“揭开编译器前端的神秘面纱”——龙书附录读书总结
概述
历时10+h左右的时间,终于把课本附录的代码和解读都过了一遍。在这个过程,对编译器前端的认识也从最初的敬畏和稍微的恐惧,再随着逐渐掌握后,变为“不过如此”的感觉。个人觉得这部分掌握的难点应该在于,类和关系的数量繁多,会经常“忘记”而回头去看。因此,对重要的类和方法做一定的总结是非常必要的。下面,就书上的一些重要的类,我稍微总结了下。
词法分析器
这部分的工作是分词,也就是把一串字符串识别为了一个个的词
- Tag:定义了词法单元常量,例如Tag.AND=256
- Token:就是一个int
- Word:把token的int和string绑起来了
- Real:Tag.REAL(就是个数字)+ float
- Lexer:维护Word哈希表(字符串到TAG数值的一个映射),readch和read用来辅助一个一个字符地读,scan函数用于匹配对应词法单元。
copy一波实验写的东西~当然不是仅仅为了凑字数
3.1 Scanner
- 实现decaf语言的词法分析程序(扫描程序)
Ø 扫描程序的输入是源代码文件,输出是token串。
- 测试用例:
\1. class Main {
\2. static void main(){
\3. class Fibonacci f = New Fibonacci();//new a Fibonacci
\4. Print(f.get(ReadInteger()));
\5. }
\6. }
\7. /**
\8. * Fibonacci
\9. */
\10. class Fibonacci {
\11. int get(int i){
\12. if(i<2){
\13. return 1;
\14. }
\15. return get(i-1) + get(i-2);
\16. }
\17. }
- 测试结果:

Ø 需要遵循“最长串匹配原则”。
- 说明:
原本代码在字母关键字匹配上已经满足这个原则,下面对其做一定解读,以关键字的匹配为例,这里首先不断地读取peek并连接成字符串,直到当前peek不是字母或者数字,然后再查哈希表有没有对应的关键字,有则返回给main函数这个token类,无则构造一个标识符的word类塞进哈希表再给main函数。
- 代码:

Ø Token 以键值对 (Kind, Value)的形式表示。
- 说明:输出时一定调整即可

- 结果:
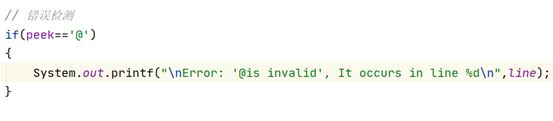
Ø 检测词法错误:给出有意义的错误信息和错误发生的行号。例如字符@并非decaf程序中的合法符号,若这个字符在注释以外出现,则需要提示一个词法错误。
- 说明:
目前实现:在输入流中若有“@”出现,则会打印错误并指明其所在的行。
- 代码:
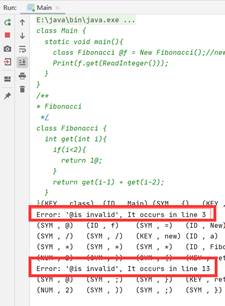
- 测试用例:
\1. class Main {
\2. static void main(){
\3. class Fibonacci @f = New Fibonacci();//new a Fibonacci
\4. Print(f.get(ReadInteger()));
\5. }
\6. }
\7. /**
\8. * Fibonacci
\9. */
\10. class Fibonacci {
\11. int get(int i){
\12. if(i<2){
\13. return 1@;
\14. }
\15. return get(i-1) + get(i-2);
\16. }
\17. }
- 测试结果:
3.1.1 数据结构
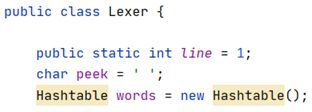
- Hashtable:在词法分析器类Lexer中,我们使用了一个哈希表来存储“token-特征数”的映射。
#散列表(Hash table,也叫哈希表):
是根据关键码值(Key value)而直接进行访问的数据结构。也就是说,它通过把关键码值映射到表中一个位置来访问记录,以加快查找的速度。这个映射函数叫做散列函数,存放记录的数组叫做散列表。
给定表M,存在函数f(key),对任意给定的关键字值key,代入函数后若能得到包含该关键字的记录在表中的地址,则称表M为哈希(Hash)表,函数f(key)为哈希(Hash) 函数。
3.1.2 核心算法
- Main****函数:
核心就是do-while循环,不断调用Lexer的scan函数来得到当前token串的特征码token.tag,由特征码token.tag用switch语句持续输出打上了分类标签的token串(kind,str),直到结束。
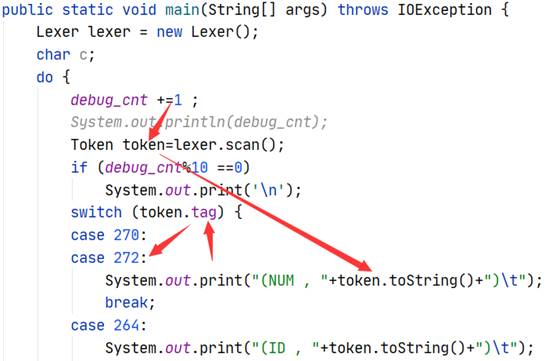
- Lexer****类:
初始化时将预定义的关键字都打上特征码塞入哈希表中,核心是readch函数(读单个字符)和scan函数(token匹配)。
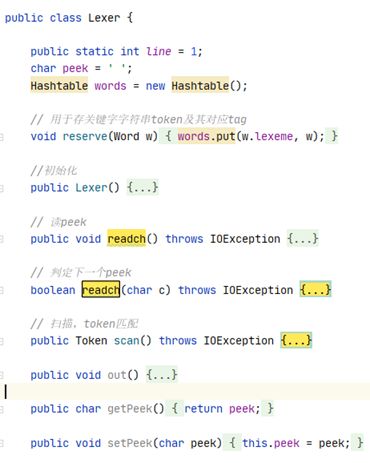
* readch****函数:
做了重载,无参数的是用来读当前指针所指的单个字符char的;而带参数的版本,则用于判定下一个peek是否为特定字符。

* scan****函数:
在得到当前所指字符peer后,scan函数使用if-else/switch等条件判断来确定token串的特征码。目前实现:1.对空格、制表符、换行符的处理 2.对“@”的错误检测 3.几类token串的匹配:逻辑符号、数字、字母。在无法识别字符时,会以char的ascii码作为其tag。

- WORD****类:TOKEN类的继承类,预定义了一些静态的逻辑WORD类型常量。作用和token类一致,用于表示特定的token。

3.1.3 错误处理
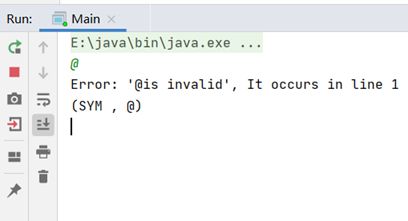
- 说明:
目前实现:在输入流中若有“@”出现,则会打印错误并指明其所在的行。
- 代码:

- 测试:
3.1.4 flex
flex,快速词法分析产生器(fast lexical analyzer generator),是一种词法分析器生成工具。flex通过读取一个有规定格式的文本文件,输出一个具有词法分析功能的C语言源程序。
- 测试结果:

2020/05/10
实验内容:
\1. 理解源码,在其基础上添加注释。
\2. 源码中没有对for语句进行分析,尝试在lexer中加入for关键字,然后参考parse还有inter中的while,do语句的实现,让parser能够识别for语句,并能检测其语法错误 。
源码理解:
-项目结构:
本次编译器前端被划分成了4个模块,以下为他们职责的摘要:
1.inter:中间代码相关,存放语法树的节点类
2.lexer:词法分析器,主要负责分词、维护TOKEN表
3.main:项目入口,负责串联所有模块,对输入源代码进行解析构建语法树。
4.symbols:符号表,负责维护TYPE表、Array表、Block变量表
3.2 Parser
-属性和方法解析:

3.2.1 数据结构
- TOP表(哈希链表):
Ø 来源:
在程序中,由于源代码通常被分成多个块(block),而由变量作用域问题,每个块的变量需要单独地维护,所以便有了ENV这个负责进行各个块变量维护的类,由于块之前存在前后关系,我们选择使用哈希链表作为我们的数据结构。
Ø 详解:
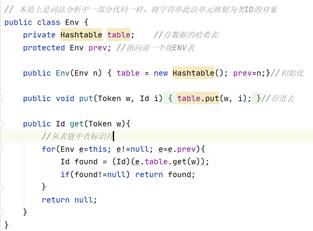
ENV类有两个类成员:
-table:哈希表,负责存该ENV负责域的数据表(token,id)
-prev:直接存放前一个ENV类
两个方法:
Get:从该块开始向前查标识符
Put:存标识符进该ENV所对应的哈希表中
3.2.2 核心算法
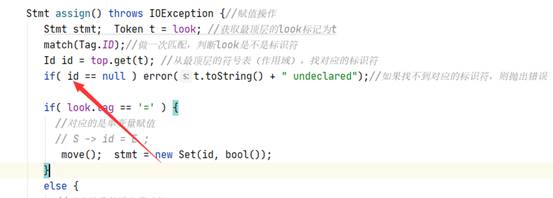
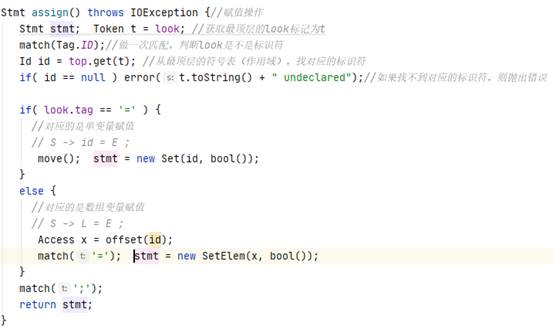
鉴于Parser整个过程一致都是调用Stmts函数构造表达式序列,而其中表达式的解析工作是由stmt函数负责,stmt函数会称为Parser的一个核心函数。
Ø stmt函数:
- 变量定义:

- 条件筛选
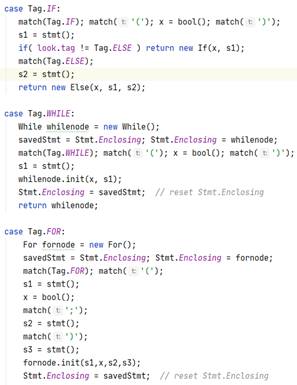
在switch语句中,会根据look的tag来选择下一步构造什么类型的节点。
3.2.3 错误处理
当匹配出错时,也就是代码不符合语法定义时,error函数会丢出一个错误,并且指明错误所在的行数。

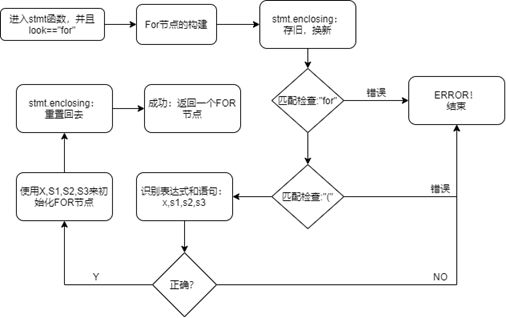
3.2.4 For语句的添加
- FOR语句添加和修改的方法:
为了能让Parser识别for语句,我进行了以下添加修改:
1.在inter包中加入了for这个中间节点类
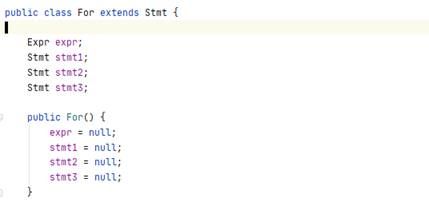
2.在lex包中加入了for这个token。

3.在parser包的parser类的stmt函数中,加入了for节点的处理工作。

- 流程图:
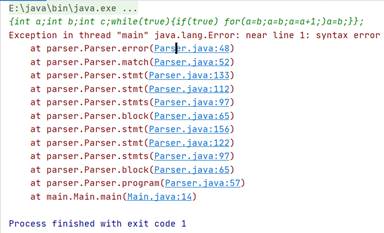
- 程序测试结果截图:
测试用例:
1.正向测试:
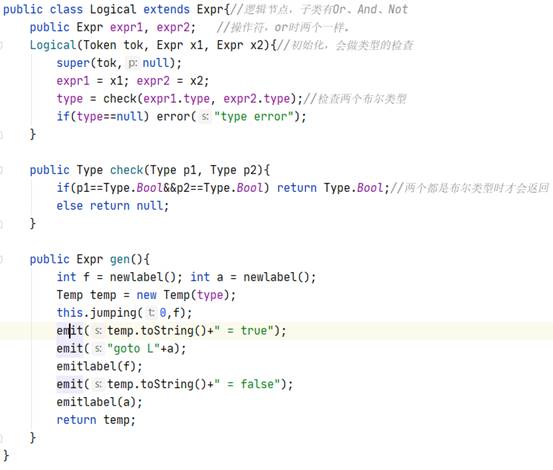
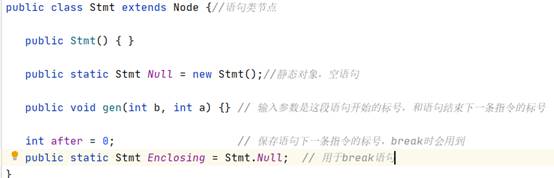
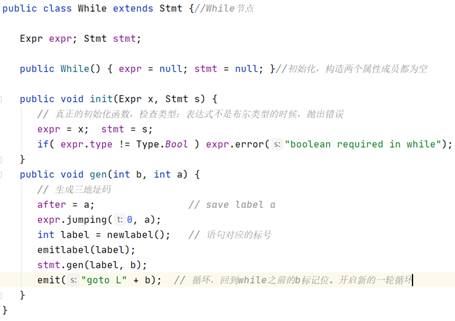
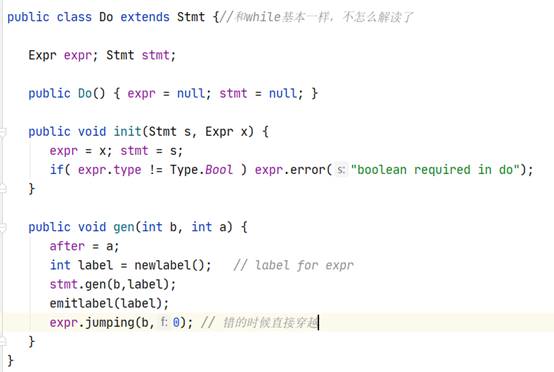
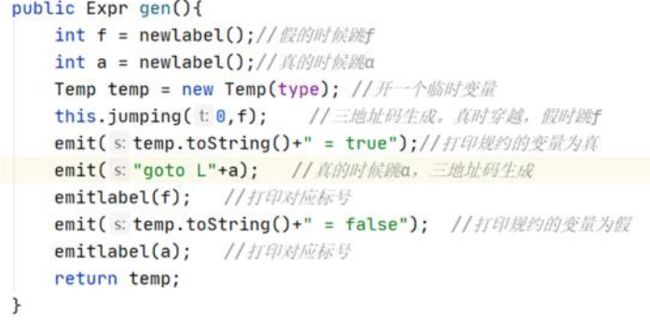
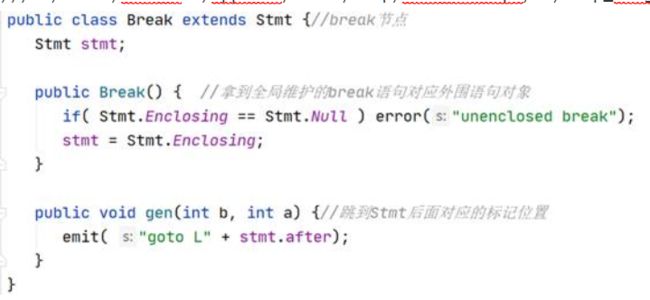
{int a;int b;int c;while(true){if(true) for(a=b;a //note:从代码一致性角度考虑,For括号里最后以表达式加了“;”,后期如果需要更改会继续改进。 测试截图: 2.反向测试(错误检测): {int a;int b;int c;while(true){if(true) for(a=b;a=b;a=a+1;)a=b;}}; //说明:将for中间的bool表达式替换为了错误的赋值语句。 测试截图: (直接copy了实验时写的报告,理解都写在注释里了) 3.3 Semantic Analyser Decaf中的语义分析模块主要完成以下的功能:类型检查、变量声明检查。类型检查中有:条件表达式需要是bool类型、操作数需要类型兼容、赋值左部和右部类型相同,变量声明检查是指变量在使用前需要声明。在Java代码中,这一部分主要涉及到了inter包。 3.3.1 数据结构 //每一行都基本注释了自己的理解,详情见图 ² Node类 ² Expr类 ² Id类 ² Op类 ² Arith类 ² Constant类 ² Logical类 ² Or类 ² Stmt类 ² If类 ² While类 ² Do类 ² Break节点 3.3.2 核心算法 ² 计算类的操作数类型检查、操作数需要类型兼容 ² 变量在使用前需要声明 ² 条件表达式需要是bool类型 ² 赋值左部和右部类型相同 这部分其实就是变着花样打字符串,说白了 ² 布尔表达式跳转 注:三地址码的生成都差不多,无非是标号和对应语句的打印和维护。 ² Break节点跳出当前Stmt //可以看到,通过Stmt全局静态成员变量Enclosing,Break可以获得after的标记,并打印相应的跳转代码 看完前端的所有代码后,顿时感觉神清气爽。再回过头看一开始觉得高大上的“emit”、“jumping”函数,不过是打印字符串的函数罢了。所以,还是不要畏难,很多时候很多知识就像这种emit/jumping,看着很吓人,仔细花时间琢磨下其实都没什么。
语法分析









中间代码生成
总结
总结下粗浅的个人理解,我觉得整个编译器前端本质上都是在做模板匹配,分词和语法分析是按模板结构化源语言,语义分析是做一定的检查,三地址的生成是打印出特定的中间代码(其实就是字符串)。