python常用模块
collections
这个模块实现了特定目标的容器,以提供Python标准内建容器 dict、list、set、tuple 的替代选择。
- Counter:字典的子类,提供了可哈希对象的计数功能
- defaultdict:字典的子类,提供了一个工厂函数,为字典查询提供了默认值
- OrderedDict:字典的子类,保留了他们被添加的顺序
- namedtuple:创建命名元组子类的工厂函数
- deque:类似列表容器,实现了在两端快速添加(append)和弹出(pop)
- ChainMap:类似字典的容器类,将多个映射集合到一个视图里面
更多帮助见: https://www.cnblogs.com/dianel/p/10787693.html
heapq
python标准模块,该模块提供了堆排序算法的实现。堆是二叉树,最大堆中父节点大于或等于两个子节点,最小堆父节点小于或等于两个子节点。可以实现
- 最大N个值
- 最小N个值
- 优先队列
- ......
x=[1,2,3,4,5,5,7,8]
print( hq.nlargest(3,x) )
print( hq.nsmallest(3,x) )re
正则表达式库。
fnmatch
文本通配
numpy
NumpyPython的一种开源的数值计算包,功能非常强大。
numpy里面的对象
- ndarray:解决数组多维度的问题
- NumPy 中包含了一个矩阵库 numpy.matlib,该模块中的函数返回的是一个矩阵,而不是 ndarray 对象
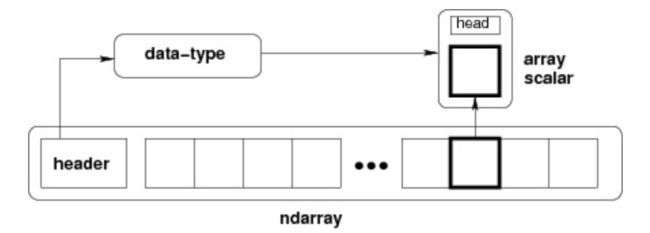
ndarray
ndarray 对象是用于存放同类型元素的多维数组。ndarray 中的每个元素在内存中都有相同存储大小的区域。
ndarray 内部由以下内容组成:
-
一个指向数据(内存或内存映射文件中的一块数据)的指针。
-
数据类型或 dtype,描述在数组中的固定大小值的格子。
-
一个表示数组形状(shape)的元组,表示各维度大小的元组。
-
一个跨度元组(stride),其中的整数指的是为了前进到当前维度下一个元素需要"跨过"的字节数。
ndarray 的内部结构:
属性
| 属性 | 说明 |
|---|---|
| ndarray.ndim | 秩,即轴的数量或维度的数量 |
| ndarray.shape | 数组的维度,对于矩阵,n 行 m 列。shape必须是与元素个数相匹配的 |
| ndarray.size | 数组元素的总个数,相当于 .shape 中 n*m 的值 |
| ndarray.dtype | ndarray 对象的元素类型 |
| ndarray.itemsize | ndarray 对象中每个元素的大小,以字节为单位 |
| ndarray.flags | ndarray 对象的内存信息 |
| ndarray.real | ndarray元素的实部 |
| ndarray.imag | ndarray 元素的虚部 |
| ndarray.data | 包含实际数组元素的缓冲区,由于一般通过数组的索引获取元素,所以通常不需要使用这个属性。 |
创建数组
array函数
numpy.array(object, dtype = None, copy = True, order = None, subok = False, ndmin = 0)参数说明:
| 名称 | 描述 |
|---|---|
| object | 数组或嵌套的数列 |
| dtype | 数组元素的数据类型,可选 |
| copy | 对象是否需要复制,可选 |
| order | 创建数组的样式,C为行方向,F为列方向,A为任意方向(默认) |
| subok | 默认返回一个与基类类型一致的数组 |
| ndmin | 指定生成数组的最小维度 |
#创建一个指定形状(shape)、数据类型(dtype)且未初始化的数组。数值随机
numpy.empty(shape, dtype = float, order = 'C')
#创建指定大小的数组,数组元素以 0 来填充:
numpy.zeros(shape, dtype = float, order = 'C')
#创建指定形状的数组,数组元素以 1 来填充:
numpy.ones(shape, dtype = None, order = 'C')
从已有的数组创建数组
numpy.asarray(a, dtype = None, order = None)
#接受 buffer 输入参数,以流的形式读入转化成 ndarray 对象。
numpy.frombuffer(buffer, dtype = float, count = -1, offset = 0)从数值范围创建数组
#创建数值范围并返回 ndarray 对象
numpy.arange(start, stop, step, dtype)
#创建一个一维数组,数组是一个等差数列构成的
np.linspace(start, stop, num=50, endpoint=True, retstep=False, dtype=None)
#创建一个于等比数列
np.logspace(start, stop, num=50, endpoint=True, base=10.0, dtype=None)切片和索引
#通过冒号分隔切片参数 start:stop:step 来进行切片操作
a[start:stop:step]
#整数数组索引。0,0;1,1;2,0;
x[[0,1,2], [0,1,0]]
#布尔索引
x[x > 5]
a[~np.isnan(a)]
a[np.iscomplex(a)]
#花式索引,利用整数数组进行索引。
x[[4,2,1,7]]
更多帮助见:
https://www.runoob.com/numpy/numpy-ndarray-object.html
https://www.numpy.org.cn/reference/
pandas
pandas是基于NumPy数组构建的,使数据预处理、清洗、分析工作变得更快更简单。pandas是专门为处理表格和混杂数据设计的,而NumPy更适合处理统一的数值数组数据。
使用下面格式约定,引入pandas包:
import pandas as pd
pandas有两个主要数据结构:Series和DataFrame。
Series
Series是一种类似于一维数组的对象,它由一组数据(各种NumPy数据类型)以及一组与之相关的数据标签(即索引)组成,即index和values两部分,可以通过索引的方式选取Series中的单个或一组值。
Series类型的操作
Series类型索引、切片、运算的操作类似于ndarray,同样的类似Python字典类型的操作,包括保留字in操作、使用.get()方法。
Series和ndarray之间的主要区别在于Series之间的操作会根据索引自动对齐数据。
DataFrame
DataFrame是一个表格型的数据类型,每列值类型可以不同,是最常用的pandas对象。DataFrame既有行索引也有列索引,它可以被看做由Series组成的字典(共用同一个索引)。DataFrame中的数据是以一个或多个二维块存放的(而不是列表、字典或别的一维数据结构)。
更多见 : https://www.jianshu.com/p/840ba135df30
https://www.pypandas.cn/
广播: https://blog.csdn.net/lanchunhui/article/details/50158975?utm_medium=distribute.pc_relevant.none-task-blog-BlogCommendFromMachineLearnPai2-2.nonecase&depth_1-utm_source=distribute.pc_relevant.none-task-blog-BlogCommendFromMachineLearnPai2-2.nonecase
https://blog.csdn.net/weixin_41923658/article/details/98195678