https://zhuanlan.zhihu.com/p/79714797,其实原理只要搞懂了transformer,这里就很容易懂了。
1.基于decoder
它是一个自回归模型,也就是输出会转变为下一次的输入,主要用来文本生成。
输入编码:词嵌入和位置嵌入向量相加,然后进入masked self-att层,masked主要是遮蔽住右边的单词,只获取到之前生成的单词的注意力
输出:输出之后会再乘以emb矩阵,那么得到的就是长度为vocab的概率向量,为了避免一直选择相同的词,可以从top-40中根据概率随机抽样。
直到生成结束符或者达到了1024个长度。
gpt最多能生成1024个长度,这相较于bert的512有了很大的提升。
2.字节对编码byte pair encoder
https://cloud.tencent.com/developer/article/1089017
https://zhuanlan.zhihu.com/p/136138225
使用介于字符和词之间的一种文本粒度对文本进行切分。计算过程:
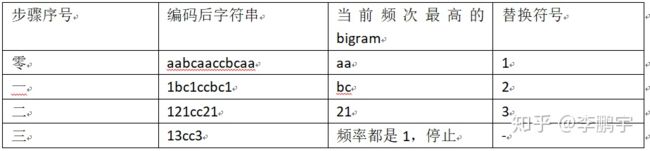
主要目的是为了数据压缩,算法描述为字符串里频率最常见的一对字符被一个没有在这个字符中出现的字符代替的层层迭代过程。
它是一种字符串的编码方式,解码的话,就反向替换可以了。不仅控制了词汇表规模,还极大的缓解了数据稀疏问题,因此可以支撑更好的分布式表示。
https://www.pythonf.cn/read/106117,这里有具体的GTP中BPE的实现,

上面提到的是将未登录词进行拆分,再从字典中找对应,这似乎和BPE关系真不大?
3.下游任务
https://blog.csdn.net/tiantianhuanle/article/details/88597132
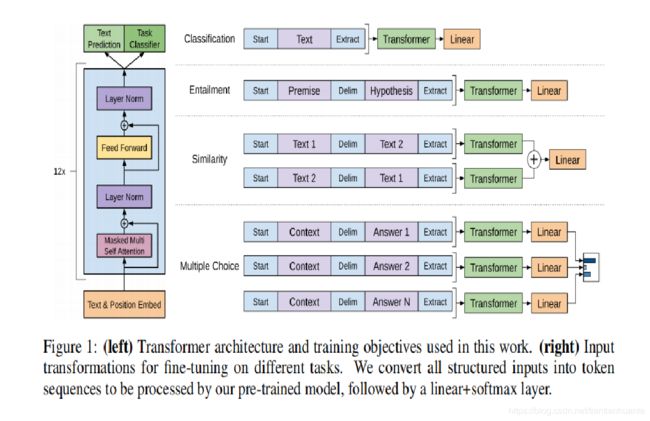
文本分类,关系判断,相似性分析,阅读理解。使用最后的隐藏层来做不同的任务。
//原来也可以做其他的任务。