高性能mysql六.查询性能优化
文章目录
- 6.1为什么查询速度会慢?
- 6.2慢查询基础:优化数据访问
- 6.2.1是否向数据库请求了不需要的数据
- 6.2.2.mysql是否在扫描额外的记录
- 6.3重构查询的方式
- 6.3.1一个复杂查询还是多个简单查询
- 6.3.2切分查询
- 6.3.3分解关联查询
- 6.4查询执行的基础
- 6.4.1mysql客户端和服务端通信协议
- 6.7优化特定类型的查询
- 6.7.1优化count()查询
- 6.7.4 group by 和distinct
- 6.7.5优化limit分页
- 6.7.7优化union
- 6.7.9使用用户自定义变量
6.1为什么查询速度会慢?
一个查询任务由多个子任务组成,每个子任务都会消耗一定时间,优化查询,就可以优化或减少子任务
6.2慢查询基础:优化数据访问
查询性能低下最基本的原因是访问的数据太多.对于低效的查询,我们可以进行以下判断
1.应用程序是否在检索大量超过需要的数据
2.确认mysql服务层是否在分析大量超过需要的数据行
6.2.1是否向数据库请求了不需要的数据
查询不需要的记录
多表关联时返回全部列
总是取出全部列
重复查询相同的数据
6.2.2.mysql是否在扫描额外的记录
一般mysql能够使用如下三种方式应用where条件,从好到坏
1.在索引中使用where过滤不匹配的记录,这是在存储引擎层完成的
2.使用索引覆盖扫描(在Extra列出现了Using index)来返回数据,直接从索引中过滤不需要的记录并返回命中结果,这是在mysql服务器层完成的,但无需再回表查询
3.从数据表中返回数据,然后过滤不满足的条件(Extra中出现Using where)这是在myqsql服务层完成,mysql需要先从数据表中独处记录然后过滤
6.3重构查询的方式
6.3.1一个复杂查询还是多个简单查询
在传统实现中,总是强调数据库完成尽可能多的操作,这样做的逻辑在于以前总是认为网络通信,查询解析和优化是一件代价很高的事情; ❌
但是这样的想法对于mysql并不适用,mysql在连接和断开设计的很轻量,在返回一个小的查询结果方面很高效
Mysql内部每秒能够扫描内存中数百万行数据,相比之下,mysql响应数据给客户端就慢得多,其他情况相同时,减少查询当然更好,但是有时候,将一个大查询分解成多个小查询是有必要的
6.3.2切分查询
eg 将一个大的delete分成多个小的
6.3.3分解关联查询
用分解关联查询的方式重构查询有以下优势:
1.让缓存效率更高
2.查询分解后,丹哥查询可以减少锁的竞争
3.应用层做关联,更容易对数据库进行拆分,更容易做高性能和扩展
4.减少冗余记录的查询寻
5.避免嵌套关联
6.4查询执行的基础
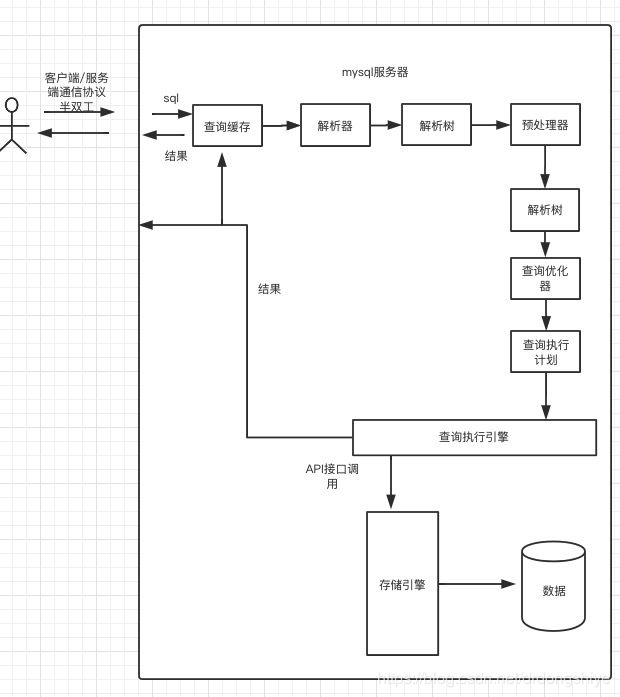
6.4.1mysql客户端和服务端通信协议
通信协议采用的"半双工",意味着,在任意时刻,要么服务器向客户端发送数据,要么客户端向服务端发送数据,两个动作不能同时进行
这样的限制让mysql通信简单快速,但是这就意味着无法流量控制,
客户端用一个单独的数据包将查询寻传给服务器, 这时如果sql过长max_allowed_packet就尤为重要
服务端响应客户端的数据通常很多,由多个数据包组成,当服务端开始响应是,客户端必须完整接收
多数连接mysql的库函数都可以获得全部结果集并缓存到内存中,还可以逐行获取需要的数据,默认是一般将获得全部结果集并缓存到内存后中.mysql通常会等到所有数据发送客户端才释放链接,所以接受结果全部缓存可以减少服务器压力,让查询早点结束,早点释放资源
但使用内存又会带来另一个问题,因为库函数需要花很多时间和内存存储所有结果
查询状态
通过 show full processlist命令查看
mysql能够处理的优化类型
重新定义关联表的顺序
将外连接转换内连接
使用等价变换规则
优化count() min() max()
预估并转化为常数表达式
使用覆盖索引扫描
子查询优化
提前终止查询
等值传播
列表in()比较
6.7优化特定类型的查询
6.7.1优化count()查询
myisam在没有任何where条件时 查询速度非常快
6.7.4 group by 和distinct
group by 通常使用查找表的标识进行分组效率更高
6.7.5优化limit分页
当偏移量特别大时,性能有很大影响
优化方案1.尽可能利用覆盖索引
2.尽可能转换成已知位置
3.通过主键id能确认更好
6.7.7优化union
如果一定需要服务器处理重复行,否则一定要带上all, 因为没有all关键字,mysql会给临时表加上distinct选项,导致临时表做唯一性检测
6.7.9使用用户自定义变量
尽量不要使用,以下场景会有问题
1.使用自定义变量查询,不能使用查询缓存
2.不能再常量或者标识符地方自定义变量,如表名,列名
3.如果使用连接池或者持久性连接,自定义变量可能引起bug
4.5.0版本前大写小写敏感
5.不能显式地声明常量类型
6.mysql优化器会在某些场景优化掉变量
7.:=优先级很低
8.使用未定义的比那辆不会有语法错误
9.赋值的顺序和赋值的时间点不固定
参考:高性能mysql