch)。第三维表示隐藏层的大小。第一个维度是h_n难理解的地方。首先我们定义当前的LSTM为单向LSTM,则第一维的大小是num_layers,该维度表示第n层最后一个time step的输出。如果是双向LSTM,则第一维的大小是2 * num_layers,此时,该维度依旧表示每一层最后一个time step的输出,同时前向和后向的运算时最后一个time step的输出用了一个该维度。
举个例子:我们定义一个num_layers=3的双向LSTM,h_n第一个维度的大小就等于 6(23),h_n[0]表示第一层前向传播最后一个time step的输出,h_n[1]表示第一层后向传播最后一个time step的输出,h_n[2]表示第二层前向传播最后一个time step的输出,h_n[3]表示第二层后向传播最后一个time step的输出,h_n[4]和h_n[5]分别表示第三层前向和后向传播时最后一个time step的输出。
∙ \bullet ∙c_n与h_n的结构一样,就不重复赘述了。
4. 一些参数的理解
∙ \bullet ∙ seq_len这里的input_size会用在对一个单词或者一个数据进行描述的时候,这样能让这个单词或者数据更容易让机器理解
∙ \bullet ∙batch 批处理,这里是指每训练完一批之后更新一次参数,如果不把数据分成一批一批更新数据而是一个一个更新的话运算量太大,时间太长,如果整个计算完再更新参数的话最终误差会比较大。
5. 列在一起
input(seq_len,batch,input_size)
rnn = torch.nn.LSTM(input_size,hidden_size,num_layers)
h0(num_layers*num_directions,batch,hidden_size)
c0(num_layers*num_directions,batch,hidden_size)
output(seq_len,batch,num_direction*hidden_size)
hn(num_layers*num_directions,batch,hidden_size)
cn(num_layers*num_directions,batch,hidden_size)
pytorch官方文档中的LSTM.
输入格式的理解
输出格式的理解
Keras中LSTM的输入输出格式