一、前言
Sharding-JDBC 是一款优秀的分库分表框架,从3.0开始,Sharding-JDBC更名为Sharding-Sphere,之前用Sharding-JDBC 2时,对于同库分表而言,sql执行是串行的,因为同数据源的connection只会获取一个,并且对于connection加上了synchronized,所以对于同库分表而言,整个执行过程完全是串行的。最后为了同库分表可以并行,不得不为同一个库配置多个连接池。Sharding-Sphere 3.0对执行引擎进行了优化,引入内存限制模式和连接限制模式来动态控制并行度。
本篇博客主要剖析以下两个问题:
1、内存限制模式和连接限制模式是如何控制同一数据源串行和并行的
2、执行引擎优雅的设计
二、Sharding-Sphere的两种模式的差别
内存限制模式:对于同一数据源,如果有10张分表,那么执行时,会获取10个连接并行
连接限制模式:对于同一数据源,如果有10张分表,那么执行时,只会获取1个连接串行
控制连接模式的算法如下:

更多设计的细节可以仔细阅读Sharding-Sphere官网:http://shardingsphere.io/document/current/cn/features/sharding/principle/execute/
三、jdbc知识点回顾
对于一个庞大分库分表框架,我们应该从哪个入口看进去呢?对于基于JDBC规范实现的分库分表框架,我们只要理一下jdbc的执行过程,就知道了这个庞大框架的脉络,下面一起来回顾jdbc的执行过程。
1、加载驱动:Class.forName()
2、获取连接connection
3、由connection创建Statement或者PreparedStatement
4、用Statement或者PreparedStatement执行SQL获取结果集
5、关闭资源,流程结束
那么要看懂Sharding-Sphere的SQL执行过程,从Statement或者PreparedStatement看进去就够了。
四、源码解析
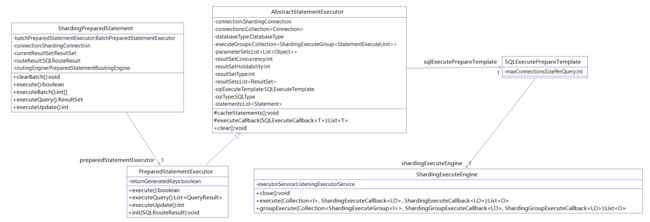
从PreparedStatement为入口,看进去,主要有如下5个类
1、ShardingPreparedStatement 实现了PreparedStatement接口
2、PreparedStatementExecutor继承于AbstractStatementExecutor,是SQL的执行器
3、SQLExecutePrepareTemplate用于获取分片执行单元,以及确定连接模式(内存限制模式和连接限制模式)
4、ShardingExecuteEngine是执行引擎,提供一个多线程的执行环境,本质上而言,ShardingExecuteEngine不做任何业务相关的事情,只是提供多线程执行环境,执行传入的回调函数(非常巧妙的设计)
类的关系如下,一目了然:
接下来,我们从ShardingPreparedStatement的executeQuery方法看进去,代码如下:
@Override
public ResultSet executeQuery() throws SQLException {
ResultSet result;
try {
clearPrevious();
sqlRoute();
initPreparedStatementExecutor();
MergeEngine mergeEngine = MergeEngineFactory.newInstance(connection.getShardingContext().getShardingRule(),
preparedStatementExecutor.executeQuery(), routeResult.getSqlStatement(), connection.getShardingContext().getMetaData().getTable());
result = new ShardingResultSet(preparedStatementExecutor.getResultSets(), mergeEngine.merge(), this);
} finally {
clearBatch();
}
currentResultSet = result;
return result;
}其中,initPreparedStatementExecutor用于初始化preparedStatementExecutor,初始化做了如下操作,根据路由单元获取statement执行单元
public void init(final SQLRouteResult routeResult) throws SQLException {
setSqlType(routeResult.getSqlStatement().getType());
getExecuteGroups().addAll(obtainExecuteGroups(routeResult.getRouteUnits()));
cacheStatements();
}
private Collection> obtainExecuteGroups(final Collection routeUnits) throws SQLException {
return getSqlExecutePrepareTemplate().getExecuteUnitGroups(routeUnits, new SQLExecutePrepareCallback() {
@Override
public List getConnections(final ConnectionMode connectionMode, final String dataSourceName, final int connectionSize) throws SQLException {
return PreparedStatementExecutor.super.getConnection().getConnections(connectionMode, dataSourceName, connectionSize);
}
@Override
public StatementExecuteUnit createStatementExecuteUnit(final Connection connection, final RouteUnit routeUnit, final ConnectionMode connectionMode) throws SQLException {
return new StatementExecuteUnit(routeUnit, createPreparedStatement(connection, routeUnit.getSqlUnit().getSql()), connectionMode);
}
});
} 那么获取statement执行单元时,是如何确定连接模式的呢?getSqlExecutePrepareTemplate().getExecuteUnitGroups点进去看,SQLExecutePrepareTemplate做了什么操作?
private List> getSQLExecuteGroups(
final String dataSourceName, final List sqlUnits, final SQLExecutePrepareCallback callback) throws SQLException {
List> result = new LinkedList<>();
int desiredPartitionSize = Math.max(sqlUnits.size() / maxConnectionsSizePerQuery, 1);
List> sqlUnitGroups = Lists.partition(sqlUnits, desiredPartitionSize);
ConnectionMode connectionMode = maxConnectionsSizePerQuery < sqlUnits.size() ? ConnectionMode.CONNECTION_STRICTLY : ConnectionMode.MEMORY_STRICTLY;
List connections = callback.getConnections(connectionMode, dataSourceName, sqlUnitGroups.size());
int count = 0;
for (List each : sqlUnitGroups) {
result.add(getSQLExecuteGroup(connectionMode, connections.get(count++), dataSourceName, each, callback));
}
return result;
} 上面这段代码就是文章开头的公式,通过 maxConnectionsSizePerQuery来控制连接模式,当maxConnectionsSizePerQuery小于本数据源执行单元时,选择连接限制模式,反之,则选择内存限制模式
当preparedStatementExecutor被初始化完成,便可进行查询
public List executeQuery() throws SQLException {
final boolean isExceptionThrown = ExecutorExceptionHandler.isExceptionThrown();
SQLExecuteCallback executeCallback = new SQLExecuteCallback(getDatabaseType(), getSqlType(), isExceptionThrown) {
@Override
protected QueryResult executeSQL(final StatementExecuteUnit statementExecuteUnit) throws SQLException {
return getQueryResult(statementExecuteUnit);
}
};
return executeCallback(executeCallback);
} 这里,callback是一个非常巧妙的设计,executeSQL即是需要执行的sql,这里可以根据需要去灵活实现,例如select、update等等操作,而executeCallback(executeCallback)便是真正的执行者,executeCallback调用sqlExecuteTemplate的executeGroup,把执行分组传入ShardingExecuteEngine执行引擎。
@SuppressWarnings("unchecked")
protected final List executeCallback(final SQLExecuteCallback executeCallback) throws SQLException {
return sqlExecuteTemplate.executeGroup((Collection) executeGroups, executeCallback);
}
public final class SQLExecuteTemplate {
private final ShardingExecuteEngine executeEngine;
/**
* Execute group.
*
* @param sqlExecuteGroups SQL execute groups
* @param callback SQL execute callback
* @param class type of return value
* @return execute result
* @throws SQLException SQL exception
*/
public List executeGroup(final Collection> sqlExecuteGroups, final SQLExecuteCallback callback) throws SQLException {
return executeGroup(sqlExecuteGroups, null, callback);
}
/**
* Execute group.
*
* @param sqlExecuteGroups SQL execute groups
* @param firstCallback first SQL execute callback
* @param callback SQL execute callback
* @param class type of return value
* @return execute result
* @throws SQLException SQL exception
*/
@SuppressWarnings("unchecked")
public List executeGroup(final Collection> sqlExecuteGroups,
final SQLExecuteCallback firstCallback, final SQLExecuteCallback callback) throws SQLException {
try {
return executeEngine.groupExecute((Collection) sqlExecuteGroups, firstCallback, callback);
} catch (final SQLException ex) {
ExecutorExceptionHandler.handleException(ex);
return Collections.emptyList();
}
}
} 接下来,精彩的时刻到了,执行引擎做了哪些事情呢?请继续往下看。
public List groupExecute(
final Collection> inputGroups, final ShardingGroupExecuteCallback firstCallback, final ShardingGroupExecuteCallback callback) throws SQLException {
if (inputGroups.isEmpty()) {
return Collections.emptyList();
}
Iterator> inputGroupsIterator = inputGroups.iterator();
ShardingExecuteGroup firstInputs = inputGroupsIterator.next();
Collection>> restResultFutures = asyncGroupExecute(Lists.newArrayList(inputGroupsIterator), callback);
return getGroupResults(syncGroupExecute(firstInputs, null == firstCallback ? callback : firstCallback), restResultFutures);
}
private Collection>> asyncGroupExecute(final List> inputGroups, final ShardingGroupExecuteCallback callback) {
Collection>> result = new LinkedList<>();
for (ShardingExecuteGroup each : inputGroups) {
result.add(asyncGroupExecute(each, callback));
}
return result;
}
private ListenableFuture> asyncGroupExecute(final ShardingExecuteGroup inputGroup, final ShardingGroupExecuteCallback callback) {
final Map dataMap = ShardingExecuteDataMap.getDataMap();
return executorService.submit(new Callable>() {
@Override
public Collection call() throws SQLException {
ShardingExecuteDataMap.setDataMap(dataMap);
return callback.execute(inputGroup.getInputs(), false);
}
});
}
private Collection syncGroupExecute(final ShardingExecuteGroup executeGroup, final ShardingGroupExecuteCallback callback) throws SQLException {
return callback.execute(executeGroup.getInputs(), true);
} sqlExecuteTemplate调用了ShardingExecuteEngine的groupExecute,groupExecute分为两个主要方法,asyncGroupExecute异步执行方法和syncGroupExecute同步执行方法,乍一看,不是多线程吗?怎么出现了一个同步,这里的多线程运用非常巧妙,先从执行分组中取出第一个元素firstInputs,剩下的丢进asyncGroupExecute的线程池,第一个任务让当前线程执行,不浪费一个线程。
这里执行引擎真正执行的是传入的回调函数,那么这个回调源于哪里呢?我们再回头去看看PreparedStatementExecutor的executeQuery方法,回调函数由此创建。
public List executeQuery() throws SQLException {
final boolean isExceptionThrown = ExecutorExceptionHandler.isExceptionThrown();
SQLExecuteCallback executeCallback = new SQLExecuteCallback(getDatabaseType(), getSqlType(), isExceptionThrown) {
@Override
protected QueryResult executeSQL(final StatementExecuteUnit statementExecuteUnit) throws SQLException {
return getQueryResult(statementExecuteUnit);
}
};
return executeCallback(executeCallback);
} 所有的逻辑一气呵成,易于扩展,设计之巧妙,难得的好代码。
最后,Sharding-Sphere是一个非常优秀的分库分表框架。
---------------------------------------------------------------------------------------------------------
快乐源于分享。
此博客乃作者原创, 转载请注明出处