提高数据处理效率,一行代码开启Pandas四倍速!

全文共4459字,预计学习时长13分钟

图源:Unsplash
虽然Pandas是Python中处理数据的库,但其速度优势并不明显。
如何让Pandas更快更省心呢?快来了解新库Modin,可以分割pandas的计算量,提高数据处理效率,一行代码即刻开启Pandas四倍速。
首先了解一些基础知识:
Pandas作为Python中用于处理数据的库,能简单且灵活地处理不同种类、大小的数据。除此之外,Pandas还有许多函数有助于轻松处理不同数据。
Python不同工具包的受欢迎程度。来源
但Pandas也有缺点:处理大数据集的速度非常慢。
在默认设置下,Pandas只使用单个CPU内核,在单进程模式下运行函数。这不会影响小型数据,因为程序员可能都不会注意到速度的变化。但对于计算量繁杂的大数据集来说,仅使用单内核会导致运行速度非常缓慢。有些数据集可能有百万条甚至上亿条数据,如果每次都只进行一次运算,只用一个CPU,速度会很慢。
绝大多数现代电脑都有至少两个CPU。但即便是有两个CPU,使用pandas时,受默认设置所限,一半甚至以上的电脑处理能力无法发挥。如果是4核(现代英特尔i5芯片)或者6核(现代英特尔i7芯片),就更浪费了。Pandas本就不是为了高效利用电脑计算能力而设计的。
新的Modin库,通过自动将计算分摊至系统所有可用的CPU,从而加速pandas处理效率。因此,Modin据说能够使任意大小的Pandas DataFrames拥有和CPU内核数量同步的线性增长。

图源:Unsplash
现在,我们一起来看看具体操作和代码的实例。
如何使用Modin和Pandas实现平行数据处理
在Pandas中,给定DataFrame,目标是尽可能以最快速度来进行数据处理。可以使用.mean()来算出每行的平均数,用groupby将数据分类,用drop_duplicates()来删除重复项,还有很多Pandas的其他内置函数以供使用。
之前提到,Pandas只调用一个CPU来进行数据处理。这是一个很大的瓶颈,特别是对体量更大的DataFrames,资源的缺失更加突出。
理论上来讲,并行计算就如同在所有可用CPU内核中的不同数据点中计算一样简单。之于Pandas DataFrame,一个基本想法就是根据不同的CPU内核数量将DataFrame分成几个不同部分,让每个核单独计算。最后再将结果相加,这在计算层面来讲,运行成本比较低。
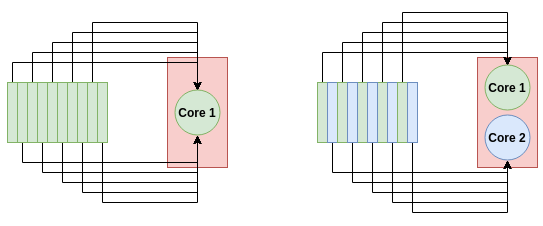
如何提高多核系统数据处理速度。在单核系统处理过程中(左),所有10个任务都用一个CPU处理。而在双核系统中(右),每个节点处理5个任务,处理速度提高一倍。
这其实也就是Modin的原理,将 DataFrame分割成不同的部分,而每个部分由发送给不同的CPU处理。Modin可以切割DataFrame的横列和纵列,任何形状的DataFrames都能平行处理。
假如拿到的是很有多列但只有几行的DataFrame。一些只能对列进行切割的库,在这个例子中很难发挥效用,因为列比行多。但是由于Modin从两个维度同时切割,对任何形状的DataFrames来说,这个平行结构效率都非常高。不管有多少行,多少列,或者两者都很多,它都能游刃有余地处理。

Pandas DataFrame(左)作为整体储存,只交给一个CPU处理。ModinDataFrame(右)行和列都被切割,每个部分交给不同CPU处理,有多少CPU就能处理多少个任务。
上述图像只是一个简单的例子。Modin通常会用到一个分盘助手(Partition Manager),它能根据操作的种类改变分盘的大小和形状。比如说,可能需要一整行或者一整列(数据)的操作。在这种情况下,分盘助手就能对任务进行切割,再分别交给不同的CPU处理,从而找到任务处理的最优解,灵活方便。
在并行处理时,Modin会从Dask或者Ray工具中任选一个来处理繁杂的数据,这两个工具都是PythonAPI的平行运算库,在运行Modin的时候可以任选一个。目前为止,Ray应该最为安全且最稳定。Dask后端还处在测试阶段。
至此,理论说的够多了。接下来聊聊代码和速度基准点。
基准测试Modin的速度
pip是安装Modin最简单的方法。用以下命令就能安装Modin, Ray和其他相关工具:
pip installmodin[ray]
下面的例子和基准测试中,会用到Kaggle公司的CS:GO CompetitiveMatchmaking Data。每行CSV都包含一套完整CS:GO的比赛数据。
现在用最大的CSV文件来进行测试。文件名为esea_master_dmg_demos.part1.csv,文件大小1.2GB。有了这么多数据,就能看到Pandas的速度有多慢,Modin又是怎么解决这个问题的。使用i7-8700kCPU来进行测试,它有6核,12线程。
首先,用熟悉的命令read_csv()来读取数据。代码在Pandas和Modin中都是一样的。
### Read in the data with Pandas
import pandas as pd
s = time.time()
df = pd.read_csv("esea_master_dmg_demos.part1.csv")
e = time.time()
print("Pandas Loading Time = {}".format(e-s))
### Read in the data with Modin
import modin.pandas as pd
s = time.time()
df = pd.read_csv("esea_master_dmg_demos.part1.csv")
e = time.time()
print("Modin Loading Time = {}".format(e-s))
为了测试速度,导入time模块,在read_csv()前后都放上了time.time()命令。Pandas花了8.38秒将数据从CSV加载到内存,而Modin只花了3.22秒,快了接近2.6倍。仅仅改变了输入命令就达到这样的效果,还不错。
下面试试更有挑战性的任务。将多个DataFrame串联起来在Pandas中是很常见的操作,需要一个一个地读取CSV文件看,再进行串联。Pandas和Modin中的pd.concat()函数能很好实现这一操作。
预计Modin能在这类操作中表现很好,因为这项任务涉及的数据量很大。代码如下。
import pandas as pd
df = pd.read_csv("esea_master_dmg_demos.part1.csv")
s = time.time()
df = pd.concat([df for _ inrange(5)])
e = time.time()
print("Pandas Concat Time = {}".format(e-s))
import modin.pandas as pd
df = pd.read_csv("esea_master_dmg_demos.part1.csv")
s = time.time()
df = pd.concat([df for _ inrange(5)])
e = time.time()
print("Modin Concat Time = {}".format(e-s))
在上述代码中,重复拼接了5次DataFrame。Pandas以3.56秒的速度完成,Modin仅用0.041秒,快了86.83倍!虽然只有6核CPU,对DataFrame进行切分仍然能显著提高速度。
.fillna()是Pandas常用于DataFrame清理的函数。它能找到DataFrame中所有NaN值,再替换成需要的值。这个过程需要很多步骤。Pandas要逐行逐列地去浏览,找到NaN值,再进行替换。使用Modin就能完美解决重复运行简单操作的问题。
import pandas as pd
df = pd.read_csv("esea_master_dmg_demos.part1.csv")
s = time.time()
df = df.fillna(value=0)
e = time.time()
print("Pandas Concat Time = {}".format(e-s))
import modin.pandas as pd
df = pd.read_csv("esea_master_dmg_demos.part1.csv")
s = time.time()
df = df.fillna(value=0)
e = time.time()
print("Modin Concat Time = {}".format(e-s))
这次,Pandas运行了.fillna()仅花了1.8秒,而Modin只用了0.21秒,快了8.57倍!
注意事项以及最后的测试
Modin能一直这么快吗?
并不是。

图源:Unsplash
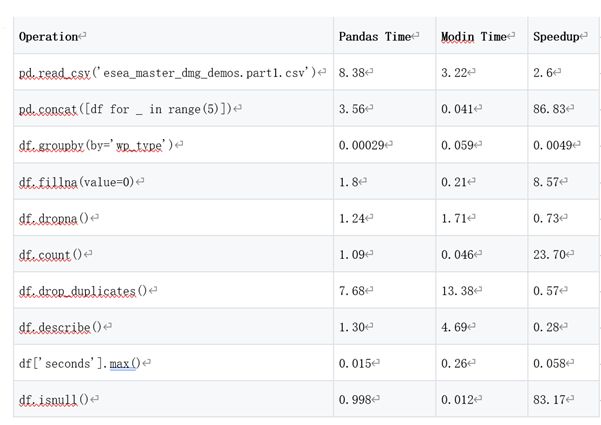
有时Pandas会比Modin快一些,即使在处理这个有5,992,097(接近6百万)行的数据时。下列表格对比展示了笔者分别使用Pandas和Modin做测试的运行时间。
如图所示,在一些操作中,Modin的速度明显要快一些,通常是读取数据,查询数值的时候。但Pandas在其他操作会快很多,比如统计计算。
Modin实用技巧
Modin还是相对比较新的库,还在开发扩展中。所以并不是所有Pandas函数都能在Modin中得以实现。如果想用Modin来运行一个尚未加速的函数,它还是会默认在Pandas中运行,来保证没有任何代码错误。
在默认设置下,Modin会使用机器上所有能用的CPU。如果想把一部分CPU用到别的地方,可以通过Ray的初始设定来设置Modin的权限,因为Modin会在后端使用Ray这个工具。
import ray
ray.init(num_cpus=4)
import modin.pandasas pd
处理大量数据的时候,数据集的大小一般不会超过系统内存的大小。Modin有一个特定标志,可以设它的值为true,开启“核外(out of core)”模式。核外运行就意味着Modin会把硬盘当做溢出内存,这样就可以处理比内存还大的数据集了。可以设置如下环境变量来启用这个功能:
exportMODIN_OUT_OF_CORE=true
总结
上文就是使用Modin来对Pandas函数进行加速的方法。
只要改变一下输入命令就可以实现,非常简单。希望本文能够帮助你成为“熊猫速度达人”!
完结撒花!


推荐阅读专题




留言 点赞 发个朋友圈
我们一起分享AI学习与发展的干货
编译组:翁梦徽、李韵帷
相关链接:
https://www.kdnuggets.com/2019/11/speed-up-pandas-4x.html
如需转载,请后台留言,遵守转载规范
推荐文章阅读
ACL2018论文集50篇解读
EMNLP2017论文集28篇论文解读
2018年AI三大顶会中国学术成果全链接
ACL2017 论文集:34篇解读干货全在这里
10篇AAAI2017经典论文回顾
长按识别二维码可添加关注
读芯君爱你