Prometheus监控系列之一:Prometheus监控入门
完善的监控流程体系是一个公司非常重要的部分。接下来会根据下图进行解释监控流程中的部分
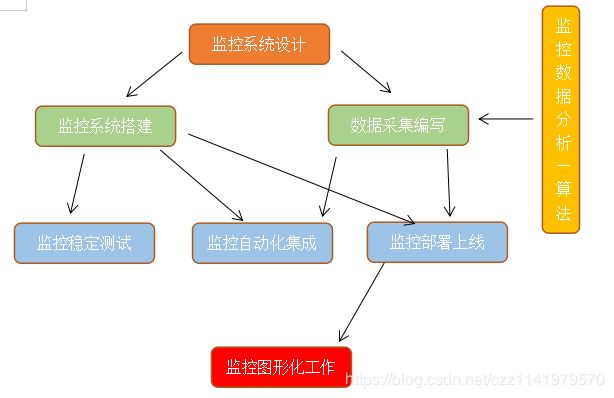
1、监控系统设计(运维架构师):
这部分是由运维架构师进行设计,设计部分主要包括如下内容:
- 评估系统的业务流程、业务种类、架构体系
各个企业的产品不同、业务方向不同、程序代码不同、系统架构更不同,对各个地方细节需要有一定程度的认知。
- 分类出所需的监控大分类
一般可以分为:业务级别监控、系统级别监控、网络监控、程序代码监控、日志监控、用户行为分析监控以及其他种类监控。如:
- 业务监控 包含用户访问QPS、DAU日活、访问状态(http code)、业务接口(登陆,注册,聊天,留言,上传,搜索等)、产品转化率等;
- 系统监控 CPU/内存/磁盘/IO/TCP链接/流量等(zabbix/Prometheus);
- 网络监控 交换机、路由器、防火墙、VPN;
- 日志监控 监控的重头戏(Splunk、ELK),往往单独设计,全部种类的日志都需要采集
- 程序监控 需要与开发配合,代码中嵌入接口,直接获取数据或者特质的日志格式(json)
2、监控系统搭建
- 单点服务器的搭建(Prometheus)
- 单点客户端的部署
- 单点客户端服务器测试
- 采集程序单点部署
- 采集程序批量部署
- 监控服务端HA/Cloud(自己定制)
- 监控数据图形化搭建(Grafana)
- 报警系统测试(Pagerduty)
- 报警规则测试
- 监控+报警联合测试
- 正式上线监控
3、数据采集编写
可选用脚本作为数据采集,如:shell/python/go等。作为监控数据采集,首推shell/python
数据采集的形式分类:
- 一次性采集:使用比较简单的shell ./monitor.sh +crontab的形式 按10秒 30秒 一分钟这样的频率去单词采集
优势:稳定性好,不容易出现各种错误和性能瓶颈,且开发逻辑简单 实现快速
劣势:实现不够智能
- 后台式采集: 采集程序以守护进程运行在Linux后台,持续不断的采集数据;Prometheus exporter例如python/go开发的daemon程序,后台持续不断的采集
优势:数据准确度高,采集密度惊喜,管理方便
劣势:如果开发不够仔细,可能会出现内存泄漏,僵尸进程,性能瓶颈等问题,且开发周期时间长
- 桥接式采集: 本身以后台进程运行,但是采集不能独立,依然跟服务器关联,以桥接方式收集采集数据
4、监控稳定测试
不管是一次性采集,还是后台采集,只要实在Linux上运行的定西都会多多少少对系统产生一定的影响。稳定性测试就是通过一段时间的单点部署观察,对线上有没有任何影响。
5、监控自动化
监控客户端的批量部署,监控服务端的HA再安装,监控项目的修改,监控项目的监控集群变化。这些地方需要大量的人工。这时,自动化引入会很大程度上缩短对监控系统的维护成本。如:Puppet(配置文件部署)、Jenkins(CI持续集成部署)、CMDB(运维自动化的最高资源管理平台和理念)等。
6、监控图形化工作
采集的数据和准备好的监控算法,最终需要一个好的图形展示,才能发挥最好的作用。监控的设计搭建需要大量的技术知识,但是对于一个观察者来说,往往不需要多少技术,只要能看懂图就好(老板想看看当前用户访问量情况,想看看整体CPU高不高)
Prometheus是什么?
Prometheus是最初在SoundCloud上构建的开源系统监视和警报工具包 。自2012年成立以来,许多公司和组织都采用了Prometheus,该项目拥有非常活跃的开发人员和用户社区。现在,它是一个独立的开源项目,并且独立于任何公司进行维护。为了强调这一点并阐明项目的治理结构,Prometheus 于2016年加入了 Cloud Native Computing Foundation,这是继Kubernetes之后的第二个托管项目。
Prometheus优势:
- 基于time series时间序列模型(数字,数学)
时间序列(time series x,y)是一系列有序的数据。通常是等时间间隔的采样数据。
- 基于K/V数据模型
key/value键值 {disk_size: 80},最大的好处是数据格式简单、速度快、易维护开发。
- 采样数据的查询
完全基于数学运算,而不是其他的表达式,并且提供专有的查询输入console。所有的查询都是基于数学运算公式的,例如:(增量(A)+增量(B))/总增量(C)>固定百分比
- 采用http pull/push两种对应的数据采集传输方式
所有的数据采集,都是基本采用HTTP,而且分为pull和push拉和推两种方式去写采集程序,非常方便。
- 开源,大量的社区成品插件
https://prometheus.io, 很多Prometheus社区开发的插件已经非常强大和完善。如果公司对监控要求不是特别高的话,默认的几个成品插件就已经可以够用的了。
- push方法非常灵活
- 本身自带图形调试
Prometheus本身自带了现成的图形成型界面,虽然最终肯定不能和grafana效果相比,但是这种自带图形形成图可以大大帮助运维做测试。
- 最精细的数据采样
大多数市面上的开源监控,采样也就能精确到半分钟或一分钟的程度,但是Prometheus理论上可以达到秒采集,而且可以自行定制频率(不过强大的同时,不太建议细致到这个程度,因为会产生大量的数据)。
Prometheus劣势:
但是还有一些不足,需要加以改进
- 不支持集群化(这个是当前最迫切的需求)
- 被监控集群过大后,本身性能有一定瓶颈(如果有集群,就可以解决这个问题)
- 偶尔发生数据丢失(这个问题在2.0之前会偶尔发生几次,2.0之后已经彻底解决)
- 中文支持不好,中文资料少