决策树规则挖掘
文章目录
- 1. 导入相应的包并加载数据
- 2. 将数据分为三类进行处理
- 3. 填补缺失值并截取数据
- 4. 去重
- 5. 变量衍生
- 6. 对dstc_lst变量求distinct个数
- 7. 将变量组合在一起
- 8. 用决策树进行训练
- 9. 输出决策树图像,并作出决策
下面用了一个油品相关的数据做了一个决策树规则挖掘。

1. 导入相应的包并加载数据
import pandas as pd
import numpy as np
#消除Waring
import warnings
warnings.filterwarnings("ignore")
data = pd.read_excel('oil_data_for_tree.xlsx')
data.head()
data.shape
(50609, 19)
查看下class_new有几类
data.class_new.unique()
array([‘B’, ‘E’, ‘C’, ‘A’, ‘D’, ‘F’], dtype=object)
2. 将数据分为三类进行处理
org_lst 不需要做特殊变换,直接去重
agg_lst 数值型变量做聚合
dstc_lst 文本型变量做cnt
#在这里,变量'total_oil_cnt', 'pay_amount_total'没有添加进去
org_lst = ['uid','create_dt','oil_actv_dt','class_new','bad_ind']
agg_lst = ['oil_amount','discount_amount','sale_amount','amount','pay_amount','coupon_amount','payment_coupon_amount']
dstc_lst = ['channel_code','oil_code','scene','source_app','call_source']
数据重组
#为不改变元数据,可以将元数据copy下来,进行处理
df = data[org_lst].copy()
df[agg_lst] = data[agg_lst].copy()
df[dstc_lst] = data[dstc_lst].copy()
df.shape
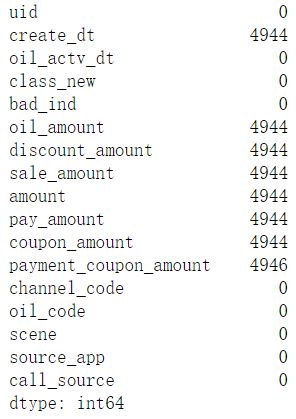
查看下缺失值情况
df.isnull().sum()
3. 填补缺失值并截取数据
下面要对对creat_dt做补全,缺失值用oil_actv_dt来填补,并且截取6个月的数据。
需要注意的是:构造变量的时候不能直接对历史所有数据做累加 ,否则随着时间推移,变量分布会有很大的变化。
#这里对creat_dt做补全,用oil_actv_dt来填补,并且截取6个月的数据。
def time_isna(x,y):
if str(x) == 'NaT':
x = y
else:
x = x
return x
df2 = df.sort_values(['uid','create_dt'],ascending = False)
df2['create_dt'] = df2.apply(lambda x: time_isna(x.create_dt,x.oil_actv_dt),axis = 1)
df2['dtn'] = (df2.oil_actv_dt - df2.create_dt).apply(lambda x: x.days)
df = df2[df2['dtn'] < 180]
df.head()
# 这里可以看出,筛选掉日期差大于180天的数据后,减少了将近5000左右的数据
df.shape
(45039, 18)
4. 去重
对org_list变量求历史贷款天数的最大间隔,也就是订单日期和贷款日期最大差值(dtn),并且去重
base = df[org_lst]
base['dtn'] = df['dtn']
base = base.sort_values(by = ['uid','create_dt'],ascending = False)
base = base.drop_duplicates(['uid'],keep = 'first')
#去重后可以看出数据剩下10000个左右
base.shape
(11099, 6)
base.head()
5. 变量衍生
gn = pd.DataFrame()
for i in agg_lst:
#统计次数
tp = pd.DataFrame(df.groupby('uid').apply(lambda df:len(df[i])).reset_index())
tp.columns = ['uid',i + '_cnt']
if gn.empty == True:
gn = tp
else:
gn = pd.merge(gn, tp, on = 'uid',how = 'left')
#统计数值大于0的个数
tp = pd.DataFrame(df.groupby('uid').apply(lambda df:np.where(df[i]>0,1,0).sum()).reset_index())
tp.columns = ['uid',i + '_num']
if gn.empty == True:
gn = tp
else:
gn = pd.merge(gn,tp,on = 'uid',how = 'left')
#统计所有数值的和
tp = pd.DataFrame(df.groupby('uid').apply(lambda df:np.nansum(df[i])).reset_index())
tp.columns = ['uid',i + '_tot']
if gn.empty == True:
gn = tp
else:
gn = pd.merge(gn,tp,on = 'uid',how = 'left')
#统计所有数值的均值
tp = pd.DataFrame(df.groupby('uid').apply(lambda df:np.nanmean(df[i])).reset_index())
tp.columns = ['uid',i + '_avg']
if gn.empty == True:
gn = tp
else:
gn = pd.merge(gn,tp,on = 'uid',how = 'left')
#统计所有数值的最大值
tp = pd.DataFrame(df.groupby('uid').apply(lambda df:np.nanmax(df[i])).reset_index())
tp.columns = ['uid',i + '_max']
if gn.empty == True:
gn = tp
else:
gn = pd.merge(gn,tp,on = 'uid',how = 'left')
#统计所有数值的最小值
tp = pd.DataFrame(df.groupby('uid').apply(lambda df:np.nanmin(df[i])).reset_index())
tp.columns = ['uid',i + '_min']
if gn.empty == True:
gn = tp
else:
gn = pd.merge(gn,tp,on = 'uid',how = 'left')
#统计所有数值的方差
tp = pd.DataFrame(df.groupby('uid').apply(lambda df:np.nanvar(df[i])).reset_index())
tp.columns = ['uid',i + '_var']
if gn.empty == True:
gn = tp
else:
gn = pd.merge(gn,tp,on = 'uid',how = 'left')
#统计所有数值最大、最小值的差值(极差)
tp = pd.DataFrame(df.groupby('uid').apply(lambda df:np.nanmax(df[i]) -np.nanmin(df[i]) ).reset_index())
tp.columns = ['uid',i + '_t']
if gn.empty == True:
gn = tp
else:
gn = pd.merge(gn,tp,on = 'uid',how = 'left')
#统计变异系数(方差/均值)
tp = pd.DataFrame(df.groupby('uid').apply(lambda df:max(np.nanvar(df[i])/np.nanmean(df[i]),1)).reset_index())
tp.columns = ['uid',i + '_tar']
if gn.empty == True:
gn = tp
else:
gn = pd.merge(gn,tp,on = 'uid',how = 'left')
6. 对dstc_lst变量求distinct个数
gc = pd.DataFrame()
for i in dstc_lst:
tp = pd.DataFrame(df.groupby('uid').apply(lambda df: len(set(df[i]))).reset_index())
tp.columns = ['uid',i + '_dstc']
if gc.empty == True:
gc = tp
else:
gc = pd.merge(gc,tp,on = 'uid',how = 'left')
7. 将变量组合在一起
fn = pd.merge(base,gn,on= 'uid')
fn = pd.merge(fn,gc,on= 'uid')
fn.shape
(11099, 74)
将缺失值填充为0
fn = fn.fillna(0)
fn.head()
8. 用决策树进行训练
x = fn.drop(['uid','oil_actv_dt','create_dt','bad_ind','class_new'],axis = 1)
y = fn.bad_ind.copy()
from sklearn import tree
dtree = tree.DecisionTreeRegressor(max_depth = 2,min_samples_leaf = 500,min_samples_split = 5000)
dtree = dtree.fit(x,y)
9. 输出决策树图像,并作出决策
import pydotplus
from IPython.display import Image
from sklearn.externals.six import StringIO
with open("dt.dot", "w") as f:
tree.export_graphviz(dtree, out_file=f)
dot_data = StringIO()
tree.export_graphviz(dtree, out_file=dot_data,
feature_names=x.columns,
class_names=['bad_ind'],
filled=True, rounded=True,
special_characters=True)
graph = pydotplus.graph_from_dot_data(dot_data.getvalue())
import os
#这是我自己的路径,注意修改你的路径
os.environ["PATH"] += os.pathsep + 'D:/软件/graphviz-2.38/release/bin/'
Image(graph.create_png())
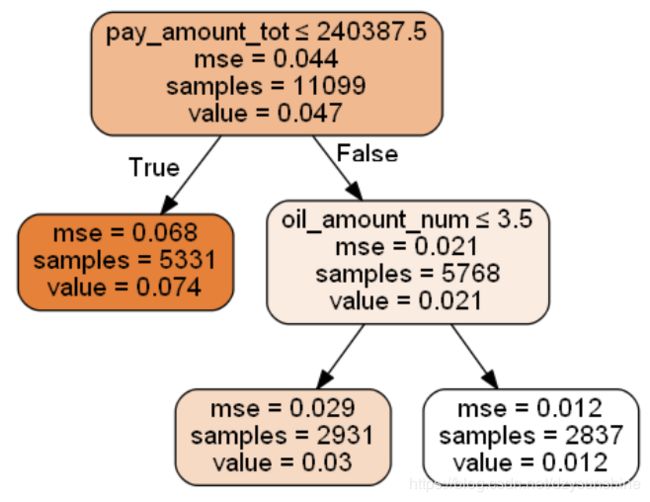
#坏账率
sum(fn.bad_ind)/len(fn.bad_ind)
0.04658077304261645
#生成策略
dff1 = fn.loc[(fn.amount_tot>48077.5)&(fn.coupon_amount_cnt>3.5)].copy()
dff1['level'] = 'oil_A'
dff2 = fn.loc[(fn.amount_tot>48077.5)&(fn.coupon_amount_cnt<=3.5)].copy()
dff2['level'] = 'oil_B'
dff3 = fn.loc[(fn.amount_tot<=48077.5)].copy()
dff3['level'] = 'oil_C'
dff1.head()

dff1 = dff1.append(dff2)
dff1 = dff1.append(dff3)
dff1 = dff1.reset_index(drop = True)
dff1.head()
dff1.shape
(11099, 75)
last = dff1[['class_new','level','bad_ind','uid','oil_actv_dt','bad_ind']].copy()
last['oil_actv_dt'] = last['oil_actv_dt'] .apply(lambda x:str(x)[:7]).copy()
last.head(5)
last.to_excel('final_report.xlsx',index = False)