堆排序(HeapSort)是最常用的排序算法之一。这种排序算法同时具有插入排序和归并排序的优点。与插入排序一样,具有空间原址性,即任何时候都只需要常数个额外的空间储存临时数据(对此,请大家回想一下归并排序,随着问题规模的越大,需要的额外空间就越大,在解决大型问题时,这是不可接受的缺点)。与归并排序一样,具有 \(O(n*lgn)\) 的时间复杂度。
其实一句话总结,堆排序具有 \(O(1)\) 的空间复杂度,具有 \(O(n*lgn)\) 的时间复杂度。
同时,在这里需要强调一点,此文所说的堆是一种数据结构,其类似于我们上一篇文章所说的树,在一些高级语言中,例如 Java 中,“堆”是一种“垃圾收集存储机制”,这仅仅是因为 Java 的 “垃圾收集存储机制” 最早的数据结构采用的是“堆”。因为这个系列是介绍算法与数据结构的,所以此系列后续提到的所有“堆”,都是只一种数据结构,希望读者在自行了解相关知识时,注意区分。
此文堆排序的完整代码可以在我的github上查看。
堆
如下图所示,(二叉)堆可以被理解为一个完全二叉树:
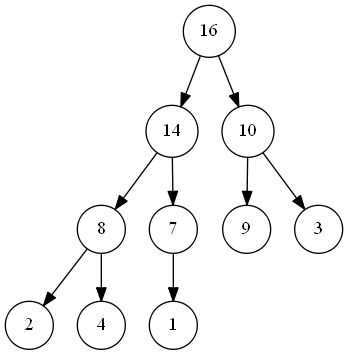
通常情况下,我们采用数组来存储(虽然我们也可以采用上一篇文章中提到的树来实现,但这必然会带来额外的复杂度。虽然我们采用数组实现,但在理解时请将其视为树,查看注释)。

除了最底层外,该树是完全充满的,而且最底层是从左往右依次填充。表示堆的数组应该包括两个属性,heap_length 和 heap_size ,其中 heap_length 表示数组总长度,heap_size 表示有效数据个数,同时满足 \(0 \leq heap\_size \leq length\) 。为了方便写代码,我们如下定义:
#define HEAP_LENGTH 20 // 数组长度
int array_to_sort[HEAP_LENGTH + 1] = {HEAP_LENGTH, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10,
20, 19, 18, 17, 16, 15, 14, 13, 12, 11};
我们将 array_to_sort[0] 解释为 heap_size,故 array_to_sort 的实际长度应为 heap_length + 1。这样做的目的其实是为了下文方便,给定一个节点下标 i ,那么他的父节点,左孩子和右孩子节点下标分别为:
#define PARENT(i) (i / 2)
#define LEFT(i) (2 * i)
#define RIGHT(i) (2 * i + 1)
对于大多数的计算机而言,通过将 i 的值算数左移一位,即可在一条指令内计算出 2i,将 i 的值算数右移一位,即可在一条指令内计算出 \(\lfloor \frac{i}{2} \rfloor\) ,不过在现代编译器中,编译器会自动将乘2与除2运算自动优化为移位操作,所以我们在写代码时如果需要乘除法,尽量只进行乘2与除2操作即可。
二叉堆可以分为两种形式:最大堆和最小堆。最小堆是指 除了根节点以外的其他所有节点 i 都需要满足:
即某个节点的值至多与其父节点一样小,因此堆中的最小元素存放在根节点中,并且此树的任意子树中,该子树的中的所有元素的最小值也在子树的根节点。最大堆与此正好相反,是指 除了根节点以外的所有节点 i 都有:
此文中采用的堆排序使用最大堆。
如果我们把堆看成一棵树,则堆中某个节点的高度为该节点到叶节点的最长简单路径上的边的数量,而堆的高度为根节点的高度。
下文的代码中,会涉及到swap函数,我们先将此函数的代码展示一下:
// 交换数组array的 下标i 和 下标j 对应的值
int swap(int *array, int i, int j){
int temp;
temp = array[i];
array[i] = array[j];
array[j] = temp;
return 0;
}
维护堆
首先展示一下代码:
// 递归维护最大堆
int MaintainMaxHeap(int *heap, int i){
int largest;
int left = LEFT(i);
int right = RIGHT(i);
if(left <= heap[0] && heap[left] > heap[i]){
largest = left;
} else{
largest = i;
}
if(right <= heap[0] && heap[right] > heap[largest]){
largest = right;
}
if(largest != i){
swap(heap, largest, i);
MaintainMaxHeap(heap, largest);
}
return 0;
}
此函数的作用是维护最大堆的性质。函数的输入为一个堆(数组)heap,一个下标 i 。调用前,调用者需要保证根节点为 LEAT(i) 和 RIGHT(i) 的二叉树都是最大堆(具体保证方法下文会阐述),此时我们需要将以下标 i 为根节点的子树修改为最大堆(因为heap[i] 可能小于 heap[LEFT(i)] 或 heap[RIGHT(i)] )。
在代码中,我们从 heap[i] 和 heap[LEFT(i)] 、heap[RIGHT(i)] 中选出值最大的数,将其下标储存在 largest 中。若heap[i] 就是最大值,说明此堆已经符合最大堆的特性,无需进行其他操作;反之则将 heap[i] 与 heap[largest] 交换,交换后,下标为largest的节点是原来的 heap[i],以此节点为根节点的子树有可能也会违反最大堆的特性,那么我们此时只需再对此节点调用一次 MaintainMaxHeap() 函数,如此递归下去,完成堆的维护。
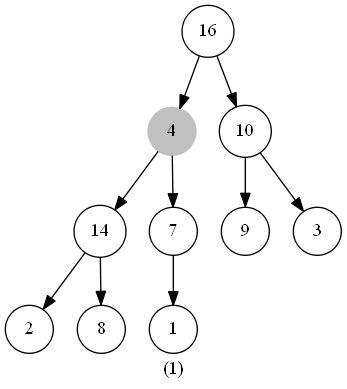
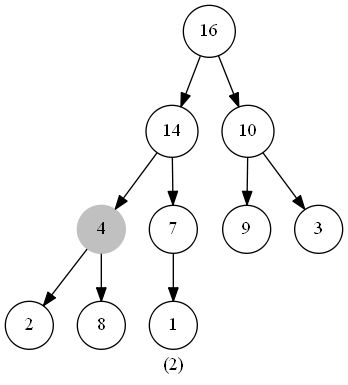
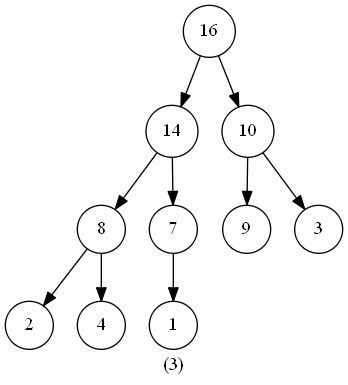
时间复杂度
对于一棵以 i 为根节点,大小为 n 的子树,MaintainMaxHeap() 的时间消耗分为两部分:调整 heap[i],heap[LEFT(i)],heap[RIGHT(i)] ,代价为 \(\Theta(1)\) ;若进行了交换,维护 i 节点的一个子树的时间(时间复杂度一般指最坏情况,所以我们需要假定递归调用会发生)。而每一个孩子的子树大小至多为 \(\frac{2n}{3}\) (取最坏情况,树的底层正好半满,即左子树的深度正好比右子树大1,且左子树是一个完全二叉树),那么,运行一次 MaintainMaxHeap() 的时间消耗为:
由主定理可得,上述递归式的解为 \(T(n)=O(lgn)\) 。
建堆
上文我们提到,在维护堆的性质时,需要保证左右子树均为最大堆,那么最为简单的方法就是让整个堆都变成最大堆,这样,如果替换了一个数,他的左右子树必能保证为一个最大堆。
对此,我们采用自底向上的方法,把一个大小为 n 的数组转换为最大堆。
// 建堆
int BuildHeap(int *heap){
int i;
for(i = PARENT(heap[0]); i >= 1; i--){
MaintainMaxHeap(heap, i);
}
return 0;
}
正确性分析
初始化:在第一次循环以前,\(i=\lfloor \frac{n}{2} \rfloor\) ,而 \(\lfloor \frac{n + 1}{2} \rfloor\) , \(\lfloor \frac{n + 2}{2} \rfloor\) ,... ,\(n\) 都是叶节点,故下标大于 i 的节点都是一个最大堆的根节点。
保持:因为节点 i 的孩子节点下标均大于 i ,故以节点 i 的子节点为根节点的树都是一个最大堆,所以我们可以对节点 i 调用 MaintainMaxHeap() 函数,调用完成后,以节点 i 为根节点的树是一个最大堆,其他下标大于 i 的节点要么不受影响,要么在 MaintainMaxHeap() 函数中,依然保持了最大堆的性质。一次循环结束,i 自减,此时下标大于 i 的节点都是一个最大堆的根节点。
终止:循环结束时,i==0,那么此时下标大于 0 的节点都是一个最大堆的根节点,即整个树已经成为了一个最大堆(heap[0]中储存的是 heap_size,不是堆中的元素,希望各位读者不要忘记了)。
时间复杂度
对于这个过程,我们可以进行简单的估算。每次调用 MaintainMaxHeap() 函数,其时间复杂度不超过 \(O(lgn)\) ,MaintainMaxHeap() 函数一共被调用 \(O(n)\) 次,那么其时间复杂度不超过 \(O(n*lgn)\) 。这个上界虽然正确,但不够精确。我们下面来进行一下进一步的分析(如果读者的数学水平有限的话,可以暂时跳过下面的具体分析)。
首先,对于一个含 \(n\) 个元素的堆,其高度为 \(\lfloor lgn \rfloor\) ,其中高度为 \(h\) 的节点,最多有 \(\lceil \frac{n}{2^{h+1}} \rceil\) 个(请各位读者再仔细看一下上文的关于堆的高度的概念,之前教朋友的时候,很多人是把概念都弄错了,从而觉得是我这个地方算错了2333)
在一个高度为 \(h\) 的节点上运行 MaintainMaxHeap() 的时间复杂度是 \(O(h)\) ,那么 BuildHeap() 的总的时间复杂度为
使用无穷级数或者数列的知识,我们可以得到:
那么最终的时间复杂度为:
没想到吧,我们居然可以在线性时间内,把一个无序数组构造为一个最大堆。
堆排序
前面铺垫了这么多,终于进入正题了,如何进行堆排序?
// 堆排序
int HeapSort(int *heap){
int i;
BuildHeap(heap);
for(i = heap[0]; i >= 1; i--){
swap(heap, 1, heap[0]);
heap[0] -= 1;
MaintainMaxHeap(heap, 1);
}
}
步骤非常简单,首先建立一个最大堆,那么此时数组中的最大元素就在根节点 heap[1] ,此时我们将其与 heap[heap_size] 交换,我们即可将此元素放在正确的位置(最终的排序效果为递增),此时我们将 heap_size 减一,将刚才被选出的最大值从堆中去掉。对于此时的堆,根节点的两个子树依然保持着最大堆的特性,但根节点可能会违背最大堆的特性,此时我们调用 MaintainMaxHeap(heap, 1) 即可将其重新转换为一个最大堆,重复此操作,直到将所有节点均从堆中去掉,那么整个数组也就排序完成了。
时间复杂度
堆排序的第一步是建立一个最大堆,其时间复杂度我们已经在上文分析了,为 \(O(n)\) 。
调用 n 次 MaintainMaxHeap(),每次的时间复杂度为 \(O(lgn)\) 。
那么总的时间复杂度为 \(O(n*lgn)\) 。
不过此时可能就会有好奇的读者问了,在建堆的过程中,需要调用 \(n\) 次,每次复杂度不超过 \(O(lgn)\) ,这不是和堆排序是一样的吗?为什么建堆最后算出来时间复杂度是 \(O(n)\) ,而堆排序就是 \(O(n*lgn)\) 呢?是的,关于堆排序的时间复杂度的计算我只是给了一个感性的估计方法,如果想要非常精确的计算出来的话,也是需要像建堆时那样一步一步计算的,只是计算出来的结果也依然是 \(O(n*lgn)\) ,所以为了偷懒,我就不验算了嘛,毕竟还是挺费时的。
注释
前文我们提到对于堆这种数据结构,虽然我们采用数组实现,但在理解时请将其视为树,其实在计算机中,所有的内容都是 0-1 串,无论你是储存了一张图片,还是一个word文档,他们都是 0-1 串,但为什么会有不同的呈现方式呢?其实就是对其的解释不同。例如在 Windows 操作系统下,文件具有一个属性叫做后缀名,当你修改了其后缀名以后,文件内容其实什么都没有变化,唯一的变化是对其解释不同了。例如对于一个 html 文件,当你把他解释为一个网页时,可以使用浏览器打开,效果就是我们平时所看到的各种网页,当你把他解释为一个文本文件时,就可以使用记事本或者其他编辑器打开,你就能查看他的源代码。Windows 采用后缀名的方式,一是为了方便自动选择合适的软件打开某个文件(当然,你是可以在每次打开时手动选择的,但每次都手动选择,是真的不适合我这种懒人),二是方便用户了解文件内容,比如当用户看到一个后缀名为 png 的文件时,就能知道这大概率是图片(毕竟不能排除有人故意乱改后缀名),后缀名是 zip 时,能知道这是一个压缩包。而在 Linux 下,系统选择打开某个文件的软件时,只查看文件开头的一部分字符串(不同的文件格式具有不同的文件头,或者被称为魔数),据此来判断文件格式,而后缀名的作用就只有我们上文所说的第二个作用了。
结语
本文我们详细介绍了堆排序的相关内容,如果前面几篇文章认真看了的话,理解起来也并不困难,如果只是想要知道堆排序怎么写的话,似乎前面几篇文章页不需要看2333,毕竟主要难度还是在于时间复杂度的计算上。但如果想要深入理解算法这个巨坑的话,建议打好数学基础,在时间复杂度的计算上,数学基础是很重要的。下一篇文章我们将会介绍快速排序。
原文链接:albertcode.info
个人博客:albertcode.info