DRBD架构详解(原创)
DRBD概述
Distributed Replicated Block Device(DRBD)是一种基于软件的,无共享,复制的存储解决方案,在服务器之间的对块设备(硬盘,分区,逻辑卷等)进行镜像。DRBD工作在内核 当中的,类似于一种驱动模块。DRBD工作的位置在文件系统的buffer cache和磁盘调度器之间,通过tcp/ip发给另外一台主机到对方的tcp/ip最终发送给对方的drbd,再由对方的drbd存储在本地对应磁盘 上,类似于一个网络RAID-1功能。在高可用(HA)中使用DRBD功能,可以代替使用一个共享盘阵。本地(主节点)与远程主机(备节点)的数据可以保 证实时同步。当本地系统出现故障时,远程主机上还会保留有一份相同的数据,可以继续使用。DRBD的架构如下图
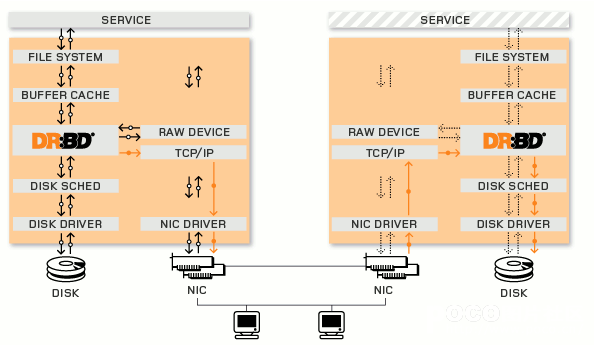
底层设备支持
DRBD需要构建在底层设备之上,然后构建出一个块设备出来。对于用户来说,一个DRBD设备,就像是一块物理的磁盘,可以在上面内创建文件系统。DRBD所支持的底层设备有以下这些类:
1、一个磁盘,或者是磁盘的某一个分区;
2、一个soft raid 设备;
3、一个LVM的逻辑卷;
4、一个EVMS(Enterprise Volume Management System,企业卷管理系统)的卷;
5、其他任何的块设备。
配置简介
全局配置项(global)
基本上我们可以做的也就是配置usage-count是yes还是no了,usage-count参数其实只是为了让linbit公司收集目前drbd的使用情况。当drbd在安装和升级的时候会通过http协议发送信息到linbit公司的服务器上面。
公共配置项(common)
这里的common,指的是drbd所管理的多个资源之间的common。配置项里面主要是配置drbd的所有resource可以设置为相同的参数项,比如protocol,syncer等等。
DRBD设备
DRBD的虚拟块设备。它有一个主设备号为147的设备,默认的它的次要号码编从0开始。在一组主机上,drbd的设备的设备名称为/dev/drbdN,这个N通常和他的次设备号一致。
资源配置项(resource)
resource 项中配置的是drbd所管理的所有资源,包括节点的ip信息,底层存储设备名称,设备大小,meta信息存放方式,drbd对外提供的设备名等等。每一个 resource中都需要配置在每一个节点的信息,而不是单独本节点的信息。并且资源名只能使用纯ascii码而且不能使用空白字符用于表示资源名称。实 际上,在drbd的整个集群中,每一个节点上面的drbd.conf文件需要是完全一致的。
另外,resource还有很多其他的内部配置项:
net:网络配置相关的内容,可以设置是否允许双主节点(allow-two-primaries)等。
startup:启动时候的相关设置,比如设置启动后谁作为primary(或者两者都是primary:become-primary-on both)
syncer: 同步相关的设置。可以设置“重新”同步(re-synchronization)速度(rate)设置,也可以设置是否在线校验节点之间的数据一致性 (verify-alg 检测算法有md5,sha1以及crc32等)。数据校验可能是一个比较重要的事情,在打开在线校验功能后,我们可以通过相关命令(drbdadm verify resource_name)来启动在线校验。在校验过程中,drbd会记录下节点之间不一致的block,但是不会阻塞任何行为,即使是在该不一致的 block上面的io请求。当不一致的block发生后,drbd就需要有re-synchronization动作,而syncer里面设置的rate 项,主要就是用于re-synchronization的时候,因为如果有大量不一致的数据的时候,我们不可能将所有带宽都分配给drbd做re- synchronization,这样会影响对外提提供服务。rate的设置和还需要考虑IO能力的影响。如果我们会有一个千兆网络出口,但是我们的磁盘 IO能力每秒只有50M,那么实际的处理能力就只有50M,一般来说,设置网络IO能力和磁盘IO能力中最小者的30%的带宽给re- synchronization是比较合适的(官方说明)。另外,drbd还提供了一个临时的rate更改命令,可以临时性的更改syncer的rate 值:
drbdsetup /dev/drbd0 syncer -r 100M
这样就临时的设置了re-synchronization的速度为100M。不过在re-synchronization结束之后,你需要通过
drbdadm adjust resource_name
来让drbd按照配置中的rate来工作。
角色、模式和数据同步协议
角色
在drbd构造的集群中,资源具有角色的概念,分别为primary和secondary。
所有设为primary的资源将不受限制进行读写操作。可以创建文件系统,可以使用裸设备,甚至直接io。所有设为secondary的设备中不能挂载,不能读写
模式
drbd也有drbd mode:单主模型(主从),双主模型(drbd只有在8.0以后的版本才支持双主模型)
在单主模型下drbd可以使用任意的文件系统
单在双主模型下只能使用集群文件系统,常用的开源的集群文件系统有:ocfs2和gfs2
数据同步协议
drbd有三种数据同步模式:同步,异步,半同步
异步:指的是当数据写到磁盘上,并且复制的数据已经被放到我们的tcp缓冲区并等待发送以后,就认为写入完成
半同步:指的是数据已经写到磁盘上,并且这些数据已经发送到对方内存缓冲区,对方的tcp已经收到数据,并宣布写入
同步:指的是主节点已写入,从节点磁盘也写入
drbd 的复制模型是靠protocol关键字来定义的:protocol A表示异步;protocol B表示半同步;protocol C表示同步,默认为protocol C。在同步模式下只有主、从节点上两块磁盘同时损害才会导致数据丢失。在半同步模式下只有主节点宕机,同时从节点异常停电才会导致数据丢失。
注意:drbd的主不会监控从的状态所以有可能会造成数据重传
metadata
DRBD将数据的各种信息块保存在一个专用的区域里,这些metadata包括了
a,DRBD设备的大小
b,产生的标识
c,活动日志
d,快速同步的位图
metadata的存储方式有内部和外部两种方式,使用哪种配置都是在资源配置中定义的
内部meta data
内部metadata存放在同一块硬盘或分区的最后的位置上
优点:metadata和数据是紧密联系在一起的,如果硬盘损坏,metadata同样就没有了,同样在恢复的时候,metadata也会一起被恢复回来
缺点:metadata和数据在同一块硬盘上,对于写操作的吞吐量会带来负面的影响,因为应用程序的写请求会触发metadata的更新,这样写操作就会造成两次额外的磁头读写移动。
外部meta data
外部的metadata存放在和数据磁盘分开的独立的块设备上
优点:对于一些写操作可以对一些潜在的行为提供一些改进
缺点:metadata和数据不是联系在一起的,所以如果数据盘出现故障,在更换新盘的时候就需要认为的干预操作来进行现有node对心硬盘的同步了
如果硬盘上有数据,并且硬盘或者分区不支持扩展,或者现有的文件系统不支持shrinking,那就必须使用外部metadata这种方式了。
可以通过下面的命令来计算metadata需要占用的扇区数
split brain脑裂
split brain实际上是指在某种情况下,造成drbd的两个节点断开连接,都以primary的身份来运行。当drbd某primary节点连接对方节点准备 发送信息的时候如果发现对方也是primary状态,那么会立刻自行断开连接,并认定当前已经发生split brain了,这时候他会在系统日志中记录以下信息:“Split-Brain detected,dropping connection!”当发生split brain之后,如果查看连接状态,其中至少会有一个是StandAlone状态,另外一个可能也是StandAlone(如果是同时发现split brain状态),也有可能是WFConnection的状态。
如果我们在配置文件中配置了自动解决split brain(好像linbit不推荐这样做),drbd会自行解决split brain问题,可通过如下策略进行配置。
Discarding modifications made on the “younger” primary。在这种模式下,当网络重新建立连接并且发现了裂脑,DRBD会丢弃最后切换到主节点上的主机所修改的数据。
Discarding modifications made on the “older” primary. 在这种模式下,当网络重新建立连接并且发现了裂脑,DRBD丢弃首先切换到主节点上的主机后所修改的数据。
Discarding modifications on the primary with fewer changes.在这种模式下,当网络重新建立连接并且发现了裂脑,DRBD会比较两台主机之间修改的数据量,并丢弃修改数据量较少的主机上的所有数据。
Graceful recovery from split brain if one host has had no intermediate changes.在这种模式下,如果其中一个主机在脑裂期间并没有数据修改,DRBD会自动重新进行数据同步,并宣布脑裂问题已解决。(这种情况几乎不可 能存在)
注意:自动裂脑自动修复能不能被接受取决于个人应用。考虑 建立一个DRBD的例子库。在“丢弃修改比较少的主节点的修改”兴许对web应用好过数据库应用。与此相反,财务的数据库则是对于任何修改的丢失都是不能 容忍的,这就需要不管在什么情况下都需要手工修复裂脑问题。因此需要在启用裂脑自动修复前考虑你的应用情况。
如果没有配置 split brain自动解决方案,我们可以手动解决。首先我们必须要确定哪一边应该作为解决问题后的primary,一旦确定好这一点,那么我们同时也就确定接受 丢失在split brain之后另外一个节点上面所做的所有数据变更了。当这些确定下来后,我们就可以通过以下操作来恢复了:
1、首先在确定要作为secondary的节点上面切换成secondary并放弃该资源的数据:
drbdadm secondary resource_name
drbdadm — –discard-my-data connect resource_name
2、在要作为primary的节点重新连接secondary(如果这个节点当前的连接状态为WFConnection的话,可以省略)
drbdadm connect resource_name
当作完这些动作之后,从新的primary到secondary的re-synchnorisation会自动开始。
参考至:http://www.drbd.org/users-guide/ch-fundamentals.html
http://www.turbolinux.com.cn/turbo/wiki/doku.php?id=%E7%B3%BB%E7%BB%9F%E7%AE%A1%E7%90%86:drbd%E7%9A%84%E4%BD%BF%E7%94%A8
http://www.cnblogs.com/feisky/archive/2011/12/25/2310346.html
http://www.wenzizone.cn/?p=272
http://www.wenzizone.cn/?p=280
http://blog.chinaunix.net/uid-25492475-id-3255824.html
http://www.drbd.org/users-guide/s-resources.html
http://www.drbd.org/users-guide-8.3/s-split-brain-notification-and-recovery.html
本文原创,转载请注明出处、作者
如有错误,欢迎指正