1、数据如果能够满足其应用的要求,那么他是高质量的。
数据质量涉及许多因素:准确性、完整性、一致性、时效性、可信性、可解释性。
2、数据预处理的主要任务:数据清洗、数据集成、数据规约、数据变换。
二、数据清理:试图填充缺失值,光滑噪声、识别利群点、纠正数据中的不一致。
1、缺失值的处理:
1)忽略元组:缺少类标号时通常这么做。但是忽略的元组其他属性也不能用,即便是有用的。
2)人工填写:该方法很费事费时,数据集很大、缺失值很多时可能行不通。
3)使用一个全局常量填充缺失值:将缺失值的属性用同一个常量替换。(方法简单但不可靠)
4)使用属性的中心度量(均值、中位数)填写缺失值:对于正常的(对称的)数据分布,可以使用均值;对于倾斜数据(非对称)应该使用中位数。
5)使用与给定元组同一类的所有样本的属性均值或中位数: 利用另外一个属性分类数据,计算缺失值的属性值该是多少(均值或中位数)。
6)使用最可能的值填充:利用回归、贝叶斯形式化风阀的基于推理的工具或决策树归纳确定。
3)~6)方法会使数据有变差,但是6)是最流行的策略。另外,缺失值并不意味着数据有错误。
2、噪声数据
噪声:被测量的变量的随机误差或方差。
数据光滑技术:
1)分箱:排序后的数据按等频分箱,
然后:
用箱均值光滑:箱中每个值都被替换为箱中的均值。
用箱中位数光滑:箱中的每一个只都被替换为该箱的中位数。
用箱边界光滑:给定箱中的最大和最小值同样被视为箱边界,箱中每个值都被替换为最接近的边界值。
2)回归:可以用一个函数拟合数据来光滑数据。
3)利群点分析:通过如聚类来检测利群点。
许多数据光滑的方法也用于数据离散化(一种数据变化形式)和数据归约。
数据清理过程:
1)第一步:偏差检测。导致偏差的因素很多,认为输入错误、有意错误、数据退化(过时数据)、编码不一致、设备错误、系统错误。
如何进行偏差检测?
使用任何关于数据性质的知识: 元数据(描述数据的数据)、数据的基本统计描述(均值、中位数、众数、方差、标准差等)、唯一性规则、连续性规则、空值规则。
3、数据集成
数据挖掘经常需要数据集成——合并来自多个数据存储的数据。
(1)实体识别问题: 模式集成和对象匹配可能需要技巧,例如如何让计算机识别customer_id和另外一个数据库的cust_number是同一属性?—— 利用元数据,每个属性的元数据包括名字、含义、数据类型和属性的值的允许范围,以及处理空值的规则。这些元数据可以用来帮助避免模式集成的错误,还有助于变化数据。
(2)冗余和相关分析: 一个属性 如果能由另一个或另一组属性“导出”,则这个属性可能是冗余的;属性或维命名的不一致也可能导致结果数据集的冗余。
解决: 有些冗余可以被相关分析检测到。对于标称数据,使用X²(卡方)检验。对于数值属性,我们使用相关系数和协方差,评估一个属性的值如何随另一个变化。
1)标称数据的X²相关检验
两个属性A,B。A属性构成列,B属性构成行(构成二维表),则(Ai,Bj)表示A的第i个值与B的第j个值构成联合事件。X²的值可计算:
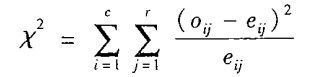
Oij是联合事件
(Ai,Bj)的观测频度,即实际计数。而eij是
(Ai,Bj)的期望频度,由以下公式计算:
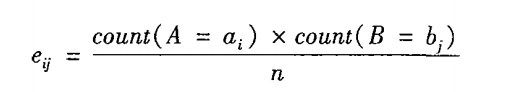
n是数据元组的个数,count表示值ai的个数。
X²统计检验假设A,B是独立的。如果拒绝该假设,则可以说A,B是统计相关的。
2)数值数据的相关系数
通过计算属性A和B的相关系数(又称Pearson积矩系数)估计这两个属性的相关度 r A,B:
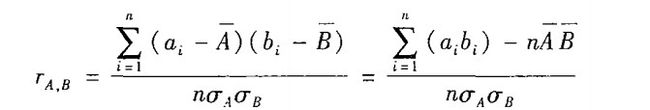
另外,-1<=r A,B <= +1,如果 r A,B大于0,则A,B是正相关的,意味着A值随B值增加而增加。而且值越大相关性就越强。 因此,一个较高的 rA,B值意味着A或B可以作为冗余而被删除。如果值等于0,则A和B是独立的,并且它们之间不存在相关性。如果值小于0,则A,B是负相关,一个值随另一个值减少而增加,这意味着一个属性阻止另一个的出现。
注意:相关性并不蕴涵因果关系,也就是说,如果A和B是相关的,不意味着A导致B或者B导致A。
3)数值数据的协方差:
A,B的均值又称为A,B的期望值:
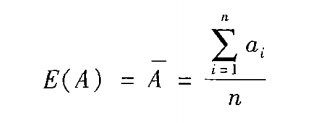
A,B的协方差定义为:
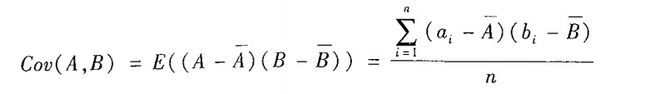
可以发现协方差与相关度的关系:
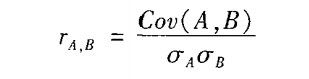
对于两个趋向于一起变化的属性A,B。如果A大于A的期望,则B很可能大于B的期望。因此,A和B的协方差为正;另外,一个属性小于它的期望,而另一个大于它的期望,则A,B协方差为负。
如果A,B是独立的,即不具有相关系,则E(A·B)=E(A)·E(B),则协方差Cov(A,B)=
E(A·B)-
E(A)·E(B)=0;然而,反过来则不成立,某些随机变量(属性)对可能具有协方差0,但不是独立的。
(3)元组重复问题
(4)数据值冲突的检测与处理
例如:一个学校是A-F打分,另一个学校是1-10分打分。很难再两所学校之间制定精确的成绩变换规则,信息交换也变得困难。
4、数据归约:数据归约技术可以用来得到数据集的归约表示,它小得多,但仍接近于保持原始数据的完整性。
(1)数据归约策略包括 维归约、数量归约、数据压缩
1)维归约:减少所考虑的随机变量或属性的个数。方法有 小波变换 和 主成分分析,它们把原数据变换或投影到较小的空间。属性子集选择是一种维归约方法,其中不相关、弱相关或冗余的属性或维被检测和删除。
2)数量归约:用替代的、较小的数据表示形式替换原数据。
3)数据压缩:使用变换,以便得到原数据的归约或“压缩”表示。如果原数据能够从压缩后的数据重构,而不损失信息,该数据归约为 无损的,近似重构原数据称为有损的。
(2)离散小波变换(DWT):一种线性信号处理技术,用于数据向量X时,将它变成不同的数值小波系数向量X‘。
(3)主成分分析:(PCA)又称K-L方法,搜索k个最能代表数据的n维正交向量,其中k<=n。
(4)属性子集选择:通过删除不相关或冗余的属性(维)减少数据量。目标是找出最小属性集,是的数据类的概率分布尽可能地接近使用所有属性得到的原分布。另外,在缩小后的属性集上挖掘能够减少出现在发现模式上的属性数目,使得模式更易于理解。
(5)回归和对数线性模型:参数化数据归约
回归和对数线性模型可以用来近似给定的数据。
对数线性模型:近似离散的多维概率分布。给定n维元组的集合,我们把每个元组看做n维空间的点,对于离散属性集,尅使用对数线性模型,基于维组合的一个较小子集,估计 多维空间中每个点的概率。
(6)直方图
直方图使用分箱来近似数据分布,是一种流行的数据归约形式。
(7)聚类
聚类技术把数据元组看做对象,将对象划分为群或簇,使得在一个簇中的对象相互“想死”,而与其他簇中的对象“相异”。通常,相似性基于距离函数。
(8)抽样
抽样可以作为一种数据归约的技术使用,因为它允许用数据小得多的随机样本表示数据集。
s个样本的无放回简单随机抽样(SRSWOR):从N个元组中抽取s个样本《s
s个样本的有放回简单随机抽样(SRSWR):一个元组被抽取后,又被放回数据集中,以便再次被抽取
簇抽样:数据集放入M个互不相交的簇,可以得到s个簇的简单随机抽样(SRS),s
分层抽样:数据集被划分成互不相交的部分,称为“层”。数据是倾斜时,这样可以帮助确保样本的代表性(eg.按年龄分层)。
5、数据变换与数据离散化
(1)数据变换策略:
1)光滑:去掉数据中的噪声。技术包括分箱、回归、聚类。
2)属性构造(特征构造):由给定的属性构造新的属性并添加到属性集中,以帮助数据挖掘。
3)聚集:对数据惊醒汇总或聚集。
4)规范化:把属性数据按比例缩放,使之落入一个特定的区间。
5)离散化:数值属性(eg。年龄)的原始值用区间标签(eg. 0-10,11-20)或概念标签(youth,adult,senior)替换。
6)由标称数据产生概念分层:将某个属性(eg. street)泛化到较高的概念层(city)。
(2)规范化技术
最小-最大规范化:对原始数据惊醒线性变换。
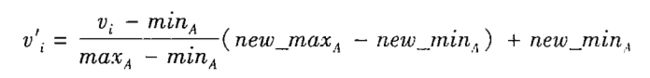
vi映射到区间【new_minA,new_maxA】
z分数(z_score)规范化(零均值规范化):属性
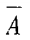 的值基于A的均值(平均值)和标准差规范化:
的值基于A的均值(平均值)和标准差规范化:
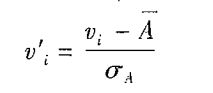
小树定标规范化:通过移动属性A的值的小数点位置进行规范化。
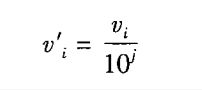 (v’i<1)
(v’i<1)
(3)通过分箱离散化:分箱并不使用类信息,因此事一种非监督的离散化技术,对用户制定的箱个数很敏感,也容易受离群点的影响。
(4)通过直方图分析离散化
之风图分析也是一种非监督离散化技术,因为它不使用类信息。
(5)通过聚类、决策树和相关分析离散化
聚类将数学的值划分成簇或组;为分类生产分类决策树的技术 也可以用于离散化,离散化的决策树方法是监督的,它们使用了类标号(分类)。
(6)标称数据的概念分层产生
标称属性具有 有穷多个不同值,值之间无序。如地理位置,商品类型。
四中变成数据概念分层产生的方法:
1)由用户或专家在模式级显示地说明属性的部分序。(标称属性或维的概念分层涉及一组属性,由用户或专家说明属性的偏序或全序,然后很容易定义概念分层。)
2)通过显式数据分组说明分层结构的一部分。对于小部分数据,显式说明分组。
3)说明属性集但不说明它们的偏序:用户可以说明一个属性集形成概念分层,但并不显式说明它们的偏序,系统可以试图自动产生属性的序,构造有意义的概念分层。
例如: 高层概念的属性一般包含较少的不同值,而较低概念层的属性值较多。(并非所有情况都符合, 如年由365天,月30天,周7天)
4)只说明部分属性集
来自为知笔记(Wiz)