TensorFlow加密机器学习框架,为联邦学习加一层保护罩

作者 | Justin Patriquin
译者 | 孙薇
编辑 | 夕颜
出品 | AI科技大本营(ID: rgznai100)
【导读】作为一种无需聚合集中数据便可训练模型的方式,联邦学习(FL)近几年来受到了广泛关注。这种技术最初由谷歌投入生产环境,用于开发、训练及不断改进安卓的预测输入法——GBoard。
传统来说,训练模型需要数据科学家能直接访问集中式数据集。如果某个数据集分散且数据敏感的话,聚合数据并训练将无法完成。举例来说,对于GBoard,聚合数据需要谷歌能直接访问所有用户的每个击键操作,但对于许多人来说,这是对其隐私权的侵犯;同时可能会导致谷歌错误地收集用户密码、信用卡号及用户所输入的其他敏感文本。而联邦学习仅共享模型的更新,而不是训练模型的数据,极大缓解了这一问题。
联邦学习需要模型所有者先将机器学习模型发送给每个数据所有者。数据所有者,即每台手机会使用本地数据运行训练算法的初始步骤,而训练算法则根据输入与预期输出结果来确定对模型的更新方式。这些模型更新会再发回模型所有者方,并进行汇总。当训练算法(例如随机梯度下降算法)达到局部最优权重时,更新汇总结束。

然而,联邦学习并非完整的数据隐私解决方案,它无法确保在更新共享时不泄漏敏感信息。多次针对联邦学习的攻击表明,自客户端更新中习得隐私信息是可以做到的。为了解决敏感数据泄漏问题,我们可以利用差异性隐私及安全聚合来保护更新信息。
通过避免聚合器直接阅读各个客户端的更新内容,安全聚合解决了由于默认信任聚合器而导致的问题,但这样并不能解决最终模型存储时及以后的训练数据泄漏问题,差异性隐私尤其适合解决这类问题。不过,尽管在使用类似TensorFlow隐私时配合差异性隐私及安全聚合是可行的,本文还是着重于安全聚合本身。
TF Encrypted实验

TF Encrypted是一个TensorFlow加密机器学习框架。它看起来,上手感觉都很像TensorFlow,利用了Keras API的易用性,同时通过安全的多方计算和同态加密对加密数据进行训练和预测。TF Encrypted的目的是让用户在并不精通密码学、分布式系统或高性能计算专业知识的情况下,也可以使用隐私保护加持的机器学习随时可用。
目前,此项目已在GitHub开源:https://github.com/tf-encrypted/tf-encrypted
将TensorFlow和TF Encrypted结合起来,无需担心底层细节,我们便可以尝试快速迭代高层方面的实现。TF Encrypted所实现的安全计算,以及TensorFlow使用优化计算图标的能力让该团队得以专注于联邦学习的细节实现,并采用不同的技术进行实验。
计算模型更新
计算模型更新时,每个参与部分需要获得最新的模型,这一点至关重要,以便本地生成的更新对模型是有效的。这意味着每次训练迭代都必须在模型所有者、数据所有者及安全聚合器之间进行同步,而TensorFlow可以运用Keras接口,以及用于管理设备分配的tf.device接口,让这一过程更为简单。
安全聚合
该团队可以用TF Encrypted的安全协议来安全汇总更新内容。当前实现使用了TF Encrypted和额外的密匙共享方法,需要三方(至更多方)实现安全地聚合计算。在安全计算中,同步也很重要,而TensorFlow通过在图形模式下运行,并运用分发引擎按恰当顺序执行操作,使得同步成为可能。
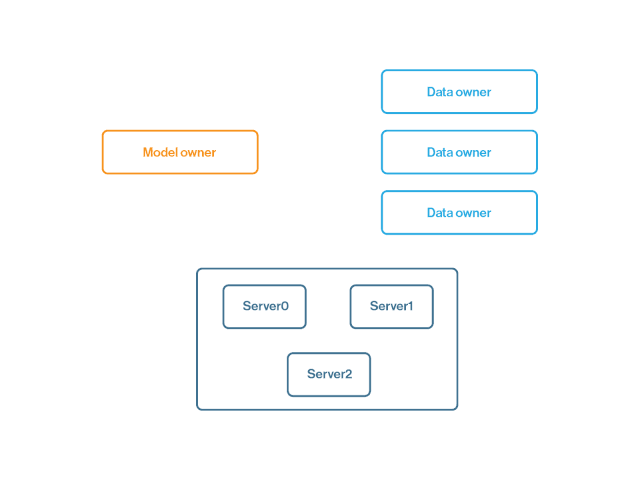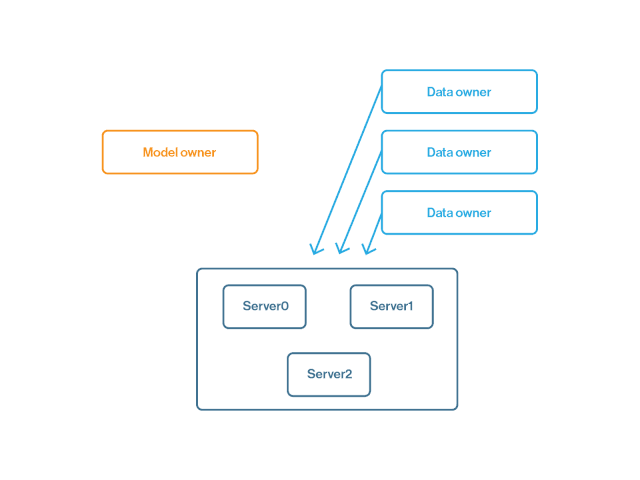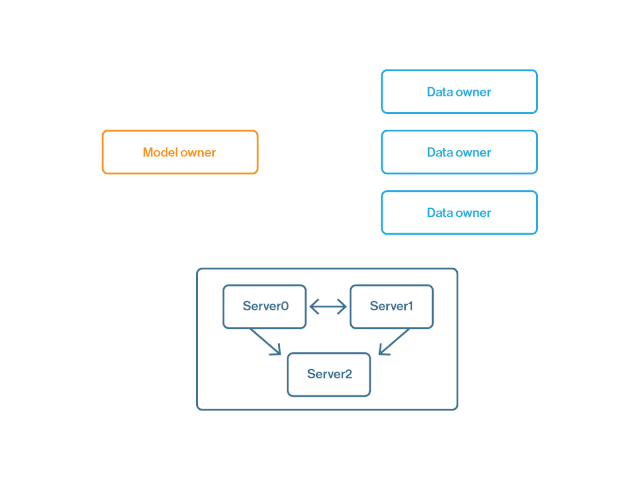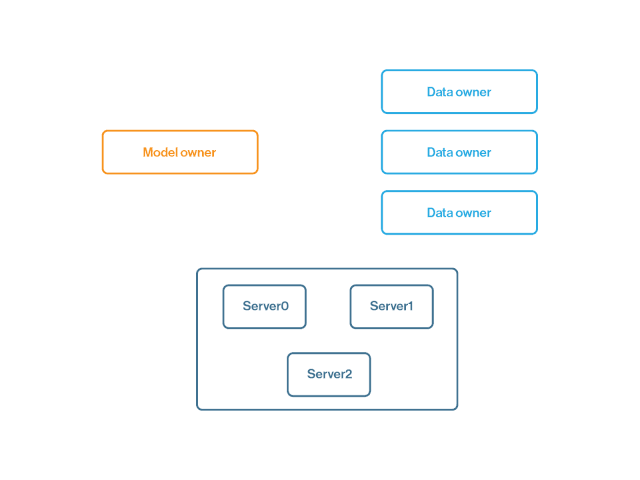
通过安全聚合进行联邦学习会增加一个额外的步骤,将模型更新发送给聚合器,而不是直接返给模型所有者。之后再通过该安全聚合器,将汇总的更新发送给模型所有者。
示例
本示例的主要目的:演示在TensorFlow及TF Encrypted中以高度可定制的方式实现联邦学习。与TensorFlow 1.X相比,最近发布的TensorFlow 2.0让这个实验更加简单。
假设:TF Encrypted已被复制到本地目录中,系统安装了Python 3.5或更高版本,则只需从命令行中运行以下命令,即可运行示例的基础版本。
python examples/federated-learning/main.py
使用help flag可显示用于自定义脚本执行的其他选项。
自定义模型所有者
我们提供了两个基本类——BaseModelOwner和BaseDataOwner,这些类包含了网络通讯的方法,并允许对模型更新的计算和聚合进行易于配置的定制。
class ModelOwner(BaseModelOwner): @classmethod def model_fn(cls, data_owner): x, labels = next(data_owner.dataset)
with tf.GradientTape() as tape: preds = data_owner.model(x) loss = tf.reduce_mean(data_owner.loss(labels, preds, from_logits=True))
return tape.gradient(loss, data_owner.model.trainable_variables)
@classmethod def aggregator_fn(cls, model_gradients, model): aggr_inputs = [ tfe.add_n(inputs) / len(inputs) for inputs in collected_inputs ]
return aggr_inputs
@classmethod def evaluator_fn(cls, model_owner): x, y = next(model_owner.evaluation_dataset)
predictions = model_owner.model(x) loss = tf.reduce_mean(model_owner.loss(y, predictions, from_logits=True))
子类BaseModelOwner扩展基本功能示例
我们使用示例中提供的default_model_fn,secure_mean以及evaluate_classifier对BaseModelOwner进行自定义。为了展示其基础功能之外的可定制性,我们还采用了Reptile元学习算法实现了一些功能,以计算并实现模型更新的安全汇总。
class DataOwner(BaseDataOwner): @from_simulated_dataset def build_data_pipeline(self): """Build data pipeline for validation by model owner.""" def to_tensors(instance): return instance["image"], instance["label"]
def cast(image, label): return tf.cast(image, tf.float32), tf.cast(label, tf.int32)
def normalize(image, label): return image / 255, label
dataset = self.dataset.map(to_tensors) dataset = dataset.map(cast) dataset = dataset.map(normalize) dataset = dataset.batch(batch_size, drop_remainder=True) dataset = dataset.repeat()
return dataset
子类BaseDataOwner指定数据加载方式的示例
同步和算法选择完成自定义之后,可以初始化对象并在机器学习模型上运行.fit方法,以开启训练,并将更新与安全聚合同步。
model_owner = ModelOwner("model-owner", "./data/train.tfrecord",
model, loss, optimizer=tf.keras.optimizers.Adam(learning_rate))
data_owners = []
for i in range(num_data_owners):
do = DataOwner(f"data-owner-{i}", f"./data/train{i}.tfrecord",
model, loss, optimizer=tf.keras.optimizers.Adam(learning_rate)
data_owners.append(do)
model_owner.fit(data_owners, rounds=batches, evaluate_every=10)
在model_owner上调用fit以开始训练
编写联邦学习
该示例利用了网络通讯的两种方式来实现联邦学习:使用tfe.local_computation decorator在本地计算令输入与输出保持加密状态的函数,在函数内部对这些值进行解密。在对模型更新进行前向和反向迭代(forward and backward pass)时使用该方法,使得更新输出(即模型更新)保持加密状态。pin_to_owner是一个辅助函数decorator,通过tf.device调用函数,以确保TensorFlow在正确的设备上运行。在更新聚合及评估模型最终版本时使用。
完整版请查看 https://github.com/tf-encrypted/tf-encrypted/tree/494b95844860424c026fe0a31dd99788aaeee0e9/examples/federated-learning。
未来展望
TF Encrypted及联邦学习将不会止步于这个小示例,而是将TF Encrypted与现有的联邦学习框架结合起来,比如TensorFlow Federated,允许开发者与机器学习工程师利用TF Encrypted来进行安全聚合,也允许开发者和数据科学家将多种不同的技术结合在一起,同时还可以选择使用联邦学习。从示例TensorFlow Federated和Distribution Strategies中也还有很多可以思考的地方,迸发灵感,如何找出安全联邦学习更好的API用法。
原文链接:
https://medium.com/dropoutlabs/federated-learning-with-secure-aggregation-in-tensorflow-95f2f96ebecd
(*本文为AI科技大本营翻译文章,转载请联系微信1092722531)
◆
精彩推荐
◆
推荐阅读
11年艺术学习“转投”数学,他出版首本TensorFlow中文教材,成为蚂蚁金服技术大军一员
清华官宣:前百度总裁张亚勤正式加盟清华大学
小米回应“米家”商标争议;人人 App 回归社交市场;TiDB 2.1.19 发布| 极客头条
迁移学习前沿研究亟需新鲜血液,深度学习理论不能掉链子
详解GPU技术关键参数和应用场景
链版“微信”,27 岁身价达 2.5 亿美元
“微软让我损失了两亿美金!”
太逆天!程序员当总统、拿下《国家地理》全球总冠军、成著名歌手!
区块链重塑人类社群生态

你点的每个“在看”,我都认真当成了AI