MySQL面试知识点追命连环问(一)执行流程&存储引擎&查询缓存
来了,朋友们,追命连环问系列之MySQL部分开始了。准备好了吗?本次连环问主要设计以下四个方面:
-
MySQL执行流程
-
MySQL存储引擎
-
表字段如何设计
-
查询缓存
一,MySQL的执行流程
面试官:你知道一条sql语句进来的流程是什么吗?
我:知道,我来说一下。MySQL的架构是由两部分组成的:server层和存储引擎层。
Server层:主要包括连接器、查询缓存、分析器、优化器、执行器等,所有跨存储引擎的功能都在这一层实现,比如存储过程、触发器、视图,函数等,还有一个通用的日志模块 binglog日志模块。
存储引擎:主要负责数据的存储和读取,采用可以替换的插件式架构,支持InnoDB、MyISAM、Memory等多个存储引擎,其中InnoDB引擎有自有的日志模块redolog 模块。
InnoDB 5.5.5版本作为默认引擎。
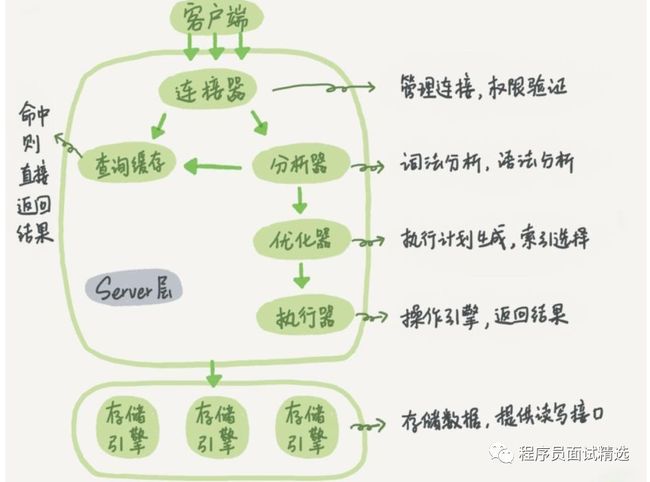
1.当客户端连接到MySQL服务器时,服吧务器会对其进行认证。通过用户名与密码认证,也可以通过SSL证书进行认证。
登录认证后,服务器还会验证客户端是否有执行某个查询的操作权限。权限在连接的时候就确定了(分为长连接和短连接),如果该用户要变更权限需要重新连接,连接后长时间没有动作则会自动断开。
2.在正式查询之前,服务器会检查查询缓存,如果能找到对应的查询,则不必进行查询分析,优化,执行等过程,直接返回缓存中的结果。
3.MySQL的分析器主要用来进行词法分析和语法分析。词法分析根据关键字分析语句,语法分析根据MySQL语法分析语句是否正确。
4.查询优化器将解析树转化为查询计划,优化器是在表里面有多个索引的时候,决定使用哪个索引;或者在一个语句有多表关联(join)的时候,决定各个表的连接顺序。优化器就是根据成本找到这其中最优的执行计划。
5.优化器之后就开始进入到执行器,执行计划调用查询执行引擎,而查询引擎通过一系列API接口查询到数据。
6.得到数据之后,在返回给客户端的同时,同时会将数据存在查询缓存中,增加下次查询的速度。
二,MySQL的存储引擎
面试官:那你知道MySQL的存储引擎都有哪些吗?
答:MySQL主要有InnoDB,MyISAM,MEMORY,MERGE和ARCHIVE。
Mysql在5.5版本之后默认存储引擎是InnoDb,而再次之前MyISAM是默认的存储引擎。
面试官:那你能说说MyISAM和InnoDB之间的区别吗?
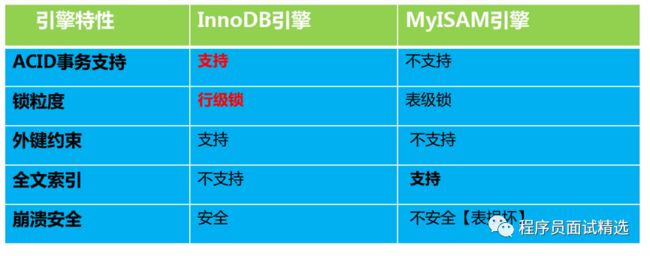
1、MYISAM不支持外键和事务,而InnoDB支持。MyISAM支持全文类型索引,而InnoDB不支持全文索引。
2、InnoDB为行级锁,MyISAM为表级锁,所以InnoDB相对于MyISAM来说,更容易发生死锁,锁冲突的概率更大,而且上锁的开销也更大,因为需要为每一行加锁;由于锁粒度的不同,InnoDB比MyISAM支持更高的并发;
3、在备份容灾上,InnoDB支持在线热备,有很成熟的在线热备解决方案;
4、查询性能上,MyISAM的查询效率高于InnoDB,因为InnoDB在查询过程中,是需要维护数据缓存,而且查询过程是先定位到行所在的数据块,然后在从数据块中定位到要查找的行;而MyISAM可以直接定位到数据所在的内存地址,可以直接找到数据;
5、SELECT COUNT(*)语句,如果行数在千万级别以上,MyISAM可以快速查出,而InnoDB查询的特别慢,因为MyISAM将行数单独存储了(计数器),而InnoDB需要逐行去统计行数;
所以如果使用InnoDB,而且需要查询行数,则需要对行数进行特殊处理,如:离线查询并缓存;
6、MyISAM的表结构文件包括:.frm(表结构定义),.MYI(索引),.MYD(数据);而InnoDB的表数据文件为:.ibd和.frm(表结构定义);
7、MyISAM删除数据时会产生碎片空间(占用表文件空间),需要定期通过optimizetable table-name手动优化。而Innodb不会。
这些不同也导致了他们应用场景的不同:
-
MyISAM管理非事务表。它提供高速存储和检索,以及全文搜索能力。如果应用中需要执行大量的SELECT查询,那么MyISAM是更好的选择。
-
InnoDB用于事务处理应用程序,具有众多特性,包括ACID事务支持。如果应用中需要执行大量的INSERT或UPDATE操作,则应该使用InnoDB,这样可以提高多用户并发操作的性能。
三,表字段的设计
面试官:嗯回答的很不错,那你平常开发中表字段是怎么设计的呢?
我:首先表名和字段名要规范,使用下划线进行连接。
字段设计原则:
1,尽量使用not null ,并且赋予初始值,建议 default ‘’,给一个空串,空串不占内存空间,NULL是占内存空间的,nuI数值的计算逻辑比较复杂。
2,char为定长(超过长度的内容将被截掉), varchar为非定长,text对内容 长度的保存额外保存而varchar对长度的保存占用数据空间。
对于varchar(N)只需要分配真正需要的空间,更大的定义列会消耗更多的内存,在使用内存临时表进行排序或操作时会根据定义的长度进行内存分配。
3,对数字的精度要有要求,对较长的数字数据可以使用decimal。
4,字段数不要过多字段注释是必要的、字段命名见名思意、可以预留字段以备扩展。
同时要尽量满足三大范式:
①. 第一范式:对属性的原子性(关系型数据库有列的念,默认就符合了)
②. 第二范式:对记录的唯一性,要求记录有唯一标识。需要确保数据库表中的每一列都和主键相关,而不能只与主键的某一部分相关(主要针对联合主键而言)
③. 第三范式:对字段的冗余性。消除对主键的传递依赖;需要确保数据表中的每一列数据都和主键直接相关,而不能间接相关。如商品表可分为商品简略信息表和商品详情表两张表。
四,查询缓存
面试官:看来你平常表的设计应该不错了,那你知道MySQL的查询缓存吗?
我:知道的。查询缓存就是将select的查询结果缓存起来,key为sql语句,value为查询结果。如果SQL功能一样,但只是多个空格或略微改动都会导致key的不匹配。
查询缓存需要客户端开启,设置query. cache. _type。
0-不开启
1-开启表示始终缓存,默认缓存每条select,针对某个sq不缓存: select sql-no-cache
2-开启表示按需缓存,默认都不缓存,通过select sql-cache制定缓存哪-个条
面试官:那你遇到慢查询都是怎么优化的呢?
我:首先,我会去查看慢查询的日志,定位到哪条语句出现了慢查询。然后再定位到相应的表和代码块。根据业务进行优化。
有可能是以下几种情况:
1,没有创建索引,或索引没起作用。
2,数据库表结构设计不合理。
3,分解关联查询,将一个大的查询分解为多个小的查询。
4,优化Limit分页。比如偏移量太大。
好啦,今天的追命连环问就到这里了,下次继续,如对文章有疑惑或补充的地方欢迎留言交流(●'◡'●)。
相关推荐阅读
Redis常见面试题连环问,你能回答到第几问?(上)
Redis常见面试题连环问,你能回答到第几问?(中)
Redis常见面试题连环问,你能回答到第几问?(下)
