Flume(0)Flume1.9安装部署
系统要求
- Java运行时环境 - Java 1.8或更高版本
- 内存 - 源,通道或接收器使用的配置的足够内存
- 磁盘空间 - 通道或接收器使用的配置的足够磁盘空间
- 目录权限 - 代理使用的目录的读/写权限
下载及安装
1.下载
到Flume官网上http://flume.apache.org/download.html下载软件安装包,如图:
2. 解压
mkdir -p /usr/local/flume
tar -zxvf apache-flume-1.9.0-bin.tar.gz -C /usr/local/flume/
3.设置环境变量
FLUME_HOME=/usr/local/flume/apache-flume-1.9.0-bin
PATH=$FLUME_HOME/bin:$PATH
source /etc/profile
4.配置JAVA_HOME
cd /usr/local/flume/apache-flume-1.9.0-bin/conf
cp flume-env.sh.template flume-env.sh
vi flume-env.sh

5.配置详解
主要介绍poolingDirectory Source,HDFS Sink,MemoryChannel, File Channel 四种,其他请参考官方文档。
- spoolingDirectory Source
Spooling Directory Source可以获取硬盘上“spooling”目录的数据,这个Source将监视指定目录是否有新文件,如果有新文件的话,就解析这个新文件。事件的解析逻辑是可插拔的。在文件的内容所有的都读取到Channel之后,Spooling Directory Source会重名或者是删除该文件以表示文件已经读取完成。
不像Exec Source,这个Source是可靠的,且不会丢失数据。即使Flume重启或者被Kill。但是需要注意如下两点:
- 如果文件在放入spooling目录之后还在写,那么Flume会打印错误日志,并且停止处理该文件。
- 如果文件之后重复使用,Flume将打印错误日志,并且停止处理。
为了避免以上问题,我们可以使用唯一的标识符来命令文件,例如:时间戳。
| 属性名 | 默认 | 描述 |
|---|---|---|
| channels | – | |
| type | – | 组件名:spooldir. |
| spoolDir | – | 读取文件的目录。 |
| fileSuffix | .COMPLETED | Spooling读取过的文件,添加的后缀。 |
| deletePolicy | never | 完成后的文件是否删除。never:不删除 或 immediate:立即删除 |
| fileHeader | FALSE | 是不把路径加入到Heander |
| fileHeaderKey | file | 路径加入到Header的Key是什么 |
| basenameHeader | FALSE | 是不把文件名加入到Heander |
| basenameHeaderKey | basename | 文件名加入到Header的Key是什么 |
| ignorePattern | ^$ | 采用正则表达是去过滤一些文件。只有符合正则表达式的文件才会被使用。 |
| trackerDir | .flumespool | 被处理文件的元数据的存储目录,如果不是绝对路径,就被会解析到spoolDir目录下。 |
| consumeOrder | oldest | 消费spooling目录文件的规则,分别有:oldest,youngest和random。在oldest 和 youngest的情况下,通过文件的最后修改时间来比较文件。如果最后修改时间相同,就根据字典的序列从小开始。在随机的情况下,就随意读取文件。如果文件列表很长,采用oldest/youngest可能会很慢,因为用oldest/youngest要扫描文件。但是如果采用random的话,就可能造成新的文件消耗的很快,老的文件一直都没有被消费。 |
| maxBackoff | 4000 | 如果Channel已经满了,那么该Source连续尝试写入该Channel的最长时间(单位:毫秒)。 |
| batchSize | 100 | 批量传输到Channel的粒度。 |
| inputCharset | UTF-8 | 字符集 |
| decodeErrorPolicy | FAIL | 在文件中有不可解析的字符时的解析策略。FAIL: 抛出一个异常,并且不能解析该文件。REPLACE: 取代不可解析的字符,通常用Unicode U+FFFD. IGNORE: 丢弃不可能解析字符序列。 |
| deserializer | LINE | 自定序列化的方式,自定的话,必须实现EventDeserializer.Builder. |
| deserializer.* | ||
| bufferMaxLines | – | 已废弃。 |
| bufferMaxLineLength | 5000 | (不推荐使用) 一行中最大的长度,可以使用deserializer.maxLineLength代替。 |
| selector.type | replicating | replicating(复制) 或 multiplexing(复用) |
| selector.* | 取决于selector.type的值 | |
| interceptors | – | 空格分割的interceptor列表。 |
| interceptors.* |
2.HDFS Sink
| 属性名 | 默认值 | 描述 |
|---|---|---|
| channel | – | |
| type | – | 组件的名称,必须为:HDFS |
| hdfs.path | – | HDFS目录路径,例如:hdfs://namenode/flume/webdata/ |
| hdfs.filePrefix | FlumeData | HDFS目录中,由Flume创建的文件前缀。 |
| hdfs.fileSuffix | – | 追加到文件的后缀,例如:.txt |
| hdfs.inUsePrefix | – | 文件正在写入时的前缀。 |
| hdfs.inUseSuffix | .tmp | 文件正在写入时的后缀。 |
| hdfs.rollInterval | 30 | 当前写入的文件滚动间隔,默认30秒生成一个新的文件 (0 = 不滚动) |
| hdfs.rollSize | 1024 | 以文件大小触发文件滚动,单位字节(0 = 不滚动) |
| hdfs.rollCount | 10 | 以写入的事件数触发文件滚动。(0 = 不滚动) |
| hdfs.idleTimeout | 0 | 超时多久以后关闭无效的文件。(0 = 禁用自动关闭的空闲文件)但是还是可能因为网络等多种原因导致,正在写的文件始终没有关闭,从而产生tmp文件 |
| hdfs.batchSize | 100 | 有多少Event后,写到文件才刷新到HDFS。 |
| hdfs.codeC | – | 压缩编解码器,可以使用:gzip, bzip2, lzo, lzop, snappy |
| hdfs.fileType | SequenceFile | 文件格式:通常使用SequenceFile(默认), DataStream 或者 CompressedStream (1)DataStream不能压缩输出文件,请不用设置hdfs.codeC编码解码器。 (2)CompressedStream要求设置hdfs.codeC来制定一个有效的编码解码器。 |
| hdfs.maxOpenFiles | 5000 | HDFS中允许打开文件的数据,如果数量超过了,最老的文件将被关闭。 |
| hdfs.callTimeout | 10000 | 允许HDFS操作的毫秒数,例如:open,write, flush, close。如果很多HFDS操作超时,这个配置应该增大。 |
| hdfs.threadsPoolSize | 10 | 每个HDFS sink的HDFS的IO操作线程数(例如:open,write) |
| hdfs.rollTimerPoolSize | 1 | 每个HDFS sink调度定时文件滚动的线程数。 |
| hdfs.kerberosPrincipal | – | 安全访问HDFS Kerberos的主用户。 |
| hdfs.kerberosKeytab | – | 安全访问HDFS Kerberos keytab |
| hdfs.proxyUser | ||
| hdfs.round | FALSE | 时间戳应该被四舍五入。(如果为true,会影响所有的时间,除了t%) |
| hdfs.roundValue | 1 | 四舍五入的最高倍数(单位配置在hdfs.roundUnit),但是要小于当前时间。 |
| hdfs.roundUnit | second | 四舍五入的单位,包含:second, minute or hour. |
| hdfs.timeZone | Local Time | 时区的名称,主要用来解决目录路径。例如:America/Los_Angeles |
| hdfs.useLocalTimeStamp | FALSE | 使用本地时间替换转义字符。 (而不是event header的时间戳) |
| hdfs.closeTries | 0 | 在发起一个关闭命令后,HDFS sink必须尝试重命名文件的次数。如果设置为1,重命名失败后,HDFS sink不会再次尝试重命名该文件,这个文件处于打开状态,并且用.tmp作为扩展名。如果为0,Sink会一直尝试重命名,直至重命名成功。如果文件 失败,这个文件可能一直保持打开状态,但是这种情况下数据是完整的。文件将会在Flume下次重启时被关闭。 |
| hdfs.retryInterval | 180 | 在几秒钟之间连续尝试关闭文件。每个关闭请求都会有多个RPC往返Namenode,因此设置的太低可能导致Namenode超负荷,如果设置0或者更小,如果第一次尝试失败的话,该Sink将不会尝试关闭文件。并且把文件打开,或者用“.tmp”作为扩展名。 |
| serializer | TEXT | 可能的选项包括avro_event或继承了EventSerializer.Builder接口的类名。 |
| serializer.* |
3.MemoryChannel
事件存储在具有可配置的最大大小的内存队列中。对于需要更高吞吐量的流程来说是理想的,并且在代理失败的情况下准备丢失阶段数据。
| 属性名 | 默认值 | 描述 |
|---|---|---|
| type | - | memory |
| capacity | 100 | MemroyChannel的容量 |
| transactionCapacity | 100 | 每个事务最大的容量,也就是每个事务能够获取的最大Event数量。默认也是100 |
| Keep-alive | 3 | 增加和删除一个Event的超时时间(单位:秒) |
| byteCapacityBufferPercentage | 20 | 义Channle中Event所占的百分比,需要考虑在Header中的数据。 |
4.File Channel
| 属性名 | 默认值 | 描述 |
|---|---|---|
| type | – | file |
| checkpointDir | ~/.flume/file-channel/checkpoint | 存储文件检查点目录 |
| useDualCheckpoints | FALSE | 备份检查点. 如果为true, backupCheckpointDir 必填 |
| backupCheckpointDir | – | 文件检查点的备份目录,不能和checkpointDir相同。 |
| dataDirs | ~/.flume/file-channel/data | 用于存储日志文件目录,多目录用逗号分隔。 |
| transactionCapacity | 10000 | 通道支持的事务的最大大小。 |
| checkpointInterval | 30000 | 检查点时间间隔(毫秒) |
| maxFileSize | 2146435071 | 单个文件最大大小(字节) |
| minimumRequiredSpace | 524288000 | 最小需要的自由空间(以字节为单位)。为了避免数据损坏,当空闲空间低于该值时,文件通道停止接受“取/放”请求。 |
| capacity | 1000000 | 信道最大容量 |
| keep-alive | 3 | 等待放置操作时间(秒) |
| use-log-replay-v1 | FALSE | Expert: 使用旧的回放逻辑 |
| use-fast-replay | FALSE | Expert: 不使用队列回放 |
| checkpointOnClose | TRUE | 控制是否在关闭通道时创建检查点。在关闭时创建检查点通过避免重放加速文件通道的后续启动. |
| encryption.activeKey | – | 用于加密新数据的密钥名称 |
| encryption.cipherProvider | – | 密钥提供者类型:AESCTRNOPADDING |
| encryption.keyProvider | – | 密钥提供程序类型: JCEKSFILE |
| encryption.keyProvider.keyStoreFile | – | 密钥存储文件路径 |
| encrpytion.keyProvider.keyStorePasswordFile | – | 密钥存储密码文件路径 |
| encryption.keyProvider.keys | – | 所有密钥列表 (e.g. history of the activeKey setting) |
| encyption.keyProvider.keys.*.passwordFile | – | 可选密钥密码文件的路径6 |
6.版本验证
flume-ng version
Flume部署示例
1.Avro
cp flume-conf.properties.template netcat.conf
配置netcat.conf
agent.sources = seqGenSrc
agent.channels = memoryChannel
agent.sinks = loggerSink
agent.sources.seqGenSrc.type = netcat
agent.sources.seqGenSrc.bind = 10.10.2.137
agent.sources.seqGenSrc.port = 44445
agent.sources.seqGenSrc.channels = memoryChannel
agent.sinks.loggerSink.type = logger
agent.sinks.loggerSink.channel = memoryChannel
# Each channel's type is defined.
agent.channels.memoryChannel.type = memory
agent.channels.memoryChannel.capacity = 100
运行
flume-ng agent --conf /usr/local/flume/apache-flume-1.9.0-bin/conf --conf-file /usr/local/flume/apache-flume-1.9.0-bin/conf/netcat.conf --name agent -Dflume.root.logger=INFO,console

打开另一终端,通过telnet登录localhost的44445,输入测试数据
2 Spool
Spool用于监测配置的目录下新增的文件,并将文件中的数据读取出来。需要注意两点:拷贝到spool目录下的文件不可以再打开编辑、spool目录下不可包含相应的子目录。具体示例如下:
cp flume-conf.properties.template spool1.conf
cp flume-conf.properties.template spool2.conf
配置spool1.conf
agent.sources = spoolSource
agent.channels = memoryChannel
agent.sinks = avroSink
agent.sources.spoolSource.type = spooldir
agent.sources.spoolSource.spoolDir=/usr/local/flume/data
agent.sources.spoolSource.channels = memoryChannel
agent.sinks.avroSink.type = avro
agent.sinks.avroSink.hostname=10.10.2.137
agent.sinks.avroSink.port=60000
agent.sinks.avroSink.channel = memoryChannel
agent.channels.memoryChannel.type = memory
agent.channels.memoryChannel.capacity = 1000000
配置spool2.conf
agent.sources = avroSrc
agent.channels = memoryChannel
agent.sinks = hdfsSink
agent.sources.avroSrc.type = avro
agent.sources.avroSrc.bind=10.10.2.137
agent.sources.avroSrc.port=60000
agent.sources.avroSrc.channels = memoryChannel
agent.sinks.hdfsSink.type = hdfs
agent.sinks.hdfsSink.hdfs.path = hdfs://10.10.1.142:9000/user/flumeData
agent.sinks.hdfsSink.rollInterval=0
agent.sinks.hdfsSink.hdfs.writeFormat=Text
agent.sinks.hdfsSink.hdfs.fileType=DataStream
agent.sinks.hdfsSink.channel= memoryChannel
agent.channels.memoryChannel.type = memory
agent.channels.memoryChannel.capacity = 1000000
运行
先启动spool2.conf
flume-ng agent --conf /usr/local/flume/apache-flume-1.9.0-bin/conf --conf-file /usr/local/flume/apache-flume-1.9.0-bin/conf/spool2.conf --name agent -Dflume.root.logger=INFO,console
报错:Failed to start agent because dependencies were not found in classpath. Error follows.
java.lang.NoClassDefFoundError: org/apache/hadoop/io/SequenceFile$CompressionType问题原因:缺少依赖包,这个依赖包是以下jar文件:
${HADOOP_HOME}/share/hadoop/common/*.jar
${HADOOP_HOME}/share/hadoop/common/lib/*.jar
解决方法:找到这些jar文件,copy到flume安装目录下的lib目录下就ok了。
报错:[WARN - org.apache.flume.sink.hdfs.HDFSEventSink.process(HDFSEventSink.java:455)] HDFS IO error
java.io.IOException: No FileSystem for scheme: hdfs
解决方法:${HADOOP_HOME}/share/hadoop/hdfs/*.jar,找到这些jar文件,copy到flume安装目录下的lib目录下就ok了。
再启动spool1.conf
flume-ng agent --conf /usr/local/flume/apache-flume-1.9.0-bin/conf --conf-file /usr/local/flume/apache-flume-1.9.0-bin/conf/spool1.conf --name agent -Dflume.root.logger=INFO,console
Source类型
Flume内置了大量的Source,其中Avro Source、Thrift Source、Spooling Directory Source、Kafka Source具有较好的性能和较广泛的使用场景。下面是Source的一些参考资料:


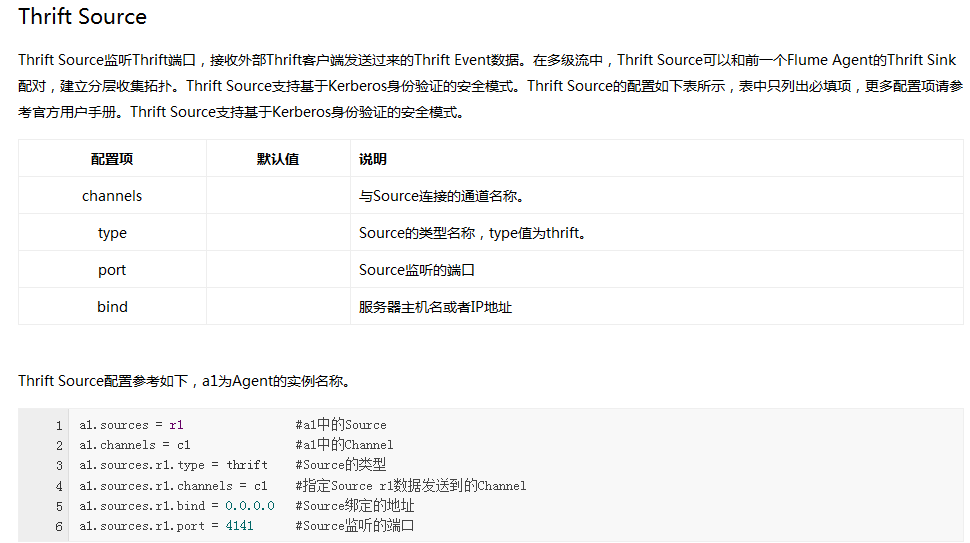
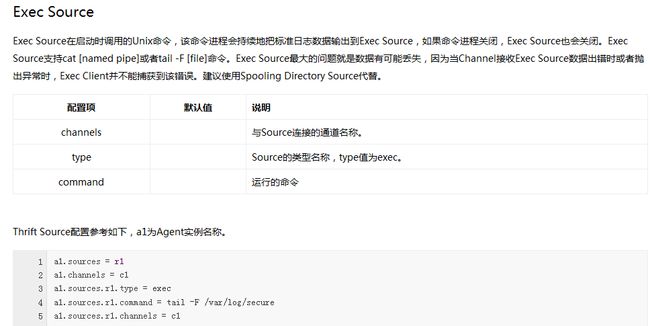
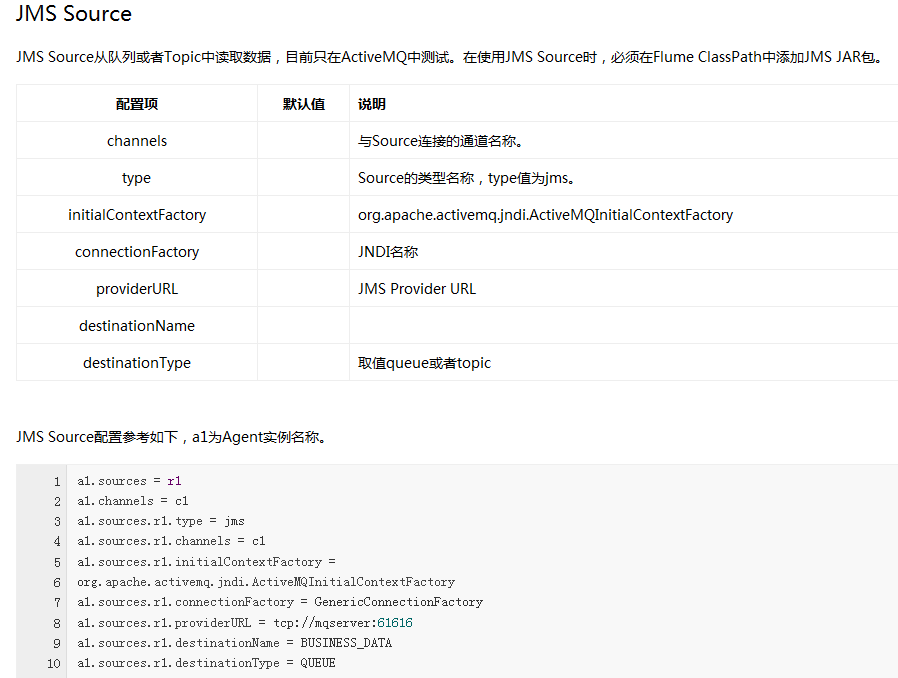
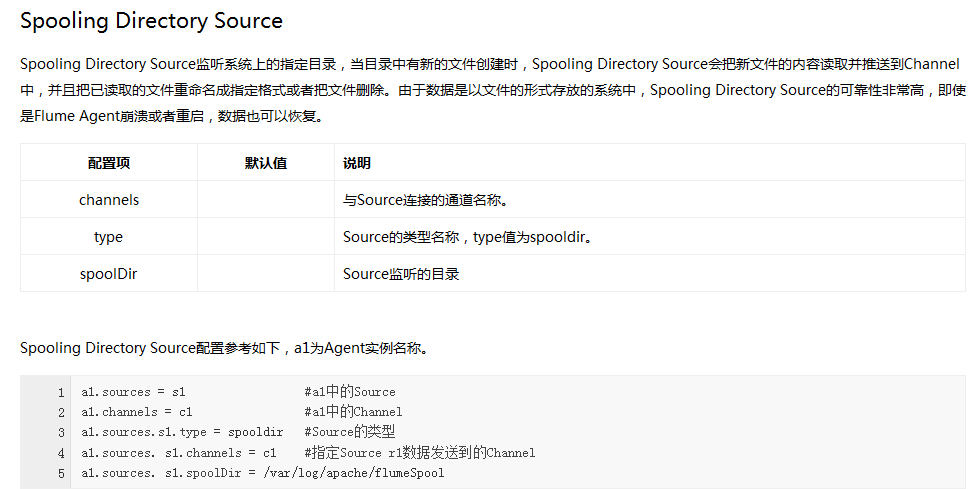

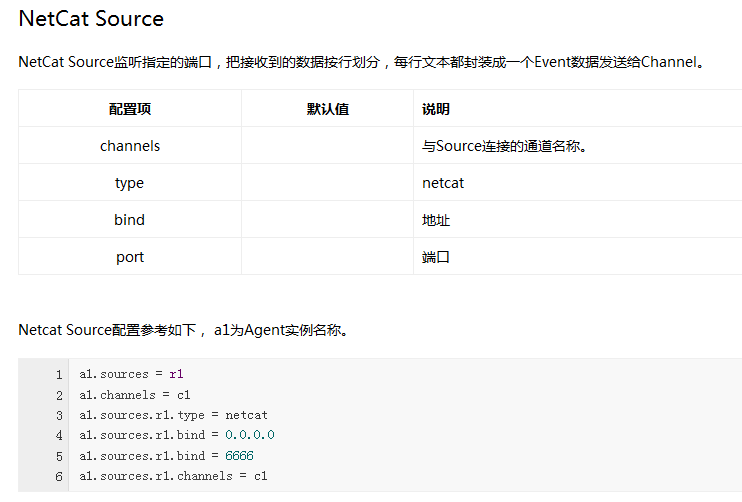
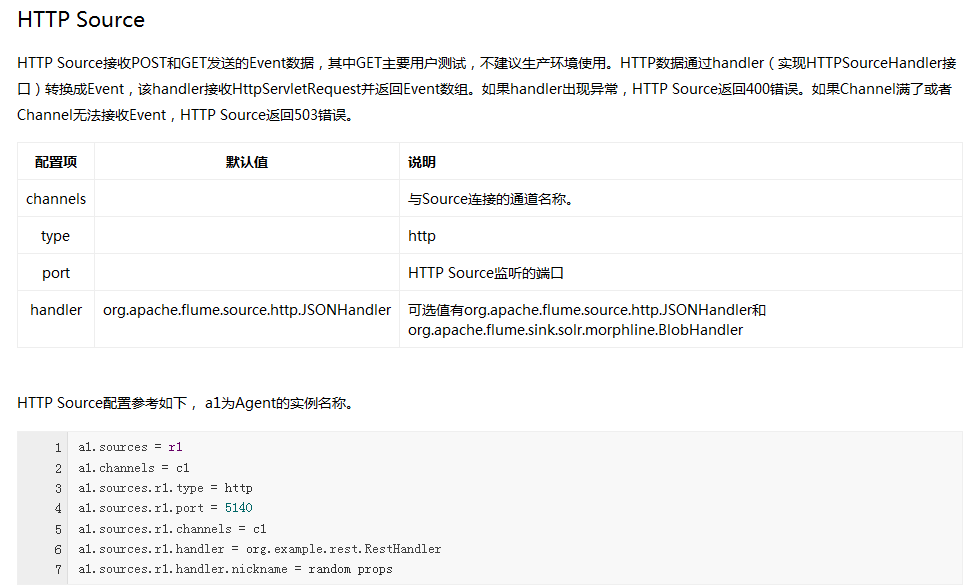
Channel类型
Flume中提供的Channel实现主要有四个:
- Memory Channel event保存在Java Heap中。如果允许数据小量丢失,推荐使用
- File Channel event保存在本地文件中,可靠性高,但吞吐量低于Memory Channel
- JDBC Channel event保存在关系数据中,一般不推荐使用
- Kafka Channel events存储在Kafka集群中
如果对您有用请点赞 评论 关注 作者