大数据学习笔记之Spark(八):Spark机器学习解析(二)
文章目录
- @[toc]
- 第23章协同过滤推荐算法(重点看下,推荐系统)
- 23.1算法思想
- 23.2推荐数据准备
- 23.3相似性度量
- 23.3.1皮尔逊相关系数
- 23.3.2欧式距离
- 23.3.3同现相似度
- 23.4邻域大小
- 23.5基于用户的CF
- 23.6基于物品的CF
- 23.7Spark MLlib算法实现
- 第24章ALS交替最小二乘算法
- 24.1算法思想
- 24.1.1矩阵分解模型
- 24.1.2交替最小二乘法(ALS)
- 24.2Spark MLlib算法实现
- 第25章SVD推荐系统算法
- 25.1传统的SVD算法
- 25.2Funk-SVD算法
- 25.2.1基本思想
- 25.2.2Funk-SVD
- 25.3Bias-SVD
- 25.4SVD++
- 25.5矩阵分解的优缺点
- 第26章随机森林算法
- 26.1算法原理
- 26.2随机森林的生成
- 26.2.1生成步骤
- 26.2.2影响分类效果的参数
- 26.2.3袋外误差率
- 26.3随机采样与完全分裂
- 26.3.1随机采样
- 26.3.2完全分裂
- 26.4随机森林的变体
- 第27章AdaBoost算法
- 27.1集成学习
- 27.1.1定义
- 27.1.2集成学习的条件
- 27.1.3集成学习的分类
- 27.2AdaBoost算法
- 27.2.1AdaBoost算法思想
- 27.2.2AdaBoost算法流程
- 27.2.3AdaBoost算法的一个实例
- 27.3AdaBoost算法的训练误差分析
- 27.3.1AdaBoost的训练误差界
- 27.3.2二类分类问题AdaBoost的训练误差界
- 27.3.3推论
- 27.4AdaBoost算法的数学推导
- 27.4.1前向分布算法
- 27.4.2基于前向分布算法的AdaBoost推导
- 第28章XgBoost算法
- 28.1XGBoost简介
- 28.2监督学习的三要素
- 28.2.1模型
- 28.2.2参数
- 28.2.3目标函数:误差函数+正则化项
- 28.2.4优化算法
- 28.3回归树与树集成
- 28.3.1回归树
- 28.3.2树集成
- 28.4XGBoost的推导过程
- 28.4.1XGBoost的目标函数与泰勒展开
- 28.4.2决策树的复杂度
- 28.4.3目标函数的最小化
- 28.4.4枚举树的结果——贪心法
- 第29章GBDT算法
- 29.1Regression Desicion Tree:回归树
- 29.1.1回归树简介
- 29.1.2回归树的生成
- 29.2Boosting Decision Tree:提升树
- 29.2.1提升树模型
- 29.2.2提升树算法
- 29.2.3提升树实例
- 29.3Gradient Boosting Decision Tree:梯度提升决策树
- 29.3.1GBDT简介
- 29.3.2GBDT算法步骤
文章目录
- @[toc]
- 第23章协同过滤推荐算法(重点看下,推荐系统)
- 23.1算法思想
- 23.2推荐数据准备
- 23.3相似性度量
- 23.3.1皮尔逊相关系数
- 23.3.2欧式距离
- 23.3.3同现相似度
- 23.4邻域大小
- 23.5基于用户的CF
- 23.6基于物品的CF
- 23.7Spark MLlib算法实现
- 第24章ALS交替最小二乘算法
- 24.1算法思想
- 24.1.1矩阵分解模型
- 24.1.2交替最小二乘法(ALS)
- 24.2Spark MLlib算法实现
- 第25章SVD推荐系统算法
- 25.1传统的SVD算法
- 25.2Funk-SVD算法
- 25.2.1基本思想
- 25.2.2Funk-SVD
- 25.3Bias-SVD
- 25.4SVD++
- 25.5矩阵分解的优缺点
- 第26章随机森林算法
- 26.1算法原理
- 26.2随机森林的生成
- 26.2.1生成步骤
- 26.2.2影响分类效果的参数
- 26.2.3袋外误差率
- 26.3随机采样与完全分裂
- 26.3.1随机采样
- 26.3.2完全分裂
- 26.4随机森林的变体
- 第27章AdaBoost算法
- 27.1集成学习
- 27.1.1定义
- 27.1.2集成学习的条件
- 27.1.3集成学习的分类
- 27.2AdaBoost算法
- 27.2.1AdaBoost算法思想
- 27.2.2AdaBoost算法流程
- 27.2.3AdaBoost算法的一个实例
- 27.3AdaBoost算法的训练误差分析
- 27.3.1AdaBoost的训练误差界
- 27.3.2二类分类问题AdaBoost的训练误差界
- 27.3.3推论
- 27.4AdaBoost算法的数学推导
- 27.4.1前向分布算法
- 27.4.2基于前向分布算法的AdaBoost推导
- 第28章XgBoost算法
- 28.1XGBoost简介
- 28.2监督学习的三要素
- 28.2.1模型
- 28.2.2参数
- 28.2.3目标函数:误差函数+正则化项
- 28.2.4优化算法
- 28.3回归树与树集成
- 28.3.1回归树
- 28.3.2树集成
- 28.4XGBoost的推导过程
- 28.4.1XGBoost的目标函数与泰勒展开
- 28.4.2决策树的复杂度
- 28.4.3目标函数的最小化
- 28.4.4枚举树的结果——贪心法
- 第29章GBDT算法
- 29.1Regression Desicion Tree:回归树
- 29.1.1回归树简介
- 29.1.2回归树的生成
- 29.2Boosting Decision Tree:提升树
- 29.2.1提升树模型
- 29.2.2提升树算法
- 29.2.3提升树实例
- 29.3Gradient Boosting Decision Tree:梯度提升决策树
- 29.3.1GBDT简介
- 29.3.2GBDT算法步骤
第23章协同过滤推荐算法(重点看下,推荐系统)

上图中指明了推荐系统的要点:
解决如何从大量信息中找到自己感兴趣的信息
解决如何让自己生产的信息脱颖而出,受到大众的喜爱
这是一个双方的东西,什么样的推荐才是最好的?让我的产品能更快的卖出去,让你能花更少的时间找到自己需要的东西
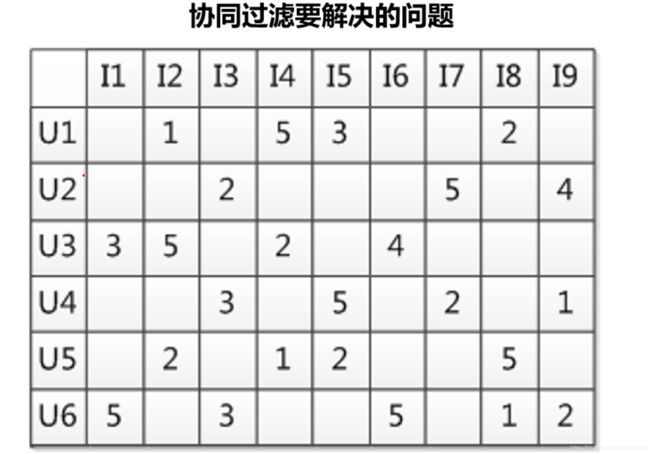
i1-i9 是物理清单
u1-u6是用户
每个用户不可能看到所有物品,他只是对某些物品表达了了他的偏好程度,比如把1当做不喜欢,5当做最喜欢,3当做既不喜欢也喜欢,这个数字代表了用的的偏好度
通过用户的行为都有不同的权重值,然后把他们综合转化成偏好值,这个偏好值是比较权威的,对于事物的方方面面上,提取了一些影响

协同过滤是为了做推荐系统的
如果我想快速得到我想要的数据,如果有一个人他的爱好和你的爱好一样, 甚至和其他人的爱好是相同的,那么对于他见过或者喜欢的物品,你没见过的,你可能也是喜欢的,因为你们的爱好是相同的,这里有一个非常重要的,即你们之间的相似度,第二个,是物品之间的相似度,比如你是一个非常有侠义心肠的人,成天看射雕英雄传,那估计你就喜欢看雪山飞狐。这个就是协同。
过滤什么意思?根据协同带过来的东西,把不需要的东西全部干掉,比如我不喜欢冯小刚的作品,那么就通过过滤把冯小刚的作品过滤掉。
协同过滤其实就是推荐的意思,就是把你最需要的给你

对于相同的物品,加入u1评价过物品,评价的5分,u2评价是5分或者4.5分,那就说明,u1和u2对于事物的认可程度是一样的,这个时候u2可能看了一部电影,然后u1没有看过,那么很大程度上u1也是喜欢这部电影的,因为我们两个口味相同。
同样,如何表达一个物品和另一个物品的相似度呢?我们会找到所有给他们都评过分的这些人,也能通过皮尔逊相关系数来表达他们之间的相关性。如果看过雪山飞狐的,射雕英雄传都有了很高的评分,这两个类型都很近,不能说把射雕英雄传和泰坦尼克号联系起来吗,因为评分肯定有差别。

把每个点都映射到n维数据空间,空间与空间之间的几何距离,就是他们之间的距离,如果距离很近的时候,说明很相近了

用户是非常多的,物品集合来说,物品也是非常多的,不能把所有物品进行比较,也不能把所有的用户进行比较,这个时候需要一个度,这个度多少比较合适呢?一般会通过上面的两种方式。
第一个选择理我最近的几个用户,离我最近的k个用户,我不管你有多少个用户,只挑选key个,第二个,离我距离是k的半径的圆所包含的用户。

通过上图,能够看到,物品a,物品c,用户a和用户c都选择了喜欢,就认为用户a和用户c的相似度非常高,这个时候物品d,用户c选择了喜欢,这个时候就会推荐给用户a。
for每个其他用户w,。。。 这个的意思是当前的这个用户加入比较了30个用户,这个时候取了前10个用户,然后for(n中用户有偏好,而u中用户无偏好的),即这个10个用户中看过的东西,但是我没有看过的,然后对于每个物品i
for(n中用户对i有偏好的)每个其他用户v,对于里面的每个物品,加入有个物品叫a,但是这个a,在十个人里面只有五个人对这个a表达过偏好值,这个时候计算用户u和用户v的相似度s
加入五个人的评价分别是 4 4 4 5 5 ,当前的用户u,对这五个人他们之间的相似度,可能比如0.7 0.8 0.9 1 1 ,那么最终,用户u对于a的偏好值等于(40.7+40.8+40.9+51+5*1)/ 5 , 因为下面的0.7 0.8等就当做权重来用了,权重对于他们a的平分的值,最后得到的平均值,就是通过用户之间的相似度,推测的用户u对于物品a的喜好程度。
这就是基于用户的cf
比如用户a、用户b都对物品a赞赏有加,同时对于物品c也赞赏有加,这个时候有个用户c,对于a赞赏有加,那么我就给用户c推荐物品c,因为他们之间的关联度较强。
这边的for 的算法和基于用户的基本类似,略过
前面都是通过旁边的人活着物品进行推荐的,ALS是另一个推荐的
原来是用户和武平之间的评分矩阵,对于每一个p(用户)都把特征值(classi)分出来了,对于每一个q(物品),把他的特征值(classi)也分出来了,这个特征值其实是不知道的,但是为什么成立了呢?
比如一个人很有侠义心肠,你需要看的是个人英雄主义的,对于射雕英雄传,战狼2 就比较喜欢,他们两个隐藏的是有相关性的,虽然内在的一些属性不知道。所以人的calssi属性乘以物品的classi属性,就得到了相应的评分。

损失函数:预测和真实值之间的差距就叫损失,这个差距就能表现为一个函数,这个函数就能表现为一个损失函数。目的是为了让损失函数越小越好。
ALS优化的损失函数就是刚才的矩阵 真实值-刚才矩阵的相乘,然后所有的相加起来。
可以发现,在最后加上了一个偏移值

为什么加这个偏移值?其实是吉洪诺夫正则化,他认为偏移值,需要加后面的这个东西,来保证整个的损失函数更稳定。
这个函数出来了,要怎么求呢?还是通过函数求导,然后让倒数=0,然后求出ALS的值
如上图,先从关系型数据库中读取用户的业务数据,然后相似度计算完了之后,通过用户的一些偏好,分析一些日志,产生一些用户的偏好数据,然后物品,通过我们的算法(6),和用户一起昌盛一些推荐值(7),最后产生的结果再扔到关系型数据库里面(1)。

第一列是用户id,第二列是物品id,第三列是偏好值,最高是5.0
在spark里面整个推荐是ALS。
还是类似之前的线性回归,屏蔽日志、创建sparkContext、加载数据、训练模型
rating评分,是一个rdd,传入三个参数,用户id,物品id,评分值
23.1算法思想
比如你想看一个电影,但是不知道具体看哪一部,你会怎么做?有两种办法,一种是问问周围兴趣相似的朋友,看看他们最近有什么好的电影推荐。另外一种是看看电影的相似程度,比如都喜欢看僵尸片,那就会找电影名带有僵尸、丧尸之类的电影。
协同过滤算法就是基于上面的思想,主要包含基于用户的协同过滤推荐算法以及基于物品的协同过滤推荐算法。
实现协同过滤,一般需要几个步骤:
1、收集用户偏好。
2、找到相似的用户或者物品。
3、计算推荐。
23.2推荐数据准备
要进行推荐我们需要的数据如下: 用户ID、物品ID、偏好值
偏好值就是用户对物品的喜爱程度,推荐系统所做的事就是根据这些数据为用户推荐他还没有见过的物品,并且猜测这个物品用户喜欢的概率比较大。
用户ID和物品ID一般通过系统的业务数据库就可以获得,偏好值的采集一般会有很多办法,比如评分、投票、转发、保存书签、页面停留时间等等,然后系统根据用户的这些行为流水,采取减噪、归一化、加权等方法综合给出偏好值。一般不同的业务系统给出偏好值的计算方法不一样。
23.3相似性度量
基于用户的推荐和基于物品的推荐都需要找相似,即需要找相似用户以及相似物品。比如一个男生和一个女生是朋友,不能讲该女生穿的衣服推荐给男生。要找相似。那么衡量的指标有哪些?比如皮尔逊相关系数、欧式距离、同现相似度、Cosine相似度、Tanimoto系数等。
23.3.1皮尔逊相关系数
皮尔逊相关系数是介于1到-1之间的数,他衡量两个一一对应的序列之间的线性相关性。也就是两个序列一起增大或者一起减小的可能性。两个序列正相关值就趋近1,否者趋近于0。
数学含义:两个序列协方差与二者方差乘积的比值
如果比较两个人的相似度,那么他们所有共同评价过的物品可以看做两个人的特征序列,这两个特征序列的相似度就可以用皮尔逊相关系数去衡量。物品的相似度比较也是如此。
皮尔逊对于稀疏矩阵表现不好,可以通过引入权重进行优化。
23.3.2欧式距离
这个已经在KMEANS中讲过,同理可以将两个人所有共同评价过的物品看做这个人的特征,将这些特征看做是空间中的点,计算两点之间的距离。
23.3.3同现相似度
物品i和物品j的同相似度公式定义:
其中,分母是喜欢物品i的用户数,而分子则是同时喜欢物品i和物品j的用户数。因此,上述公式可用理解为喜欢物品i的用户有多少比例的用户也喜欢j (和关联规则类似)
但上述的公式存在一个问题,如果物品j是热门物品,有很多人都喜欢,则会导致Wij很大,接近于1。因此会造成任何物品都和热门物品交有很大的相似度。为此我们用如下公式进行修正:
这个格式惩罚了物品j的权重,因此减轻了热门物品和很多物品相似的可能性。(也归一化了[i,j]和[j,i])
23.4邻域大小
有了相似度的比较,那么比较多少个用户或者物品为好呢?一般会有基于固定大小的邻域以及基于阈值的领域。具体的数值一般是通过对模型的评比分数进行调整优化。

23.5基于用户的CF
模型核心算法伪代码表示:
基于该核心算法,完成用户商品矩阵: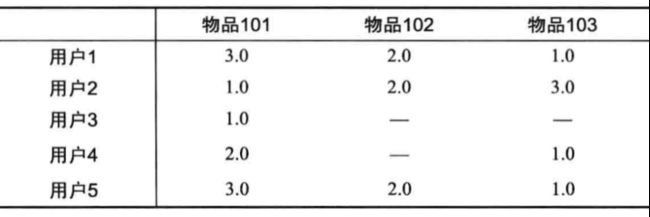
预测用户对于未评分的物品的分值,然后按照降序排序,进行推荐。
23.6基于物品的CF
先计算出物品-物品的相似矩阵:
基于上面的结果:
给用户推送预测偏好值n个最高的物品。
23.7Spark MLlib算法实现
第24章ALS交替最小二乘算法
24.1算法思想
24.1.1矩阵分解模型
在协同过滤推荐算法中,最主要的是产生用户对物品的打分,用户对物品的打分行为可以表示成一个评分矩阵A(mn),表示m个用户对n各物品的打分情况。如下图所示:
其中,A(i,j)表示用户user i对物品item j的打分。但是,用户不会对所有物品打分,图中?表示用户没有打分的情况,所以这个矩阵A很多元素都是空的,我们称其为“缺失值(missing value)”,是一个稀疏矩阵。在推荐系统中,我们希望得到用户对所有物品的打分情况,如果用户没有对一个物品打分,那么就需要预测用户是否会对该物品打分,以及会打多少分。这就是所谓的“矩阵补全(填空)”。
我们从另外一个层面考虑用户对物品的喜爱程序,而不是通过用户的推荐。用户之所以喜欢一个物品,绝大对数是因为这个物品的某些属性和这个用户的属性是一致或者是接近的,比如一个人总是具有爱国情怀或者侠义情怀,那么根据这些推断一定喜欢比如《射雕英雄传》、抗战剧等电视剧,因为这些电视剧所表达的正是侠义和爱国。可以设想用户拥有某些隐含的特征、物品也具有某种隐含的特征,如果这些特征都相似,那么很大程度上用户会喜欢这个物品。
根据上面的假设,我们可以把评分矩阵表示成两个低纬度的矩阵相乘,如下:
我们希望学习到一个P代表user的特征,Q代表item的特征。特征的每一个维度代表一个隐性因子,比如对电影来说,这些隐性因子可能是导演,演员等。当然,这些隐性因子是机器学习到的,具体是什么含义我们不确定。
ALS 的核心就是下面这个假设:打分矩阵A是近似低秩的。换句话说,一个 ![]() 的打分矩阵A 可以用两个小矩阵
的打分矩阵A 可以用两个小矩阵![]() 和
和![]() 的乘积来近似:。这样我们就把整个系统的自由度从
的乘积来近似:。这样我们就把整个系统的自由度从![]()
![]() 一下降到了
一下降到了![]() 。 一个人的喜好映射到了一个低维向量
。 一个人的喜好映射到了一个低维向量![]() ,一个电影的特征变成了纬度相同的向量
,一个电影的特征变成了纬度相同的向量![]() ,那么这个人和这个电影的相似度就可以表述成这两个向量之间的内积
,那么这个人和这个电影的相似度就可以表述成这两个向量之间的内积![]() 。
。
我们把打分理解成相似度,那么“打分矩阵A(m_n)”就可以由“用户喜好特征矩阵U(m_k)”和“产品特征矩阵V(nk)”的乘积![]() 来近似了。这种方法被称为概率矩阵分解算法(probabilistic matrix factorization,PMF)。ALS算法是PMF在数值计算方面的应用。
来近似了。这种方法被称为概率矩阵分解算法(probabilistic matrix factorization,PMF)。ALS算法是PMF在数值计算方面的应用。
24.1.2交替最小二乘法(ALS)
为了使低秩矩阵X和Y尽可能地逼近R,需要最小化下面的平方误差损失函数: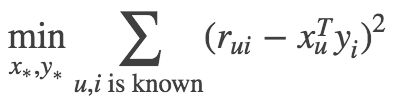
考虑到矩阵的稳定性问题,使用吉洪诺夫正则化Tikhonov regularization,则上式变为:
所以整个矩阵分解模型的损失函数为:
有了损失函数之后,下面就开始谈优化方法了,通常的优化方法分为两种:交叉最小二乘法(alternative least squares)和随机梯度下降法(stochastic gradient descent)。本次使用交叉最小二乘法(ALS)来最优化损失函数。算法的思想就是:我们先随机生成![]() 然后固定它求解
然后固定它求解![]() ,再固定
,再固定![]() 求解,这样交替进行下去,直到取得最优解min©。因为每步迭代都会降低误差,并且误差是有下界的,所以ALS 一定会收敛。但由于问题是非凸的,ALS 并不保证会收敛到全局最优解。但在实际应用中,ALS 对初始点不是很敏感,是不是全局最优解造成的影响并不大。
求解,这样交替进行下去,直到取得最优解min©。因为每步迭代都会降低误差,并且误差是有下界的,所以ALS 一定会收敛。但由于问题是非凸的,ALS 并不保证会收敛到全局最优解。但在实际应用中,ALS 对初始点不是很敏感,是不是全局最优解造成的影响并不大。
算法的执行步骤:
1、先随机生成一个![]() 。一般可以取0值或者全局均值。
。一般可以取0值或者全局均值。
2、固定![]() (即:认为
(即:认为![]() 是已知的常量),来求解
是已知的常量),来求解![]() 。
。
此时,损失函数为:
由于C中只有Vj一个未知变量,因此C的最优化问题转化为最小二乘问题,用最小二乘法求解Vj的最优解:
固定j(j=1,2,…,n),则:C的导数
令 ,得到:
,得到:
即:
令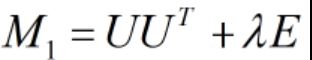 ,
, ,则:
,则:
按照上式依次计算v1,v2,…,vn,从而得到![]() 。
。
3、固定![]() (即:认为
(即:认为![]() 是已知的量),来求解
是已知的量),来求解![]() 。
。
此时,损失函数为:
同理,用步骤2中类似的方法,可以计算ui的值:
令 ,得到:
,得到:
即: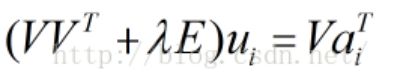
令 ,
,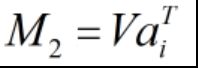 ,则:
,则:
依照上式依次计算u1,u2,…,um,从而得到![]() 。
。
4、循环执行步骤2、3,直到损失函数C的值收敛(或者设置一个迭代次数N,迭代执行步骤2、3 N次后停止)。这样,就得到了C最优解对应的矩阵U、V。
24.2Spark MLlib算法实现
第25章SVD推荐系统算法
25.1传统的SVD算法



25.2Funk-SVD算法
25.2.1基本思想


25.2.2Funk-SVD





![]()
25.3Bias-SVD




25.4SVD++

25.5矩阵分解的优缺点

第26章随机森林算法
26.1算法原理
顾名思义,是用随机的方式建立一个森林,森林里面有很多的决策树组成,随机森林的每一棵决策树之间是没有关联的。在得到森林之后,当有一个新的输入样本进入的时候,就让森林中的每一棵决策树分别进行一下判断,看看这个样本应该属于哪一类(对于分类算法),然后看看哪一类被选择最多,就预测这个样本为那一类。
我们可以这样比喻随机森林算法:每一棵决策树就是一个精通于某一个窄领域的专家(因为我们从M个特征中选择m个让每一棵决策树进行学习),这样在随机森林中就有了很多个精通不同领域的专家,对一个新的问题(新的输入数据),可以用不同的角度去看待它,最终由各个专家,投票得到结果。
下图为随机森林算法的示意图:
随机森林算法有很多优点:
在数据集上表现良好,两个随机性的引入,使得随机森林不容易陷入过拟合
在当前的很多数据集上,相对其他算法有着很大的优势,两个随机性的引入,使得随机森林具有很好的抗噪声能力
它能够处理很高维度(feature很多)的数据,并且不用做特征选择,对数据集的适应能力强:既能处理离散型数据,也能处理连续型数据,数据集无需规范化
可生成一个![]() 矩阵,用于度量样本之间的相似性
矩阵,用于度量样本之间的相似性 :表示样本i和j出现在随机森林中同一个叶子结点的次数,N随机森林中树的颗数
:表示样本i和j出现在随机森林中同一个叶子结点的次数,N随机森林中树的颗数
在创建随机森林的时候,对generlization error使用的是无偏估计
训练速度快,可以得到变量重要性排序(两种:基于OOB误分率的增加量和基于分裂时的GINI下降量
在训练过程中,能够检测到feature间的互相影响
容易做成并行化方法
实现比较简单
26.2随机森林的生成
26.2.1生成步骤
步骤如下:
1)如果训练集大小为NN,对于每棵树而言,随机且有放回地从训练集中抽取NN个训练样本(bootstrap抽样方法),作为该树的训练集;每棵树的训练集都是不同的,但里面包含重复的训练样本
2)如果每个样本的特征维度为MM,指定一个常数mm,且mm
26.2.2影响分类效果的参数
随机森林的分类效果(即错误率)与以下两个因素有关:
1)森林中任意两棵树的相关性:相关性越大,错误率越大
2)森林中每棵树的分类能力:每棵树的分类能力越强,整个森林的错误率越低
减小特征选择个数m,树的相关性和分类能力也会相应的降低;增大m,两者也会随之增大。所以关键问题是如何选择最优的m(或者是范围),这也是随机森林唯一的一个参数。
26.2.3袋外误差率
如何选择最优的特征个数m,要解决这个问题,我们主要依据计算得到的袋外错误率oob error(out-of-bag error)。
随机森林有一个重要的优点就是,没有必要对它进行交叉验证或者用一个独立的测试集来获得误差的一个无偏估计。它可以在内部进行评估,也就是说在生成的过程中就可以对误差建立一个无偏估计。
我们知道,在构建每棵树时,我们对训练集使用了不同的bootstrap sample(随机且有放回地抽取)。所以对于每棵树而言,部分训练实例没有参与这棵树的生成,它们称为第k棵树的oob样本。
袋外错误率(oob error)计算方式如下:
1)对每个样本计算它作为oob样本的树对它的分类情况
2)以简单多数投票作为该样本的分类结果
3)最后用误分个数占样本总数的比率作为随机森林的oob误分率
26.3随机采样与完全分裂
在建立每一棵决策树的过程中,有两点需要注意,分别是采样与完全分裂。
26.3.1随机采样
首先是两个随机采样的过程,random forest对输入的数据要进行行、列的采样。对于行采样,采用有放回的方式,也就是在采样得到的样本集合中,可能有重复的样本。假设输入样本为N个,那么采样的样本也为N个。这样使得在训练的时候,每一棵树的输入样本都不是全部的样本,使得相对不容易出现over-fitting。然后进行列采样,从M个feature中,选择m个(m << M)。
有放回抽样的解释
如果不是有放回的抽样,那么每棵树的训练样本都是不同的,都是没有交集的,这样每棵树都是”有偏的”,都是绝对”片面的”(当然这样说可能不对),也就是说每棵树训练出来都是有很大的差异的;而随机森林最后分类取决于多棵树(弱分类器)的投票表决,这种表决应该是”求同”,因此使用完全不同的训练集来训练每棵树这样对最终分类结果是没有帮助的,这样无异于是”盲人摸象”。
对Bagging的改进
随机森林对Bagging的改进就在于随机采用的不同,即以下两点:
1)Random forest是选与输入样本的数目相同多的次数(可能一个样本会被选取多次,同时也会造成一些样本不会被选取到),而bagging一般选取比输入样本的数目少的样本;
2)bagging是用全部特征来得到分类器,而Random forest是需要从全部特征中选取其中的一部分来训练得到分类器; 一般Random forest效果比bagging效果好。
26.3.2完全分裂
之后就是对采样之后的数据使用完全分裂的方式建立出决策树,这样决策树的某一个叶子节点要么是无法继续分裂的,要么里面的所有样本的都是指向的同一个分类。一般很多的决策树算法都一个重要的步骤 - 剪枝,但是这里不这样干,由于之前的两个随机采样的过程保证了随机性,所以就算不剪枝,也不会出现over-fitting。 按这种算法得到的随机森林中的每一棵都是很弱的,但是大家组合起来就很厉害了。
26.4随机森林的变体
也可以使用SVM、Logistic回归等其他分 类器,习惯上,这些分类器组成的“总分类器”,仍然叫做随机森林。
比如回归问题,图中离散点为臭氧(横轴)和温度(纵轴)的关系,试拟合变化曲线,记原始数据为D,长度为N(即图中有N个离散点)
算法过程为:
1)做100次bootstrap,每次得到的数据Di,Di的长度为N
2)对于每一个Di,使用局部回归(LOESS)拟合一条曲线(图 中灰色线是其中的10条曲线)
3)将这些曲线取平均,即得到红色的最终拟合曲线
4)显然,红色的曲线更加稳定,并且没有过拟合明显减弱
第27章AdaBoost算法
27.1集成学习
27.1.1定义
所谓集成学习(ensemble learning),是指通过构建多个弱学习器,然后结合为一个强学习器来完成分类任务。并相较于弱分类器而言,进一步提升结果的准确率。严格来说,集成学习并不算是一种分类器,而是一种学习器结合的方法。
下图显示了集成学习的整个流程:首次按产生一组“个体学习器”,这些个体学习器可以是同质的(homogeneous)(例如全部是决策树),这一类学习器被称为基学习器(base learner),相应的学习算法称为“基学习算法”;集成也可包含不同类型的个体学习器(例如同时包含决策树和神经网络),这一类学习器被称为“组件学习器”(component learner)。
集成学习通过将多个学习器进行结合,可获得比单一学习器显著优越的泛化性能,它基于这样一种思想:对于一个复杂任务来说,将多个专家的判断进行适当的综合所得出的判断,要比其中任何一个专家单独的判断好,直观一点理解,就是我们平时所说的“三个臭皮匠,顶个诸葛亮”,通过使用多个决策者共同决策一个实例的分类从而提高分类器的泛化能力。
27.1.2集成学习的条件
当然,这种通过集成学习来提高学习器(这里特指分类器)的整体泛化能力也是有条件的:
首先,分类器之间应该具有差异性,即要有“多样性”。很容易理解,如果使用的是同一个分类器,那么集成起来的分类结果是不会有变化的。‘
其次,每个个体分类器的分类精度必须大于0.5,如果p<0.5p<0.5那么随着集成规模的增加,分类精度会下降;但如果是大于0.5的话,那么最后最终分类精度是可以趋于1的。
因此,要获得好的集成,个体学习器应该“好而不同”,即个体学习器要有一定的“准确性”,即学习器不能太坏,并且要有“多样性”,即学习器间具有差异。
27.1.3集成学习的分类
当前,我们可以立足于通过处理数据集生成差异性分类器,即在原有数据集上采用抽样技术获得多个训练数据集来生成多个差异性分类器。根据个体学习器的生成方式,目前集成学习方法大致可分为两大类:第一类是个体学习器之间存在强依赖关系、必须串行生成的序列化方法,这种方法的代表是“Boosting”;第二类是个体学习器间不存在强依赖关系、可同时生成的并行化方法,它的代表是“Bagging”和“Random Forest”
Bagging:通过对原数据进行有放回的抽取,构建出多个样本数据集,然后用这些新的数据集训练多个分类器。因为是有放回的采用,所以一些样本可能会出现多次,而其他样本会被忽略。该方法是通过降低基分类器方法来改善泛化能力,因此Bagging的性能依赖于基分类器的稳定性,如果基分类器是不稳定的,Bagging有助于减低训练数据的随机扰动导致的误差,但是如果基分类器是稳定的,即对数据变化不敏感,那么Bagging方法就得不到性能的提升,甚至会降低。
Boosting:提升方法是一个迭代的过程,通过改变样本分布,使得分类器聚集在那些很难分的样本上,对那些容易错分的数据加强学习,增加错分数据的权重,这样错分的数据再下一轮的迭代就有更大的作用(对错分数据进行惩罚)。
Bagging与Boosting的区别:
二者的主要区别是取样方式不同。Bagging采用均匀取样,而Boosting根据错误率来取样,因此Boosting的分类精度要优于Bagging。Bagging的训练集的选择是随机的,各轮训练集之间相互独立,而Boostlng的各轮训练集的选择与前面各轮的学习结果有关;Bagging的各个预测函数没有权重,而Boosting是有权重的;Bagging的各个预测函数可以并行生成,而Boosting的各个预测函数只能顺序生成。对于象神经网络这样极为耗时的学习方法。Bagging可通过并行训练节省大量时间开销。
bagging是减少variance,而boosting是减少bias。Bagging 是 Bootstrap Aggregating 的简称,意思就是再取样 (Bootstrap) 然后在每个样本上训练出来的模型取平均,所以是降低模型的 variance. Bagging 比如 Random Forest 这种先天并行的算法都有这个效果。Boosting 则是迭代算法,每一次迭代都根据上一次迭代的预测结果对样本进行加权,所以随着迭代不断进行,误差会越来越小,所以模型的 bias 会不断降低。这种算法无法并行。
27.2AdaBoost算法
27.2.1AdaBoost算法思想
对于分类问题而言,给定一个训练样本集,求比较粗糙的分类规则(弱分类器)要比求精确地分类规则(强分类器)容易得多。提升算法就是从弱学习算法出发,反复学习,得到一系列弱分类器(又称为基本分类器),然后组合这些弱分类器,构成一个强分类器。大多数的提升方法都是改变训练数据的概率分布(训练数据的权值分布),针对不同的训练数据分布调用弱学习算法学习一系列弱分类器。
这样,对提升方法来说,有两个问题需要回答:一是在每一轮如果改变训练数据的权值或概率分布;二是如何将弱分类器组合成一个强分类器。对于第一个问题,AdaBoost的做法是,提高那些被前一轮弱分类器错误分类样本的权值,而降低那些被正确分类样本的权值。这样一来,那些没有得到正确分类的数据,由于其权值的加大而受到后一轮的弱分类器的更大关注,于是,分类问题就被一系列的弱分类器“分而治之”。至于第二个问题,即弱分类器的组合,AdaBoost采取加权多数表决的方法。具体地,加大分类误差率小的弱分类器的权值,使其在表决中起较大的作用,减小分类误差率较大的弱分类器的权值,使其在表决中起较小的作用。
AdaboostBoost的算法的框架如下图所示
具体来说,整个AdaBoost算法包括以下三个步骤:
1)初始化训练样本的权值分布。如果有N个样本,则每一个训练样本最开始时都被赋予相同的权值:1/N1/N。
2)训练弱分类器。具体训练过程中,如果某个样本已经被准确地分类,那么在构造下一个训练集中,它的权值就会被降低;相反,如果某个样本点没有被准确地分类,那么它的权值就得到提高。然后,权值更新过的样本被用于训练下一个分类器,整个训练过程如果迭代地进行下去,使得分类器在迭代过程中逐步改进。
3)将各个训练得到的弱分类器组合成强分类器。各个弱分类器的训练过程结束后,加大分类误差率小的弱分类器的权重,使其在最终的分类函数中起着较大的决定作用,而降低分类误差率大的弱分类器的权重,使其在最终的分类函数中起着较小的决定作用。换言之,误差率低的弱分类器在最终分类器中权重较大,否则较小。得到最终分类器。
27.2.2AdaBoost算法流程





27.2.3AdaBoost算法的一个实例







27.3AdaBoost算法的训练误差分析
![]()
27.3.1AdaBoost的训练误差界

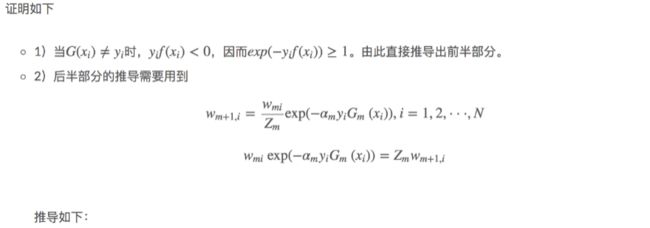

![]()
27.3.2二类分类问题AdaBoost的训练误差界




27.3.3推论

27.4AdaBoost算法的数学推导
![]()
27.4.1前向分布算法
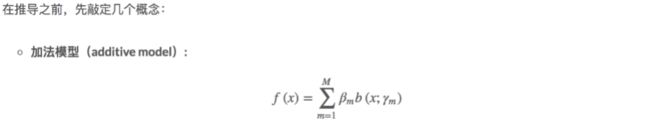

27.4.2基于前向分布算法的AdaBoost推导











第28章XgBoost算法
28.1XGBoost简介
在数据建模中,经常采用Boosting方法通过将成百上千个分类准确率较低的树模型组合起来,成为一个准确率很高的预测模型。这个模型会不断地迭代,每次迭代就生成一颗新的树。但在数据集较复杂的时候,可能需要几千次迭代运算,这将造成巨大的计算瓶颈。
针对这个问题。华盛顿大学的陈天奇博士开发的XGBoost(eXtreme Gradient Boosting)基于C++通过多线程实现了回归树的并行构建,并在原有Gradient Boosting算法基础上加以改进,从而极大地提升了模型训练速度和预测精度。
在Kaggle的希格斯子信号识别竞赛,XGBoost因为出众的效率与较高的预测准确度在比赛论坛中引起了参赛选手的广泛关注,在1700多支队伍的激烈竞争中占有一席之地。随着它在Kaggle社区知名度的提高,最近也有队伍借助XGBoost在比赛中夺得第一。其次,因为它的效果好,计算复杂度不高,也在工业界中有大量的应用。
28.2监督学习的三要素
因为Boosting Tree本身是一种有监督学习算法,要讲Boosting Tree,先从监督学习讲起。在监督学习中有几个逻辑上的重要组成部件,粗略地可以分为:模型、参数、目标函数和优化算法。
28.2.1模型

28.2.2参数

28.2.3目标函数:误差函数+正则化项



28.2.4优化算法
上面三个部分包含了机器学习的主要成分,也是机器学习工具划分模型比较有效的办法。其实这几部分之外,还有一个优化算法,就是给定目标函数之后怎么学的问题。有时候我们往往只知道“优化算法”,而没有仔细考虑目标函数的设计问题,比如常见的例子如决策树的学习算法的每一步去优化基尼系数,然后剪枝,但是没有考虑到后面的目标是什么。而这些启发式优化方法背后往往隐含了一个目标函数,理解了目标函数本身也有利于我们设计相应的学习算法。
28.3回归树与树集成
28.3.1回归树

28.3.2树集成


28.4XGBoost的推导过程
28.4.1XGBoost的目标函数与泰勒展开









28.4.2决策树的复杂度



28.4.3目标函数的最小化





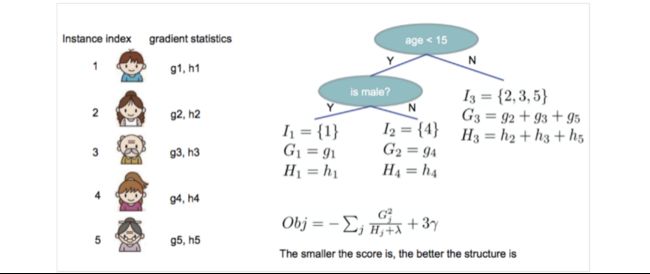
28.4.4枚举树的结果——贪心法



第29章GBDT算法

29.1Regression Desicion Tree:回归树
29.1.1回归树简介

29.1.2回归树的生成



29.2Boosting Decision Tree:提升树
29.2.1提升树模型

29.2.2提升树算法







29.2.3提升树实例

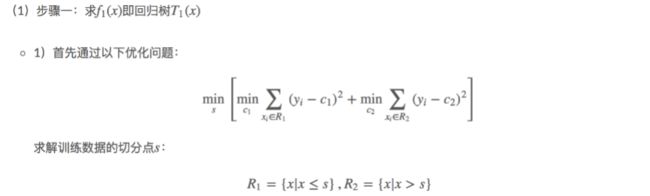






29.3Gradient Boosting Decision Tree:梯度提升决策树
29.3.1GBDT简介



29.3.2GBDT算法步骤

