阿里“去 IOE”十二年,弹性计算如何二次去 I 和 E?

【CSDN 编者按】王坚院士曾讲过一句话让人印象深刻,他说「云计算的本质是服务,如果不能将计算资源规模化、大范围地进行共享,如果不能真正以服务的方式提供,就根本算不上云计算。」众所周知,阿里云是完全经历了从 0 到 1,再到 100 的过程,将计算发挥到极致背后有一个关键的服务,那就是弹性计算。
阿里云弹性计算是阿里云提供的 IaaS 级别云计算服务,它免去了客户采购 IT 硬件的前期准备,让客户像使用水、电、天然气等公共资源一样便捷、高效地使用计算资源,实现计算资源的即开即用和弹性伸缩。在「CSDN 在线峰会 —— 阿里云核心技术竞争力」上,阿里云研究员蒋林泉(花名:雁杨)深入分享了在众多大规模实践下百炼成钢的弹性计算。
复制链接可免费观看分享视频:
https://edu.csdn.net/huiyiCourse/detail/1176

演讲者 | 蒋林泉(雁杨),阿里云研究员
责编 | 唐小引
头图 | CSDN 下载自东方 IC
出品 | CSDN(ID:CSDNnews)

前言:弹性计算 More than just 虚拟机
一般而言,大家理解的弹性计算,可能首先会想到是虚拟机、云服务器。
但弹性计算除了是众所周知的 IaaS 的核心——云服务器 ECS 之外,还是一个完整的产品家族,而不只是虚拟机。
弹性计算不仅是阿里云的大底座,更是阿里巴巴集团的大底座,能够用强大的性能、稳定性、弹性、效率能力来支撑云上客户和阿里云的云产品。目前,中国 80% 的创新企业都在使用我们的弹性计算产品,更有 99% 的阿里云其他产品是在弹性计算产品之上为客户提供服务。

对于弹性计算而言,我们所承担的角色可从三个切面去看待,即制造商、零售(运营)商和服务商:
制造商负责设计虚拟机/云服务器,以满足客户不同的场景需求;
零售(运营)商负责将这些实例售卖出去,提供按量付费、包年包月、RI 以及抢占式实例等多种付费方式,使得售卖形态更加灵活;
服务商则提供大规模集群部署、运维、迁移和弹性伸缩套件产品,实现客户从 Capex 走向 Opex,让客户能够轻松在时间域和空间域上实现扩容,高效交付、部署和运维大规模云服务器。

零售商(运营商):资源池化&弹性
我们先从零售商的角度来理解弹性计算。
对于零售商而言,需要考虑如何将弹性资源卖出去,如何让客户使用这种池化后的弹性资源。
零售商主要是让用户的服务器从购买变成租赁形态,可以按照年或者月进行付费,这样更符合客户的使用习惯,阿里云也提供按使用量,甚至是通过竞价闲置资源的方式来进行付费,使得客户可以享受到在线下无法实现的付费方式来节约成本。
在弹性计算的底层提升供应链效率,进行服务器硬件资源虚拟化以及调度,并且保证非常高的 SLA,来给客户提供弹性能力。

▐ 狭义弹性:时域维度的弹性
我们先来讲讲狭义的弹性。所谓狭义弹性就是时域维度的弹性。
如下图中白色条线,这表示的就是时域的弹性,企业上线新特性、年中促销或者日常促销,甚至是业务发展变化很快,后台的计算能力却往往不能很快跟上。

一般传统企业的解决方式其实是提前备货,提前一年甚至三年做预算,进行 IT 资源的储备。其目标是为了保证在未来一到两年内,业务都不会因为容量不够而受损,这也是导致大量线下传统企业的日常 CPU 利用率无法达到 5% 的原因。
最糟糕的情况是,当有新业务上线需要大规模容量的时候,IT 资源无法支撑,这样的矛盾就会使得上图中间的虚线部分越来越大。因此,传统方式要么就会造成浪费计算资源和资金,要么就无法很好地支撑业务的快速增长。
▐ ECS 狭义弹性能力:天下武功,唯快不破
对于狭义弹性而言,更多需要考虑如何让其跑得更快,当需要资源的时候以最快的速度给到客户。
目前,阿里云云服务器 ECS 从开启服务器到 SSH 可以登录只需要 22 秒的时间,同时,单位时间内能够交付的计算力面积,可以做到单客户、单 Region 5 分钟 16 万核 vCPU 的交付能力。

▐ 弹性容量自动伸缩最佳实践
我们来看看一个弹性容量的最佳实践案例。
首先,企业客户需要守住自己的一个底座,也就是自己日常流量所需的计算资源,也就是下图中绿色的线,这部分比较适合使用包年包月或者 RI 的模式,因为价格比较便宜。
而在底座之上的弹性部分则可以使用按量计费或者抢占式的计算资源帮助消除峰值流量,再加上 ESS 的自动化,就能够实现在不同流量峰谷的时候可以自动包裹业务曲线。
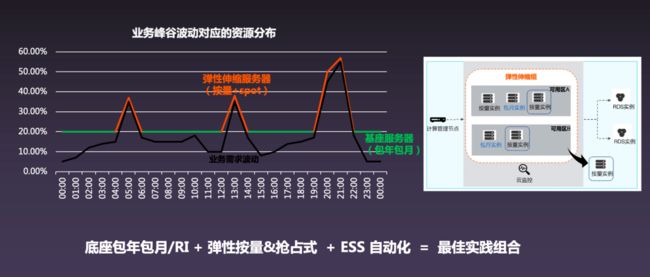
▐ 容量弹性:ESS 弹性自动化 4 种模式
ESS 弹性自动化提供了 4 种模式,即定时模式、动态模式、手动+动态模式和 AI 预测模式:
定时模式适用于业务波动的时间和范围均可准确预测的场景;
动态模式适合业务波动的时间和范围完全不可预测的场景,根据 CPU 和内存负载情况,进行自动扩容;
手动+动态模式是两者叠加使用,适合业务波动范围较小,但时间不可预测的场景;
AI 预测模式则根据历史资源使用量的峰谷和时域特征拟合,通过智能分析预测来做提前扩容,保证在可能的峰值来临之前,就可以完成资源的准备。

通过多种伸缩模式的灵活组合,能够帮助企业快速响应计划内外的业务变化,实现按需取用,降低成本,自动智能运维,甚至是零运维。
▐ 广义弹性:基础设施规模全预铺-空间域的弹性
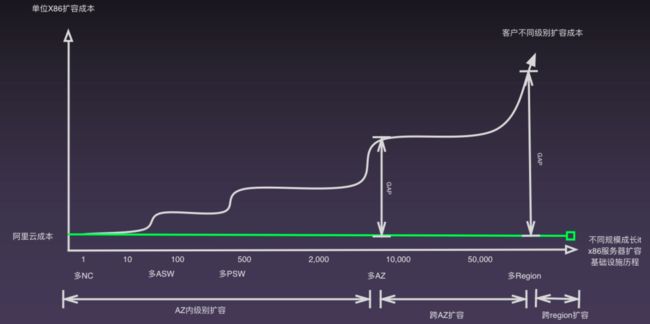
第二个维度与大家分享广义弹性。云,特别是像阿里云这么大规模的云,很大的一个特征就是基础设施规模化的全铺设,也就是说具有了空间域的弹性。
任何一个物理设备,都有扩容上限。当扩张到上限的时候,就会遇到扩容墙的问题,此时就需要设备全部迁移到另外一个地域并重新启动,无法做到跨地域调度。
云计算则能够实现跨机房、跨可用区,甚至是跨 Region 的扩容。阿里云拥有日不落的数据中心,业务部署到海外也是非常容易的,这就是广义的弹性——空间域的弹性。
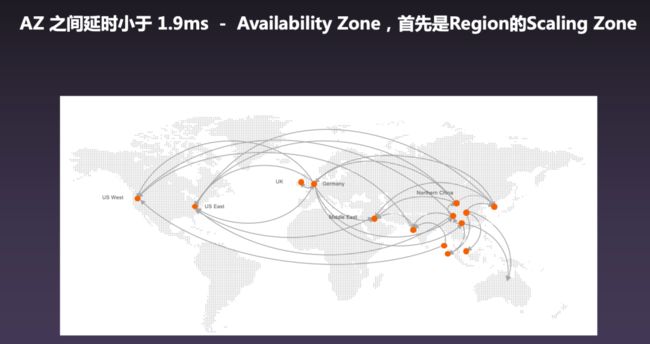
▐ 广义弹性:空间域上覆盖全球的大规模基础设施
大家经常会听到阿里云部署了多少个 Region 以及多少个 AZ(Availability Zone,可用区),而 AZ 之间是互联的,延时也有严格的保障,因此用户可以突破 IDC 的边界,扩容自己的应用。
▐ 广义弹性:在 ECS 之上,使用丰富云服务拓展应用的系统支撑能力的弹性
ECS 会映射到线下的 IDC 服务器,因此无论是数据库还是应用,都是购买软件之后进行交付、运维和使用。对多数云上系统各种 Workload,都可以基于 ECS 用软件自己搭建。
同时,阿里云还提供了大规模的服务化的云产品,一定会有一款满足你。比如数据库、容器、函数、中间件等都已经实现了服务化,客户不需要去安装、运维和管理这些软件,而能够利用这些软件的弹性实现开箱即用,且按时付费。而且这些软件的数量和质量还不断的进化,因此选择上云还能够为将来拓展应用能力的弹性奠定基础。

制造商:性能优异,稳如磐石
客户的应用都在这个云服务器上面,因此性能很重要。云厂商生产了各种不同规格的云服务器,通过 IDC、物理机、网络资源之上的这些操作系统将其切成资源池给到客户。
这样就像是工业 4.0,客户选择了配置,如内核、CPU、内存、磁盘、操作系统等,阿里云会将这些资源调度到一台机器上,实时生产出来交给用户。
阿里云提供了封装形态、规格族、规格大小粒度这样广谱覆盖的实例矩阵来覆盖用户在不同场景下对于计算力的需求。

▐ 制造商成功的本分:稳定性&性能
中国是个制造业大国,而制造商成功的本分其实就是稳定性和性能。阿里云具有计算、网络、存储性能的稳定性,AZ 内、AZ 间、Region 间以及网络性能的稳定性。
此外,加上飞天操作系统在计算、存储、网络 3 个底层技术上的不断投入,以及大规模调度系统,结合底层硬件不断进行研发迭代,实现高性能和成本红利。

▐ 云的稳定性
云的稳定性主要挑战在两个方面:宕机迁移业务恢复,磁盘损坏不丢数据;硬件批量维修、过保,保证客户对过保无感。
阿里云将运维和虚拟化解耦,可以做到用户无感的物理硬件替换,对客户业务的连续性打扰降低到非常小的程度,这正是云上核心的稳定性逻辑。

弹性计算的“二次去 I”:用 x86 硬件,挑战小机型稳定性
下图中数据来自于各厂商官网,阿里云 ECS 单实例可用性 SLA 可以达到 99.975%,跨可用区多实例可用性 SLA 可达到 99.995%。

标题中的“二次去 I”指的是阿里云在服务客户的过程中发现客户单实例对稳定性要求也非常高。
在“第一次去 IOE”的时候,用的是应用层的分布式技术来解决 x86 的稳定性问题。而在弹性计算领域,则是用基础层的能力去解决 x86 的稳定性问题,目标是用 x86 的硬件做到和小型机一样的稳定性,这就是“二次去 I”。客户的技术能力各不相同,有很大一部分客户对单机的稳定性有非常高的依赖,无法做应用层的容灾,这样严苛的需求就推动阿里云的服务要达到小型机的稳定性,阿里云的基础沉淀了多年,才得以实现这样的业界领先的 SLA。
弹性计算的云盘快存储“二次去 E”:业界主流厂商云盘可靠性 SLO 一览
阿里云云盘的可靠性能够做到“9 个 9”,也是目前业界领先的,需要非常严谨和先进的技术架构来保障。通过分布式的基于 x86 的软件定义存储,替代掉原来商业非常昂贵的存储,并达到了存储的高可靠性。
80% 的宕机,都来自 IDC 电力、IDC 网络和服务器系统三类原因
阿里云是如何做到上述能力的呢?其实对于服务器而言,80%的宕机,都来自 IDC 电力、IDC 网络和服务器系统三类原因。接下来针对于这三个原因谈谈阿里云所做的事情。
强健的电力,强健的网络带来强健的 IDC 基础设施
IDC 掉电的新闻中经常出现,属于高频事件。阿里云在 IDC 的管理上非常严格,拥有高可用电力架构、网络架构以及 3+N 多线 BGP 接入,这也源于多年来的经验和教训,才形成背后成熟的管理体系和技术体系。阿里云帮助客户消除掉了 IDC 机房的大部分电力、网络的可用性威胁。

冗余架构
举一个例子,阿里云在服务器和接入交换机的架构上,存储、网络和云盘等都是通过网卡虚拟化出来的。服务器上的电力、网络,都是双线接入的。通过自研技术,在服务器、飞天操作系统中实现物理网络的路由切换。如果这个地方是个单点,没有双路就经常会出现各种各样的问题。阿里云选择在软件侧实现冗余的网络线路路由调度。

批量运维变更故障规避技术平台
既然是大规模的云,技术迭代和产品更新背后就会有大量的系统发布和变更。如何让其变得更稳定?阿里云背后依赖于非常高精尖的热迁移技术,95% 以上的热迁移,对所有用户都是无感的。

玄机大脑的异常预测&调度
飞天操作系统中的玄机大脑能够对于异常进行预测,做提前的热迁移,实现对客户服务的稳定性。
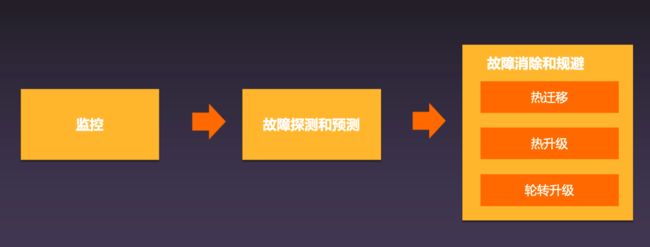
核心部件的故障预测:准确率和召回率高达 99%
阿里云核心部件的故障预测的准确率和召回率高达 99%,这背后来自于阿里巴巴这么多年的技术积累。阿里巴巴是一家数据公司,拥有 10 年百万级的服务器打标的高质量数据,再结合达摩院科学家的合作,通过算法训练让这些数据产生价值,提前预测硬件的健康程度,再结合热迁移的能力,实现服务的稳定性。
成果:70% 的用户可感知故障被消除&规避
目前,阿里云由于硬件产生的问题中的 70% 都是客户无感的。很多用户使用云服务器已经大约 2 到 3 年的时间了,底层的硬件可能已经更换了 2 至 3 次,但是自己却毫无感知,也没有重启过。这就是使用 x86 的硬件实现了小型机的稳定性。
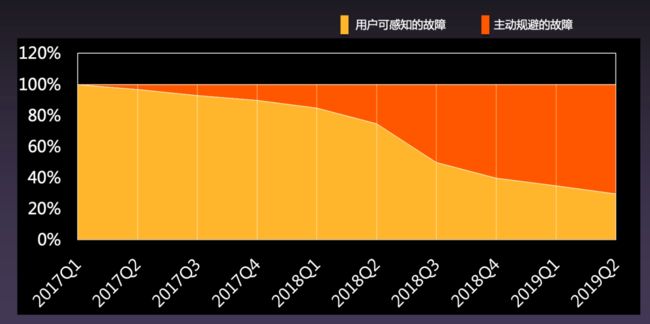
为何弹性计算如此看重稳定性:进化的力量
阿里云之所以这么看重稳定性并做了大量的投入,主要是因为技术进化的力量。双 11 一直在考验阿里巴巴集团的系统,不断发现小问题并快速逐一修复。
此外,还有一个原因就是客户群体的差异,中美的云计算成熟度存在一些差异,在北美或者欧洲,IT 客户群体的能力相对成熟,可以在应用上做容灾,对服务稳定性的依赖相对较小,而国内的 IT 客户群体还不够成熟,很多客户强依赖单机的稳定性,这就让阿里云必须重视稳定性的提升。
阿里云带着一个梦想,就是能够通过努力,降低中国企业创业的门槛,减小企业数字化转型的阻力,这些都是驱动弹性计算不断进化的驱动力。
▐ 云的优异性能
讲完稳定性,我们来讲讲性能。
业界领先的 E2E 性能
虚拟化使得 IT 业务的灵活度、交互效率大大提升,而带来的问题其实就是虚拟化的损耗,这就需要从技术上不断进步。阿里云弹性计算具有业界领先的 E2E 性能,ECS 第六代相比第五代在性能方面在 MySQL、nginx、Redis 等场景下都有了大幅度提升,并且综合性能超越市场同类主售产品。

ECS 性能更强,成本更低的秘密——全链路自研底层技术
无论是神龙、盘古、洛神,还是阿里自研的 IDC 网络和服务器,这些全链路的融合以及软硬结合,会持续地进行迭代,将技术红利提供给客户和市场。

高性能背后的自研技术:神龙计算平台
阿里自研的神龙计算平台在 2017 年发布第一代产品,并且每年都在迭代,现在给客户提供服务的是第二代神龙计算平台。第三代马上就会开放给客户,目前处于邀测过程中。

高性能背后的自研技术:神龙、盘古 2.0,物理网络的完美结合
阿里云是第一个能够把 RDMA 真正用在云上的云厂商,这是因为要解决 RDMA 的规模化问题,存在着大量的挑战。为了享受 RDMA 的技术红利,则必须要在软硬件以及架构上进行大量适配,才能够保证它能够大规模环境下稳定运行。
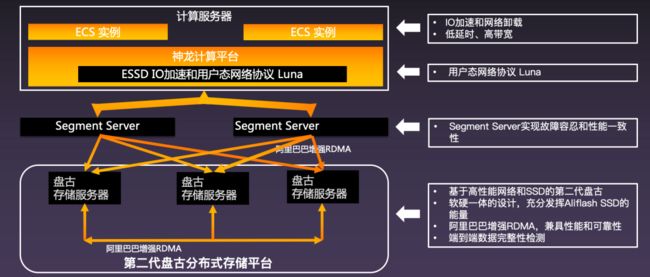
高性能背后的自研技术:玄机大脑的性能调度
在高性能的背后,也需要有强大的调度系统,通过玄机大脑和达摩院进行数据化分析,进行大规模调度,让购买小规格实例的客户也能享受到稳定的服务,甚至超出基线的性能。
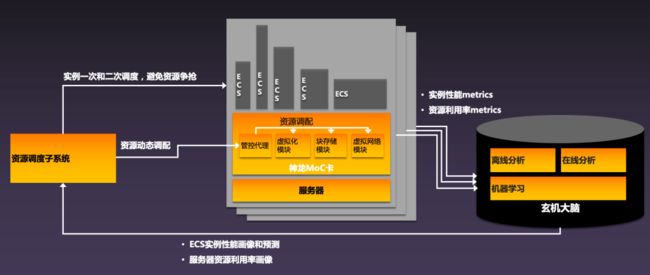
全球最极端场景对性能、稳定性的打磨
举一个极端场景的例子,去年双 11 中阿里巴巴的全部业务都已经上云了,峰值会到达无法想象的量级。在平时演练中,会毫无预兆的人为制造各种问题,例如断电、交换机故障、系统故障等场景,弹性计算团队需要在最短的时间内解决出现的问题,这样的考验对于稳定性的打磨是世界独一无二的。

服务商:云上安全感到效率幸福感
除了上述谈到的能力之外,用户上云之后还需要交付、部署、配置、运维的服务。就像是开车一样,出了性能好,更需要这种自动驾驶、定速巡航、精准操控等能力辅助。

服务商:集群复杂度和规模变化,对交付、部署、配置、运维效率要求产生质的变化
上云企业的大小规模不一样,企业规模小的时候,使用的资源数量非常少,自动化要求、管理复杂度、运用复杂度都会很低。在规模变大之后,企业会划分多个部门,具有多个服务和应用,甚至横跨多个地域。海量的集群复杂度、交付复杂度、服务器管理配置的复杂度都会提升,需求就会有质的变化。
服务商:部署&运维自动化编排,上云用云自动化驾驶
在云上,为了应对以上挑战,提供了两套配套方案,部署集+ROS 资源编排,和云助手+OOS 运维编排,分别解决规模化、自动化部署配置的能力,还有自动化运维的能力,结合稳定的计算实例、时域和空间域的弹性,以及原子 API 和透明监控事件,进而实现了云上完整弹性。
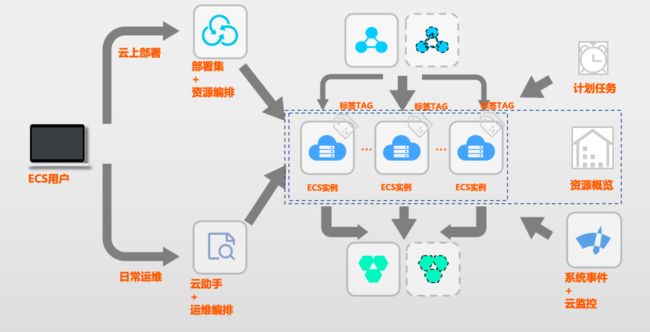
ROS:用部署编排自动化,轻松交付单元化集群
举个例子,2020 年 2 月疫情期间,钉钉使用 ROS 进行大规模多集群扩容。保障扩容的顺利完成,首先要有资源扩容,其次要有空间进行扩容,并且还走向海外,需要在海外为其扩容。集群扩容规模非常大,需要大量的时间,所以阿里云通过 ROS 帮助钉钉进行集群扩容,效率提升了 100 倍。而应对如此快速增长的 DAU,背后的弹性能力、快速部署能力、自动化能力都缺一不可。
OOS:运维编排自动化,云上轻松实现大规模集群高效发布和运维
这里的例子是一个 1.5 亿客户的大型 App 后端大规模集群发布运维编排,通过 OOS 编排模板去自动刷新资源,帮助其将单次完整线上发布时间从 150 分钟缩短到 10 分钟,并且不需要人工干预和 0 误操作。使得发布频率从每周一次提升到了每天一次,真正地做到了基础设施级别的深度持续发布,使得业务创新效率大幅度提升。
规模&进化:宝剑锋从磨砺出
如下图所示的曲线表明规模很重要,规模变大之后,单台服务器的稳定性、弹性、性能大大提升,研发成本也会急剧下降,而阿里云背后强大的技术团队,才让 ECS 有了极致的体验。

弹性计算和阿里云同一年诞生,如今在规模方面已经成为中国乃至亚太的第一,世界第三。弹性计算团队从创建开始,与客户一起成长了 11 年的时间。
小结:规模化实践驱动的云计算的优势会不断扩大
大规模实践锻造而成的弹性计算,驱动着云计算市场不断地发展壮大,同时规模化实践驱动的云计算由于其优势,规模也在不断扩大。
而所有这些竞争力都是构建不同行业的国内外大客户、严苛的云产品内部客户、庞大的集团内部客户的大规模需求驱动之上;构建在阿里云与集团数据和技术积累的肩膀之上;构建在弹性计算这十年中训练出来的强大技术团队,以及在这十年间不断涌现的技术创新之上。
演讲者简介:蒋林泉是阿里巴巴集团研究员,阿里云弹性计算负责人。过去几年他带领团队,在大规模客户场景的驱动下,对平台技术进行架构升级,让 ECS 的整体产品弹性、性能、稳定性以及功能体验都突飞猛进,弹性计算产品体系在业界具备了很强的竞争力。在负责弹性计算之前,他还曾经担任过阿里云平台架构师,阿里云专有云总架构师,是云计算领域最优秀的架构师之一。
【END】


今日福利
遇见大咖
由 CSDN 全新专为技术人打造的高端对话栏目《大咖来了》来啦!
CSDN 创始人&董事长、极客帮创投创始合伙人蒋涛携手京东集团技术副总裁、IEEE Fellow、京东人工智能研究院常务副院长、深度学习及语音和语言实验室负责人何晓冬,来也科技 CTO 胡一川,共话中国 AI 应用元年来了,开发者及企业的路径及发展方向!
点击阅读原文,直达报名。