智能运维(AIOps)系统中的异常检测方案
https://mp.weixin.qq.com/s/okKnaqJVV7bfS1_iUtdIWg
1.概览
异常检测是智能运维(AIOps)系统中一项基础且重要功能,其旨在通过算法自动地发现KPI时间序列数据中的异常波动,为后续的告警、自动止损、根因分析等提供决策依据。在实际场景下,由于异常点数据稀少,异常类型多样以及KPI类型多样,给异常检测带来了很大的挑战。
本文整理了LogicMonitor-AI团队在AIOps决赛暨首届AIOps研讨会中的分享内容,主要介绍了我们在AIOps异常检测竞赛中的算法设计思路和实现细节。

接下来主要分三部分来介绍:
• 首先介绍这次竞赛的背景和需求,在此基础上给出我们方案的设计原则
• 第二部分会详细介绍这次竞赛中使用的算法方案
• 最后探讨方案的不足与改进计划
2.需求分析
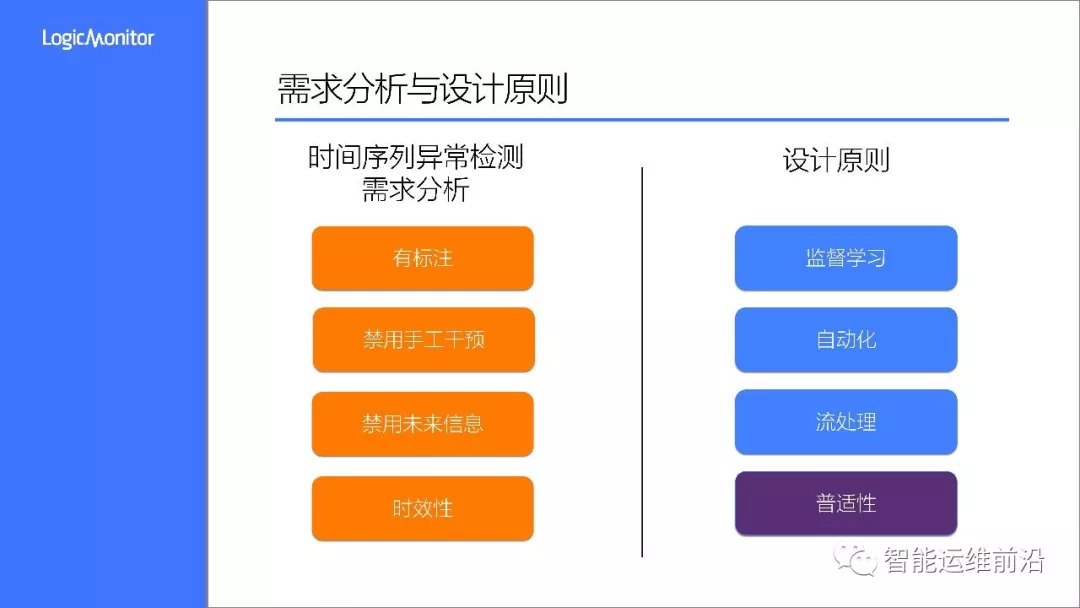
问题描述
在竞赛中,主办方提供了两份数据集,分别用作训练和测试,数据集由若干KPI时间序列组成,这些数据都来源于真实的运维场景。训练数据事先由运维人员手工标注出了异常段,要求根据训练数据生成模型并对测试数据进行异常检测(即对每个数据点标注是否为异常点)。
评估
通过对比测试集上模型的检测结果与真实标注数据,计算F-Score作为算法的评估标准,考察算法的精准率和召回率。通常情况下,运维人员往往只关心异常检测算法能否检测到某一连续异常区间,而非检测到该异常区间的每一个异常点。因此,对于连续的异常段,规定了时效性窗口,只要在窗口内检出异常点,那么该异常段都算作成功检出,否则都判为失败。
考虑到算法的实用性,竞赛还补充了几点规则:
• 禁用手工干预:在模型训练阶段,不允许手动地建立从“KPI曲线ID或KPI曲线计算得出的特征”到“算法和参数”的一一映射。即在模型训练阶段,不允许手动针对一条特定的KPI曲线进行算法的选择和参数的调优。
• 禁用未来信息:不允许参赛算法使用未来点的信息对当前点的异常做出判断
关于这两点规则,放到实际应用场景下很好理解。在实际监控系统中,首先,KPI数据规模是非常大的,几乎不可能针对每条KPI手工地去配置算法、参数以及调优。那么就要求算法足够的稳定和普适。其次,异常检测往往需要实时地对数据点进行判定,自然也是无法利用未来信息来帮助判定。
设计原则
基于以上需求分析,我们确立了以下几条设计原则:
• 监督学习:因为数据本身是带标注的,自然很适合用监督学习来进行训练
• 自动化:为了避免手工干预,我们需要将整个机器学习流程设计为自动化的方式,同时在算法模型选择上尽量避免调参需求高的模型。实际上,在决赛中,我们全程是无法接触到数据以及程序运行过程的,这一点也要求方案本身有较高的鲁棒性。
• 流处理:按流处理的方式对测试数据进行特征提取并实时进行异常检测,避免使用到未来数据。在特征方面,需要选择能够通过流式获取到的特征,避免使用批处理方式提取特征。
在以上三点的基础上,兼顾普适性:
• 框架通用,适用于相同场景下的其他数据集
• 实现简单,流程清晰,易维护
• 性能良好,满足真实生产环境需求
• 算法表现稳定
3.方案详解

我们将异常检测作为二分类问题来处理,按照机器学习流程分为四个阶段:预处理,特征提取,模型训练和最后的异常检测。
技术栈方面,整个方案通过Python来进行实现,用到的主要工具包括:Keras, Numpy,Pandas和Sklearn
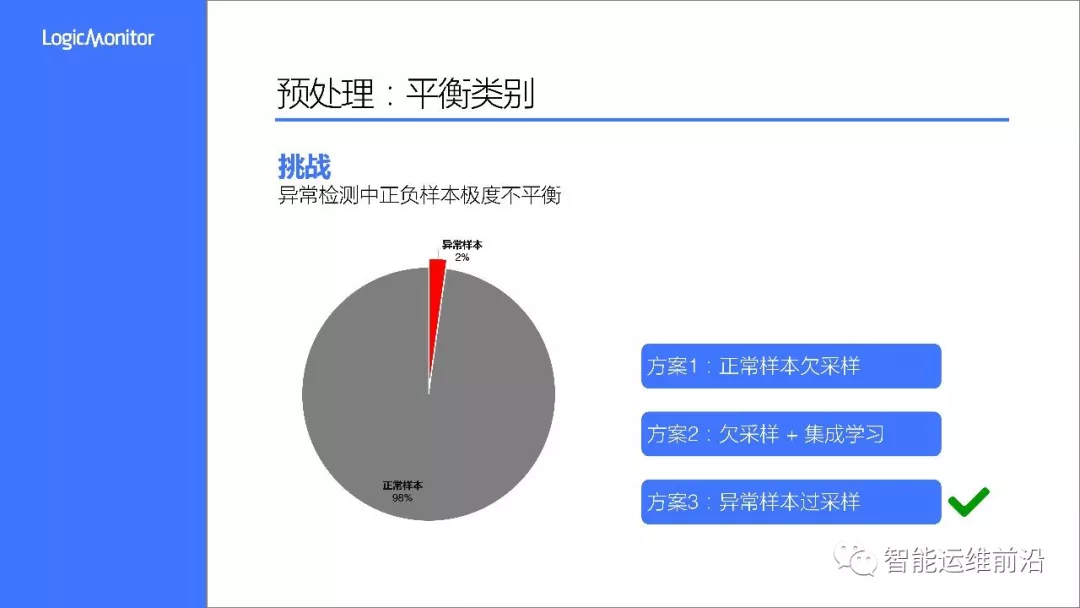
在预处理过程中,我们首先面对的一个挑战是样本极度不平衡,这也是异常检测问题的主要特点。如图所示,在本次竞赛中,异常样本比例只有2%,远远低于正常样本。在实际应用中,这个比例可能会更低。如果直接将样本进行训练,模型会倾向于将所有样本预测为正常样本,那么将无法达到异常检测的目的。
为了解决这个问题,我们尝试了几种方案:
对正常样本进行欠采样以达到正负样本1:1,实验发现这种方案因为丢失了大量的样本信息,模型会出现比较严重的过拟合,泛化性能不佳
欠采样加集成学习。这种方式虽然效果有所提升,但由于每个基分类器的正确率很低,集成后的效果也不是很理想
异常样本过采样以达到正负样本1:1,最后通过阈值进行决策调整。实测下来,这种方式的结果比较理想,成为了我们的最终方案。
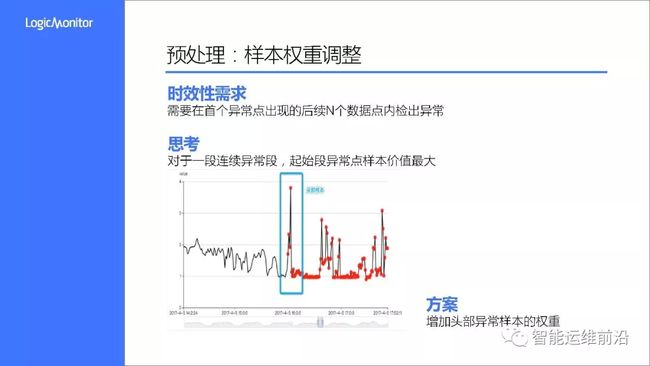
在需求分析中,我们提到了竞赛评估标准中有时效性需求,即对于一段连续异常,我们需要在首个异常点出现的后的时效窗口内检出异常点。这句话怎么理解呢?我们来看上面这幅图,图中红点表示发生了一段连续异常,蓝色框表示时效窗口,基于规则,我们需要在蓝框包含的样本点检出异常,否则后续异常点即使判断正确也会视作失败。
自然地,起始端的异常样本点价值是远远大于后续样本的,因此我们需要增强该类样本的权重以提升其价值。结合前面提到的样本均衡策略,样本权重增强也是通过过采样来实现的。
这是预处理阶段的第二个关键点。
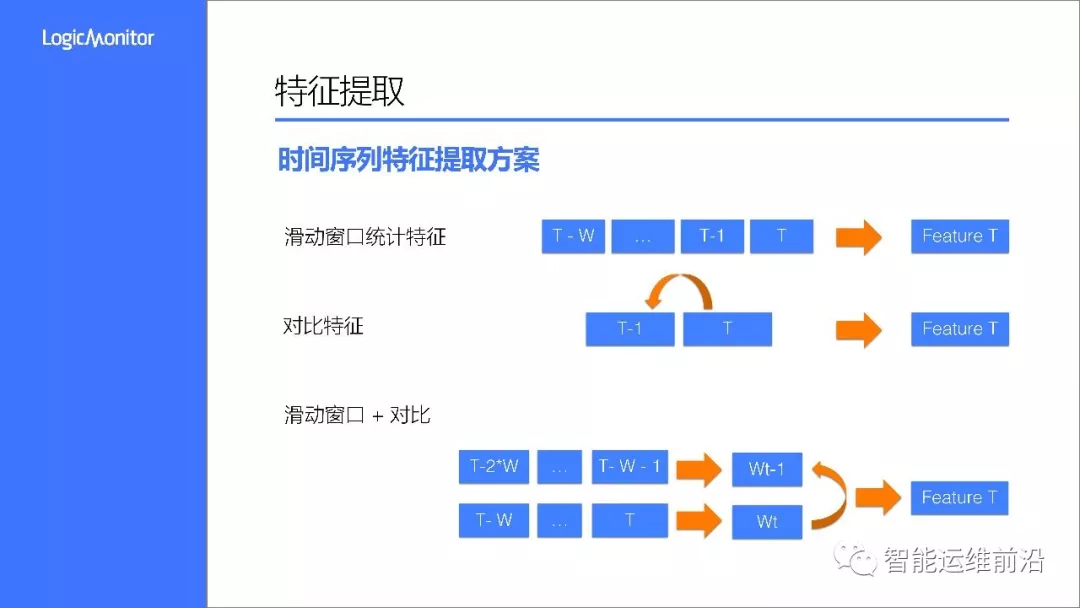
接下来我们来看特征提取,时间序列的重要特点是在时间维度上的相关性,即上下文信息。所以我们不宜直接将单个数据点作为样本来训练,而需要将上下文特征提取出来。
异常往往意味着某个维度上的突变,可能是原始值的突变,也可能是均值、方差等统计量的突变,通过前后对比能够很好的捕捉到这类变化。
考虑到这些特点,我们通过三种方式来获取特征:
第一类,通过滑动窗口,提取该窗口类数据的统计特征
第二类,通过序列前后值的对比,得到对比特征
第三类,结合滑动窗口和对比,得到比统计特征
上图示意了,在T时刻,通过三种方式获取T时刻对应的不同特征。
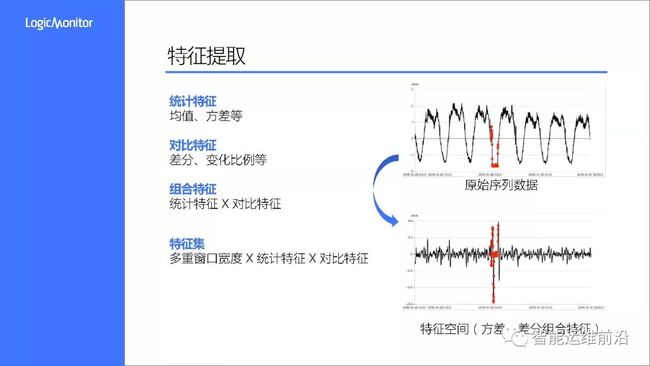
统计特征方面,我们主要使用了均值、方差和分位数等
对比特征方面,使用了差分和变化比例这两种对比方式,差分代表了绝对变化,变化比例则是相对值。需要注意的是,变化比例在原始数据接近0时很容易出现畸变,所以某些场景下不是太好用。
另外我们选择了不同的窗口宽度来进行特征提取,所以总的特征集是窗口宽度、统计特征、对比特征的交叉组合。
上图右侧是特征提取的一个例子,将原始数据转换到方差差分特征空间后,异常样本的辨识度明显提升,这也利于后续模型训练和识别。

关于模型,我们主要考量有两点,第一能够适应较大的样本量,第二是能够自适应地控制过拟合,因为样本不均衡容易带来严重的过拟合,还有一点是希望模型超参数够少,尽量避免人工调参。
我们测试过三种模型:
第一个是IsolationForest,这是一种常用的异常检测模型,但由于它对局部异常不敏感,在这个问题上表现欠佳
第二个是随机森林,作为一种集成模型,总体表现很稳定,泛化能力也不错,实测结果略低于DNN
最终的选择方案是深度学习模型,主要考虑到模型有足够的表达能力,能适应大数据,泛化能力强。实测下来,表现也是非常的好。

这是我们最终使用的深度模型,有两个全连接隐层和一个Sigmoid输出层,两个隐藏神经元数量都是128。通过Dropout和L1正则化控制模型的过拟合,以增强泛化能力。
DNN输出数据点的异常概率,再通过阈值进行二分类。阈值如何确定呢?以F-Score作为评估标准,通过网格搜索的方式确定最优阈值。这里使用阈值的目的主要是为了修正样本不均带来的偏斜。

在普适性上,我们做到了以下几点:
• 通用:在竞赛中,所有KPI的异常检测都能通过一套框架来解决,这套方案也可以很容易地推广到类似的场景和问题,且容易实现和维护。
• 自动:整套流程无需人工介入,算法模型有较高的自适应能力
• 性能:对于普通监控数据(分钟级采样),单个KPI的模型训练时间在3分钟以内(单机,单GPU),流处理情况下单数据点检测时间在毫秒级,基本满足生产环境需求。
• 稳定:在不同数据集上,算法的评估分数非常一致和稳定
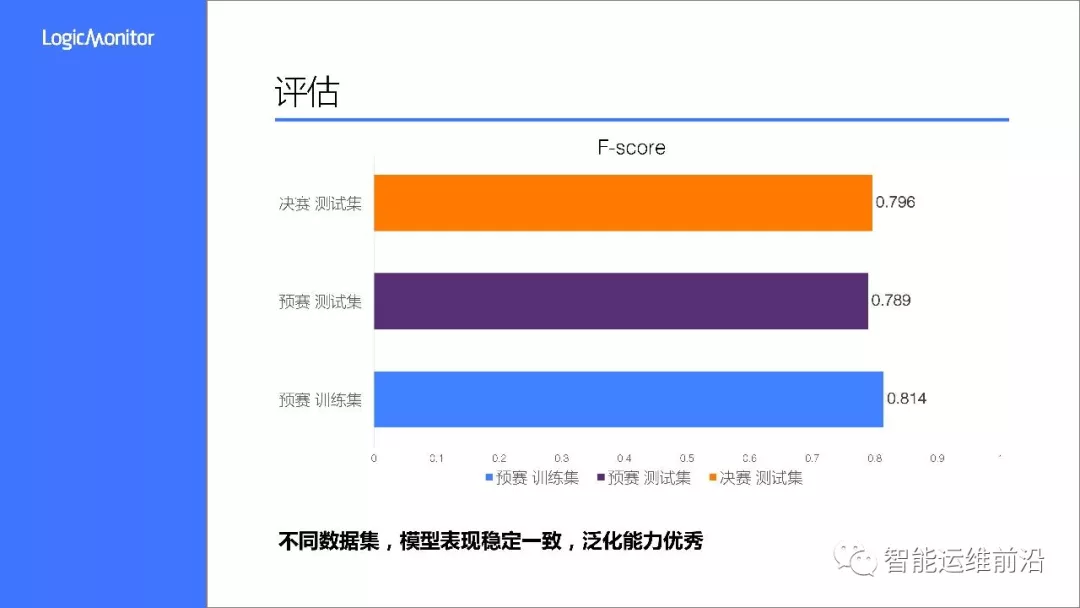
最后来看一下这套算法方案的评估结果,上图列出了算法在预赛训练集、预赛测试集以及决赛测试集上的F-Score得分,在三个不同数据集上,得分稳定在0.8左右,表现非常稳定,有不错的泛化能力。

在测试集标注公开以后,我们对算法的误报、漏报情况做过分析,发现目前还存在这样一些不足:
• 有些异常模式只存在于测试集中,模型无法从训练集中学习出该模式,这类异常容易出现漏报
• 部分异常在局部不明显,只能通过周期同比的方式发现,这类也容易出现漏报
针对这些问题,我们后续计划从以下几点对方案做进一步的优化:
• 引入周期或时间相关的特征,比如周期同比、星期、小时等维度,用于发现这类维度上异常
• 集成无监督模型,以适应异常样本极度稀少或分布不均的情况
• 提供集成业务规则的能力,以支持业务规则下的异常检测
4.总结
本文以AIOps挑战赛为背景,介绍了LogicMonitor-AI团队对异常检测的理解和思考,分享了详细的算法方案。该方案通用性强,高效且算法表现稳定,适用于有标注的KPI异常检测问题。