Scylla:用 C# 重写 Cassandra
想象一下将Cassandra从Java重写为C ++。 Cassandra已经是最可用的NoSQL数据库之一,尽管它在负载下的最大延迟可以在高端运行,因为Java VM需要垃圾回收全局内存(GC),而Cassandra需要压缩其SSTables,两者都在时机不合时宜。
人们试图通过结合Cassandra和Memcached或Redis来解决不一致的延迟问题。 因此,在进行重写时,请为新数据库提供自己的缓存,并允许全扫描操作绕过该缓存以避免刷新它。
现在想象一下,使新数据库中的每个重要I / O操作异步进行,以消除等待和旋转锁。 在担心I / O时,请为数据库提供自己的I / O调度程序和负载平衡器。 最后,介绍每核心分片架构和自动调整。 现在您有了Scylla。
Scylla除了Cassandra之外还具有其他功能:实例化视图,全局和本地二级索引,工作负载优先级以及与DynamoDB兼容的API。 DynamoDB API是CQL(Cassandra查询语言)和与Cassandra兼容的API的补充。
Scylla还缺少DataStax Enterprise (Cassandra的商业版本)中可用的一些功能,例如集成的图形数据库DSE Graph 。 (Janus Graph是在DataStax接管TitanDB时从TitanDB派生的,可以使用Scylla作为其数据存储,因此缺少Scylla图组件并不像它看起来那么重要。)
Scylla拥有单位毫秒的p99延迟,每个节点每秒可进行数百万次操作。 这两个特性意味着需要的节点数(比重要因素要少)要比Cassandra少。 每核心分片架构意味着Scylla可以充分利用多核CPU和多CPU服务器,从而使Scylla可以在Amazon i3和i3en高I / O裸机(36核)实例上良好运行,而Cassandra在较小的4xlarge(八核)实例上表现更好。
Scylla体系结构
Scylla采用了Cassandra的大部分横向扩展架构 。 Cassandra的设计将Amazon Dynamo键值存储的分区和复制与Google Bigtable的日志结构化列系列数据模型结合在一起。 添加节点时,Cassandra和Scylla会线性缩放。
Scylla / Cassandra群集是节点的集合,组织成一个环。 群集可能在多个数据中心(DC)中具有节点。 根据CAP定理,Scyla(如Cassandra)在网络分区过程中倾向于可用性而不是一致性。
键空间是表的集合; 复制因子在键空间级别设置。 表是列和行的集合。 分区是存储在节点上并在节点之间复制的数据子集; 它由分区键表示。
Scylla使用虚拟节点(Vnode)架构。 可以为物理节点分配多个Vnode,而不必是连续的。
Scylla根据用户选择的复制策略自动复制数据。 复制因子应至少为3,以确保存在仲裁,并且如果包含一个副本的节点出现故障,则读取仍可以达到仲裁一致性的数据。
一致性级别确定集群中有多少个副本在被认为成功之前必须确认读取或写入操作。 使用的一些最常见的一致性级别是ANY,QUARUM,ONE,LOCAL_ONE,LOCAL_QUORUM,EACH_QUORUM和ALL。 如果您具有按地理位置分布的数据中心,出于性能原因,可能会使用LOCAL_QUORUM一致性级别进行读取,但可能会丢失远程DC的最新更新。
与Cassandra一样,Sylla使用排序字符串表(SSTable)作为其持久文件格式。 SSTables需要定期压缩以保持性能,而Scylla有四种策略可以做到这一点:大小分层,分层,时间窗口和日期分层(现在不建议使用时间窗口)。 究竟哪种压缩策略将为您带来最佳性能,取决于您的工作量。
在Cassandra中,SSTable压缩在发生时通常会导致延迟增加。 在Scylla中,压缩发生在后台,对延迟的影响要小得多。
除了Scylla集群之外,Scylla部署还可选地包括监视堆栈(用于收集和存储指标的Prometheus,用于处理警报的Alertmanager和用于显示仪表板的Grafana)和Scylla Manager(集群管理)。
Scylla部署选项
您可以在Docker,CentOS,RHEL,Ubuntu或Debian之上运行Scylla。 如果选择在AWS上运行Scylla Enterprise,则可以为所选区域使用预构建的AMI。 这些AMI已针对i3和i3en实例进行了调整,但是如果希望使用其他类型的实例,则可以运行scylla_io_setup 。
您可以在本地或您选择的云中安装Scylla开源或Scylla Enterprise。 您还可以在Scylla Cloud(一个完全托管的数据库即服务)中创建群集,如下面的屏幕快照所示。 目前,Scylla Cloud仅在AWS上运行。
 在Scylla Cloud中创建集群的第一步是命名它,并决定是要使用Cassandra API还是DynamoDB API。 VPC对等
允许另一个AWS虚拟私有云(例如运行您的应用程序的虚拟私有云)有效地使用Scylla VPC。
在Scylla Cloud中创建集群的第一步是命名它,并决定是要使用Cassandra API还是DynamoDB API。 VPC对等
允许另一个AWS虚拟私有云(例如运行您的应用程序的虚拟私有云)有效地使用Scylla VPC。
 IDG
IDG
创建Scylla Cloud群集的第二步是选择实例大小,数据复制因子以及所需的节点数。 如果需要,您以后总是可以添加更多节点。
 创建Scylla Cloud集群的最后一步是启动它。 请注意,估计的费用显示在启动按钮上。
创建Scylla Cloud集群的最后一步是启动它。 请注意,估计的费用显示在启动按钮上。
Scylla案例研究和基准
Scylla已经针对竞争数据库做了许多基准测试。 通常这不是一件容易的事,但是Scylla很好地解释了他们遇到的问题。 此外,Scylla还宣传了一些客户案例研究,其中最令人印象深刻的是康卡斯特。
康卡斯特
在2019年Scylla峰会上,菲利普·齐米奇(Philip Zimich)进行了20分钟的演讲,就康卡斯特为X1 DVR平台从Cassandra过渡到Scylla进行了演讲 。 Comcast可以用78个i3.4xlarge和i3.8xlarge的Scylla节点替换962个m4.2xlarge的Cassandra EC2节点,总共节省了53%。 请注意,由于Java VM中的线程可伸缩性限制,Cassandra无法充分利用i3实例中的所有内核,而Scylla可以使用您提供的尽可能多的内核。
 通过从Cassandra切换到Scylla,从AWS m4实例切换到i3实例,Comcast能够显着减少实现其X1记录平台后端所需的节点数量。 总体节省为53%。
通过从Cassandra切换到Scylla,从AWS m4实例切换到i3实例,Comcast能够显着减少实现其X1记录平台后端所需的节点数量。 总体节省为53%。
Scylla 2.2和Cassandra 3.11
Scylla进行的基准测试将在i3.metal实例上运行的四节点Scylla群集与在i3.4xlarge实例上运行的40节点Cassandra群集进行了比较,这有助于弄清Comcast迁移为何能大幅降低节点和成本。 另请注意,在两年内,四节点群集具有40节点群集同时发生双重故障的概率的十分之一,而实例较小的40节点群集的成本是四节点群集的2.5倍。更大的实例。
 Scylla使用卡桑德拉
Scylla使用卡桑德拉
cassandra-stress
负载,将40节点i3.4xlarge Cassandra群集与一个四节点i3.metal Scylla群集进行了基准测试。 上表显示了配置。
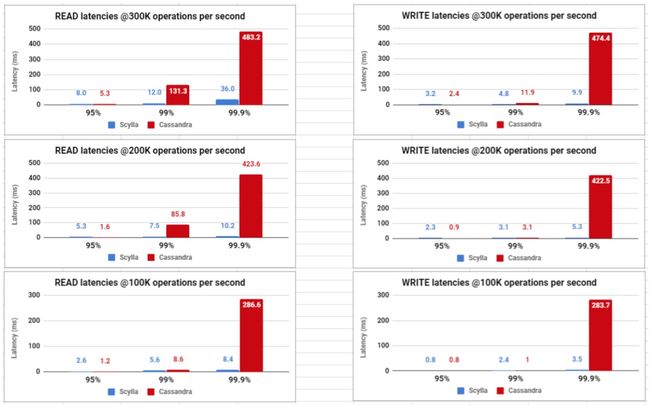 Scylla开源2.2(四个i3节点)与Apache Cassandra 3.11(40 m4节点)的基准测试结果。 SLA规范是10毫秒的写入延迟; 即使在测试的三个负载中最低的情况下,Cassandra仍以99.9%的水平大大超过该值。
Scylla开源2.2(四个i3节点)与Apache Cassandra 3.11(40 m4节点)的基准测试结果。 SLA规范是10毫秒的写入延迟; 即使在测试的三个负载中最低的情况下,Cassandra仍以99.9%的水平大大超过该值。
 Scylla延迟测试(300K OPS):混合的50%写入/读取工作负载(一致性级别= Quorum)。 每个节点都是i3.metal。 CPU负载(顶部)和等待时间(底部)的峰值对应于SSTable压缩(中间)。
Scylla延迟测试(300K OPS):混合的50%写入/读取工作负载(一致性级别= Quorum)。 每个节点都是i3.metal。 CPU负载(顶部)和等待时间(底部)的峰值对应于SSTable压缩(中间)。
Scylla Cloud与Amazon DynamoDB
Scylla针对Amazon DynamoDB对Scylla Cloud进行了基准测试 。 对于涉及“热分区”的特定情况,Sylla优于DynamoDB 20倍。更普遍的是,Sylla Cloud比DynamoDB便宜得多,如下图所示。
 根据Scylla的测试,Scylla Cloud的成本比Amazon DynamoDB低得多,并且还具有出色的性能。
根据Scylla的测试,Scylla Cloud的成本比Amazon DynamoDB低得多,并且还具有出色的性能。
Scylla Cloud与Google Cloud Bigtable
同样, Scylla将Scylla Cloud与Google Cloud Bigtable进行了基准比较 。 同样,Scylla以更低的成本展示了更好的延迟。
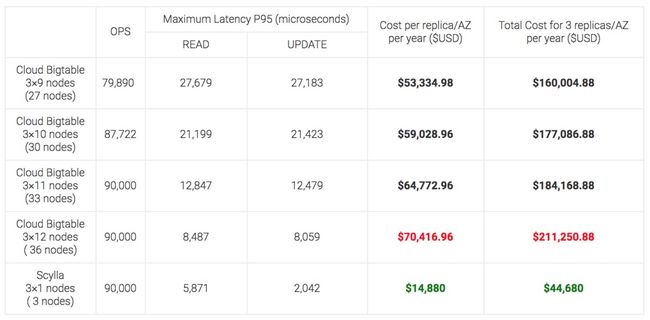
在此基准测试中,Scyla Cloud能够满足90 kOPS的SLA,对于95%的请求(每个区域一个节点)的延迟低于10 ms。 Google Cloud Bigtable每个区域需要12个节点,价格昂贵得多。
学习Scylla
我在iMac上使用Docker来遵循Scylla大学的免费教程。 我没有遇到任何问题,并且Scylla数据库的性能明显优于在相同环境中运行的Cassandra或DataStax Enterprise。
Martins-iMac:~ mheller$ docker run --name scyllaU -d scylladb/scylla:3.0.10
Unable to find image 'scylladb/scylla:3.0.10' locally
3.0.10: Pulling from scylladb/scylla
8ba884070f61: Pull complete
cd4f8f8c60fc: Pull complete
2747a5fb8f41: Pull complete
07583ab71a18: Pull complete
5fcac9cdadf6: Pull complete
c690c84c7597: Pull complete
63ea31381ef0: Pull complete
551655fd09ec: Pull complete
a7efd0f525b1: Pull complete
ba3549fdb516: Pull complete
a6c1be1d6b52: Pull complete
76fef7b03810: Pull complete
26114236ac85: Pull complete
402cb8658fe9: Pull complete
Digest: sha256:e7f861e62f363f9080af9369ef2831039d8aeb1d6a8c3d463824831762d37f26
Status: Downloaded newer image for scylladb/scylla:3.0.10
b08c289fe6e5d55b178bb342391540a942c9bc1aa27206f3e23c718fdb69c23f
Martins-iMac:~ mheller$ docker exec -it scyllaU nodetool status
Datacenter: datacenter1
=======================
Status=Up/Down
|/ State=Normal/Leaving/Joining/Moving
-- Address Load Tokens Owns Host ID Rack
UN 172.17.0.2 458.45 KB 256 ? d1c04d54-4da1-46be-9f2f-e167cd1d6e95 rack1
Note: Non-system keyspaces don't have the same replication settings, effective ownership information is meaningless
Martins-iMac:~ mheller$ docker exec -it scyllaU cqlsh
Connected to at 172.17.0.2:9042.
[cqlsh 5.0.1 | Cassandra 3.0.8 | CQL spec 3.3.1 | Native protocol v4]
Use HELP for help.
cqlsh> CREATE KEYSPACE mykeyspace WITH REPLICATION = { 'class' : 'SimpleStrategy', 'replication_factor' : 1};
cqlsh> use mykeyspace;
cqlsh:mykeyspace> CREATE TABLE users ( user_id int, fname text, lname text, PRIMARY KEY((user_id)));
cqlsh:mykeyspace>
cqlsh:mykeyspace> insert into users(user_id, fname, lname) values (1, 'rick', 'sanchez');
cqlsh:mykeyspace> insert into users(user_id, fname, lname) values (4, 'rust', 'cohle');
cqlsh:mykeyspace> select * from users;
user_id | fname | lname
---------+-------+---------
1 | rick | sanchez
4 | rust | cohle
(2 rows)
cqlsh:mykeyspace>以上课程代表第一堂课。 我继续学习更多的课程并进行了一些测验,但是我发现教程中没有任何偏离之处。
Scylla与众不同
总体而言,Scylla是一个非常出色的NoSQL数据库。 从Java到C ++重写数据库(Cassandra)似乎是一件显而易见的事情,以实现更好的可伸缩性和更一致的延迟,但Scylla拥有其他优化功能,例如自调整。 这是超出我期望的稀有产品。
Scylla是否将满足您应用程序的需求是一个复杂的问题。 我建议遵循我在“如何为您的应用程序选择数据库”中列出的主题:从您的需求开始,然后将其用作筛子,以消除不适用于您的数据库。 如果Scylla成为您的入围者,那么请花时间进行概念验证。
From: https://www.infoworld.com/article/3490383/scylla-review-apache-cassandra-supercharged.html