Scrapy入门教程
Python版本:3.5 系统:Windows
一、准备工作
需要先安装几个库(pip,lxml,pywin32,Twisted,pyOpenSSL),这些都比较容易,如果使用的是Pycharm,就可以更方便的安装模块,在settings里可以选择版本进行下载。
如果在命令行模式下输入pip -V出现 'pip' 不是内部或外部命令,也不是可运行的程序或批处理文件,先确保自己在环境变量中配置E:\Python3.5\Scripts,如果环境变量配置没有问题,但还是出现 'pip' 不是内部或外部命令,也不是可运行的程序或批处理文件,可以在命令行模式下输入python -m pip install --upgrade pip,这步操作之后应该就没问题了。
二、安装scrapy库
在E盘新建一个Scrapy文件夹,然后进入文件夹,shift+鼠标右键,然后打开命令窗口。

在命令行窗口里输入pip install scrapy,就会安装scrapy的最新版本,安装好了之后输入scrapy -h查看相应信息。

如果安装失败, 解决方法如下:
在http://www.lfd.uci.edu/~gohlke/pythonlibs/有很多用于windows的编译好的Python第三方库,我们下载好对应自己Python版本的库即可。
(1)在cmd中输入指令python,查看python的版本,如下:

从上图可以看出可以看出我的Python版本为Python3.5.2-64bit。
(2)登陆http://www.lfd.uci.edu/~gohlke/pythonlibs/,Ctrl+F搜索Lxml、Twisted、Scrapy,下载对应的版本,例如:lxml-3.7.3-cp35-cp35m-win_adm64.whl,表示lxml的版本为3.7.3,对应的python版本为3.5-64bit。我下载的版本如下图所示:


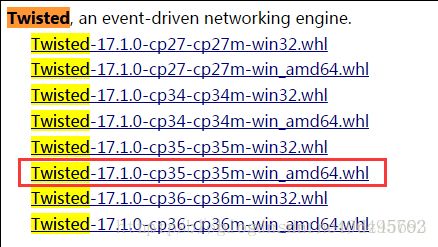
(3)在cmd中输入DOS指令,进入下载好的whl文件夹下,例如我的三个whl文件放在了Scrapy文件夹下:
(4)依次执行如下命令:
a.pip3 install wheel

b.pip3 install lxml-3.7.3-cp35-cp35m-win_amd64.whl

c.pip3 install Twisted-17.1.0-cp35-cp35m-win_amd64.whl
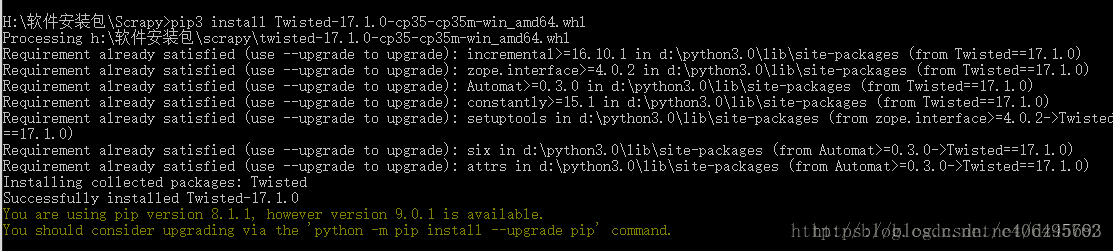
d.pip3 install Scrapy-1.3.2-py2.py3-none-any.whl

这样Scrapy的安装就完成了,请忽略最后两行让我升级pip的信息。*.*
三、创建项目
在开始爬取之前,我们必须创建一个新的Scrapy项目。 进入我们打算存储代码的目录中,运行下列命令::
scrapy startproject Test
该命令将会创建包含下列内容的Test 目录:
Test/ Test/ __init__.py items.py pipelines.py settings.py spiders/ __init__.py
这些文件分别是:
Test/: 该项目的python模块。之后您将在此加入代码。
Test/items.py: 项目中的item文件.
Test/pipelines.py: 项目中的pipelines文件.
Test/settings.py: 项目的设置文件.
Test/spiders/: 放置spider代码的目录.
做完上述准备工作之后,就可以开始写我们的第一个scrapy项目了
一、Scrapy终端(scrapy shell)
Scrapy终端是一个交互终端,供我们在未启动spider的情况下尝试及调试爬取代码。 其本意是用来测试提取数据的代码,不过我们可以将其作为正常的Python终端,在上面测试任何的Python代码。
在命令行界面输入scrapy shell
scrapy shell https://www.huya.com/g/lol
接着该终端(使用Scrapy下载器(downloader))获取URL内容并打印可用的对象及快捷命令(注意到以[s] 开头的行):

fetch(request)- 从给定请求获取新响应,并相应地更新所有相关对象。view(response)- 在本地Web浏览器中打开给定的响应,以进行检查。这将向响应正文添加一个标记,以便正确显示外部链接(如图片和样式表)。但请注意,这将在您的计算机中创建一个临时文件,不会自动删除。 shelp()- 打印有可用对象和快捷方式列表的帮助
二、建立第一个Scrapy项目
选择一个文件夹,shift+右键然后进入命令行界面,输入以下代码新建一个Scrapy项目:
scrapy startproject HuyaLol
打开Pycharm,然后再打开我们刚建好的HuyaLol项目,在spiders文件夹下新建一个lol.py
然后就可以在lol.py里编写我们的程序了,代码如下:
import scrapy
class huyalol(scrapy.Spider):
name = "huyalol"
start_urls = ["https://www.huya.com/g/lol"]
def parse(self, response):
title_list = response.xpath('//*[@id="js-live-list"]/li/a[2]/text()').extract()
name_list = response.xpath('//*[@id="js-live-list"]/li/span/span[1]/i/text()').extract()
for i in range(1,11):
print(name_list[i-1], ': ',title_list[i-1])然后在Pycharm里打开命令行界面,输入scrapy list可以列出当前爬虫项目下所有的爬虫文件,这里只有一个爬虫文件huyalol。
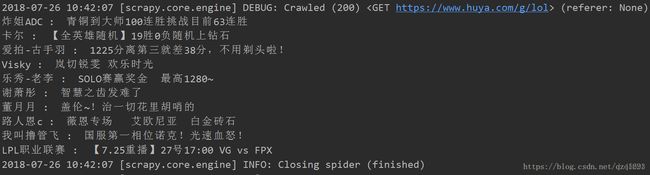
然后在命令行界面输入scrapy crawl huyalol,就可以运行我们的爬虫了,结果如下:
三、遇到的问题及解决办法
(1)利用xpath获取不到数据,反复检查代码之后,发现是引号出了问题
”//*[@id="js-live-list"]/li/a[2]/text()“
这里两端要用单引号,因为中间使用了双引号。
(2)根据教程上把@id="js-live-list"改成@class=“title new-clickstat”后获取不到数据,这个应该注意一下。
(3)在纠正上述问题后还是没有得到数据
解决办法:把settings.py里的ROBOTSTXT_OBEY = True改成ROBOTSTXT_OBEY = False
---------------------------------------------------------------------------------------------------------------------------------------------
当然你可能还没有安装scrapy,这里我就不繁琐的讲解的,具体点就是 在你直接pip install scrapy之前你需要安装scrapy所依赖的环境
(pip install parsel,pip install Twisted,pip install lxml)还有的环境自己可以去网上查看。
找一个你以后存放scrapy文件的地方执行命令:scrapy startproject get_douban
会生成一个get_douban文件夹: 这里面包含了scrapy的一些必要文件,作为一个新手我们先不要管,
现在你需要在get_doubande 的spiders文件夹中新建一个douban.py文件,我们用来写爬虫的文件,以下是douban.py的代码
你可能需要了解一下xpath(http://www.w3school.com.cn/xpath/)这里你可以简单地了解一下。
import scrapy
from scrapy.http import Request
class DoubanSpider(scrapy.Spider):
name = "douban" #这个name是你必须给它一个唯一的名字 后面我们执行文件时的名字
start_urls = ["https://movie.douban.com/top250"]
#这个列表中的url可以有多个,它会依次都执行,我们这里简单爬取一个
url = "https://movie.douban.com/top250"
#因为豆瓣250有翻页操作,我们设置这个url用来翻页
def parse(self,response):#默认函数parse
sites = response.xpath('//ol[@class="grid_view"]') #('匹配你所需信息的路径')
#xpath是scrapy里面的一种匹配方式,类似于正则表达式,还有其他几种匹配方式
#这里我们首先获得的是我们需要的信息的那一大块sites。
print("!!!!!返回信息是:")
info = sites.xpath('./li')
#从sites中我们再进一步获取到所有电影的所有信息
for i in info: #这里的i是每一部电影的信息
#排名
num = i.xpath('./div//em[@class=""]//text()').extract() #获取到的为列表类型
#extract()是提取器 将我们匹配到的东西取出来
print(num[0],end=";")
#标题
title = i.xpath('.//span[@class="title"]/text()').extract()
print(title[0],end=";")
#评论
remark = i.xpath('.//span[@class="inq"]//text()').extract()
#分数
score = i.xpath('./div//span[@class="rating_num"]//text()').extract()
print(score[0])
nextlink = response.xpath('//span[@class="next"]/link/@href').extract()
#还记得我们之前定义的url吗,由于电影太多网页有翻页显示,这里我们获取到翻页的那个按钮的连接nextlink
if nextlink: #翻到最后一页是没有连接的,所以这里我们要判断一下
nextlink = nextlink[0]
print(nextlink)
yield Request(self.url+nextlink,callback=self.parse)
#yield中断返回下一页的连接到parse让它重新从下一页开始爬取,callback返回函数定义返回到哪里
以上便是spiders的douban.py里面的代码,现在应该怎么执行呢?
在get_douban文件里面打开cmd输入执行文件的命令:scrapy crawl douban 回车
你会得到下面的信息:

这样你就实现了使用scrapy简单的爬虫,爬取豆瓣250了,有什么意见都是可以提的。
运行的时候遇到403的错误

解决办法:
这是因为服务器判断出爬虫程序,拒绝我们访问,修改下就可以了,在settings中设定USER_AGENT的值,伪装成浏览器访问页面。
USER_AGENT = "Mozilla/4.0 (compatible; MSIE 6.0; Windows NT 5.1; SV1; AcooBrowser; .NET CLR 1.1.4322; .NET CLR 2.0.50727)"再试一次,又报错:301错误。。看到其中提示robots.txt。然后把settings中的ROBOTSTXT_OBEY = False设置为"False",运行