Scrapy框架入门
Scrapy简介
Scrapy框架是使用Python开发的一个快速、高层次的屏幕抓取和web抓取框架,用于抓取web站点并从页面中提取结构化的数据。Scrapy用途广泛,可以用于数据挖掘、监测和自动化测试
Scrapy不仅有单机版,开发者还可以使用其集群版Scrapy-redis开发分布式爬虫程序,分布式爬虫有更快的速度和更高的效率
Scrapy用途非常广泛,用户只需要定制开发几个模块就可以轻松的实现一个爬虫,用来抓取网页内容以及各种图片,非常之方便
Scrapy框架结构
Scrapy框架由几个关键的组件构成,他们的关系如下图所示,Scrapy结构图:
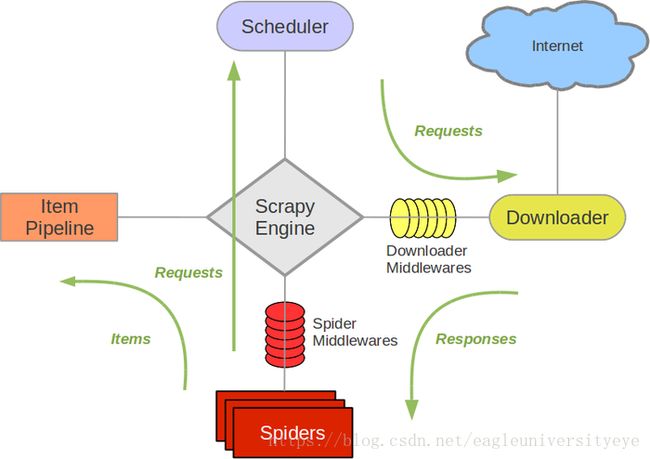
Scrapy框架的组件
Scrapy Engine
爬虫引擎,负责Spider、ItemPipeline、Downloader、Scheduler中间的通讯,信号、数据传递等
Scheduler
调度器,它负责接受引擎发送过来的Request请求,并按照一定的方式进行整理排列,入队,当引擎需要时,交还给引擎
Downloader
下载器,负责下载Scrapy Engine发送的所有Requests请求,并将其获取到的Responses交还给Scrapy Engine,由引擎交给Spider来处理
Spider
爬虫,它负责处理所有Responses,从中分析提取数据,获取Item字段需要的数据,并将需要跟进的URL提交给引擎,再次进入Scheduler
Item Pipeline
管道,负责处理Spider中获取到的Item,并进行进行后期处理(详细分析、过滤、存储等)
Downloader Middlewares
下载中间件,可以自定义扩展下载功能
Spider Middlewares
Spider中间件,可以自定扩展和操作引擎和Spider中间通信的功能组件(比如进入Spider的Responses和从Spider出去的Requests)
Scrapy框架的运作流程
- Spider将目标网址(如要爬取百度首页,网址应为www.baidu.com)发送给Scrapy Engine
- Scrapy Engine将Spider发送过来的URL地址转发给Scheduler(可以看出Scrapy Engine主要是起协同作用)
- Scheduler调度器对Scrapy Engine发送过来的所有request请求进行排序入队
- Scheduler调度器将等待队列中队首的request请求发送给Downloader下载器
- Downloader下载器按照Downloader Middlewares中的下载设置进行对request请求访问的内容进行下载,如果下载失败,则稍后再次重试
- Downloader将下载下来的网页内容交给Spider,Spider处理网页后将爬取的数据交给Item Pipeline进行存储。同时若Spider产生新的Request请求,则发送给Scrapy Engine,重复以上过程
只有当调度器的Request被完全处理完,Spider不在产生新的Request请求,整个程序才会停止。下载失败的URL,Scrapy会不断尝试重新下载直到成功为止
Scrapy框架的开发流程
使用Scrapy开发爬虫要经历如下几个步骤:
1. 新建项目 :创建爬虫项目
2. 明确目标 :确定要爬取的网页
3. 制作爬虫 :制作爬虫爬取网页
4. 存储内容 :设计管道存储爬取内容
使用Scrapy创建一个Python爬虫
1.安装Scrapy框架
Scrapy官方中文网:http://scrapy-chs.readthedocs.io/zh_CN/latest/index.html
Scrapy官网:https://doc.scrapy.org/en/latest/
Windows环境下:
使用Python自带的包管理工具pip进行安装:
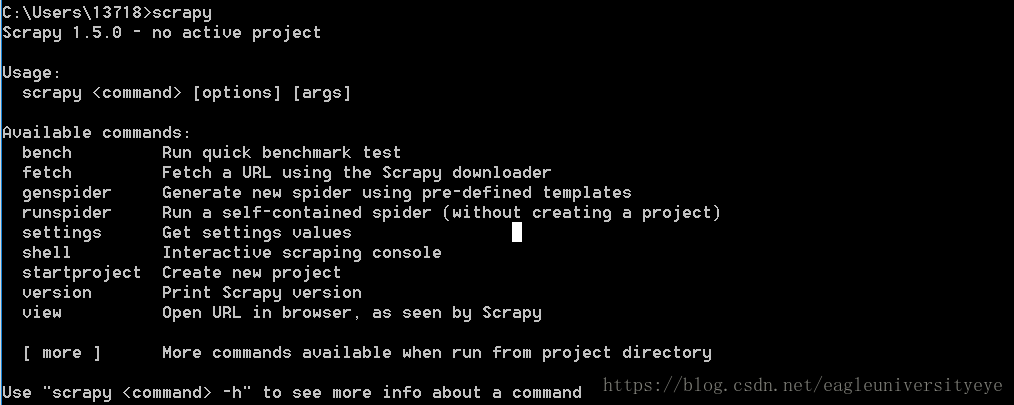
pip install Scrapy在命令行输入
scrapy显示如下,则说明Scrapy安装成功
Linux环境下:
运行两个命令:
sudo apt-get install python-dev python-pip libxml2-dev libxslt1-dev zlib1g-dev libffi-dev libssl-dev
sudo pip install scrapy2.使用Scrapy创建项目
在命令行中输入命令scrapy startproject ScrapyDemo,Scrapy框架会自动生成一个名为ScrapyDemo的爬虫项目,目录结构如下图所示:
各个文件的作用:
scrapy.cfg :项目的配置文件
mySpider/ :项目根目录
mySpider/items.py :项目的目标文件,用来指定爬取哪些内容
mySpider/pipelines.py :项目的管道文件
mySpider/settings.py :项目的设置文件
mySpider/spiders/ :放置爬虫代码
3.制作爬虫
创建爬虫程序
在ScrapyDemo框架spider文件夹下运行命令:scrapy genspider bupt "bupt.edu.cn",框架自动在spider文件夹下生成爬虫程序文件bupt.py,自动生成的爬虫程序有默认代码:
import scrapy
class BuptSpider(bupt.Spider):
name = "itcast"
allowed_domains = ["bupt.edu.cn"]
start_urls = (
'http://www.bupt.edu.cn/',
)
def parse(self, response):
pass也可以自己创建文件,不过使用命令可以省去一些麻烦
爬虫程序文件的主要内容
主要内容有三个属性和一个方法,name属性,allowed_domains属性,和start_urls属性,parse方法
name = “”
爬虫的名称,必须是唯一的,在同一个项目中不同的爬虫必须定义不同的名字
allow_domains = []
搜索的域名范围,爬虫的约束区域,规定爬虫只爬取这个域名下的网页,不存在的URL会被忽略
start_urls = ()
爬取的URL元祖/列表。爬虫从这里开始抓取数据,所以,第一次下载的数据将会从这些urls开始。其他子URL将会从这些起始URL中继承性生成
parse(self, response)
解析方法,每个初始URL完成下载后将被调用,调用的时候传入从每一个URL传回的Response对象来作为唯一参数,主要负责解析返回的网页数据(response.body),提取结构化数据(生成item)和生成需要下一页的URL请求
一般情况下三个属性都不需要改,需要在parse函数中添加操作,指定需要获取并保存哪些数据。这里只举一个简单的例子,先不使用Scrapy框架的管道(item)功能,直接将网页下载下来,代码如下:
# coding=utf-8
import scrapy
class BuptSpider(scrapy.Spider):
name = "bupt"
allowed_domains = ["scs.bupt.edu.cn"]
start_urls = (
'https://www.bupt.edu.cn/',
)
def parse(self, response):
filename = "index.html"
open(filename, 'wb+').write(response.body)
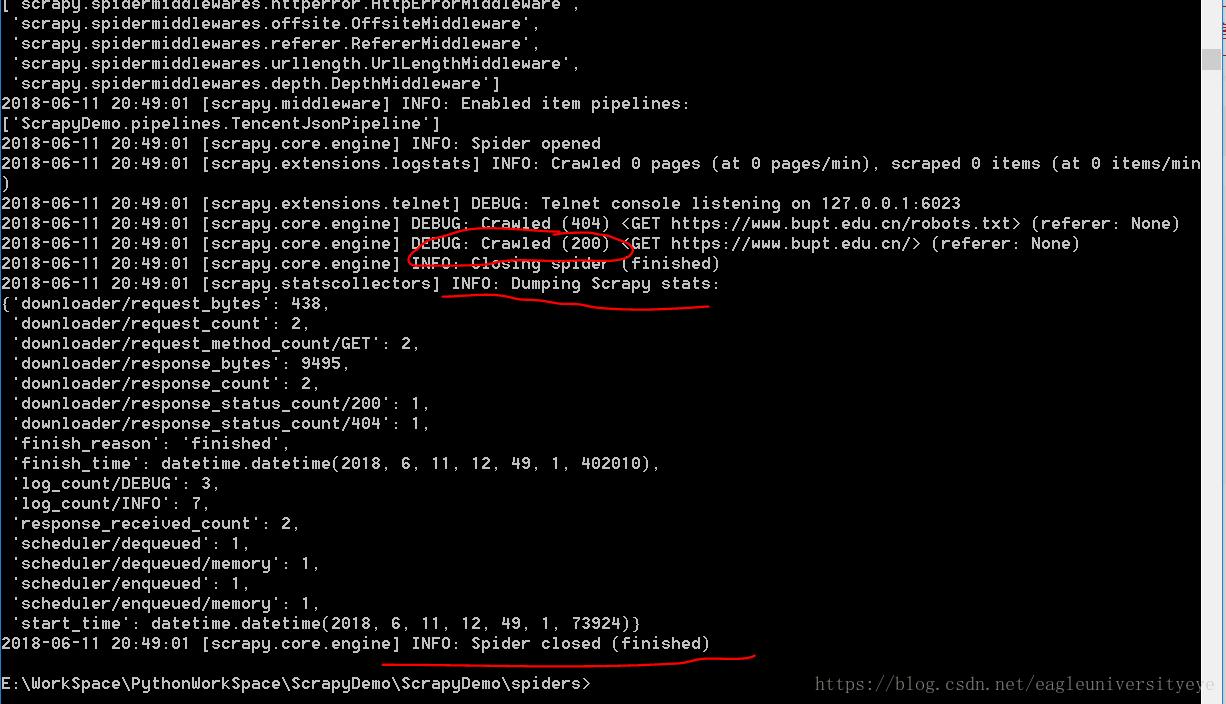
在spiders文件夹下,运行命令scrapy crawl bupt,启动爬虫
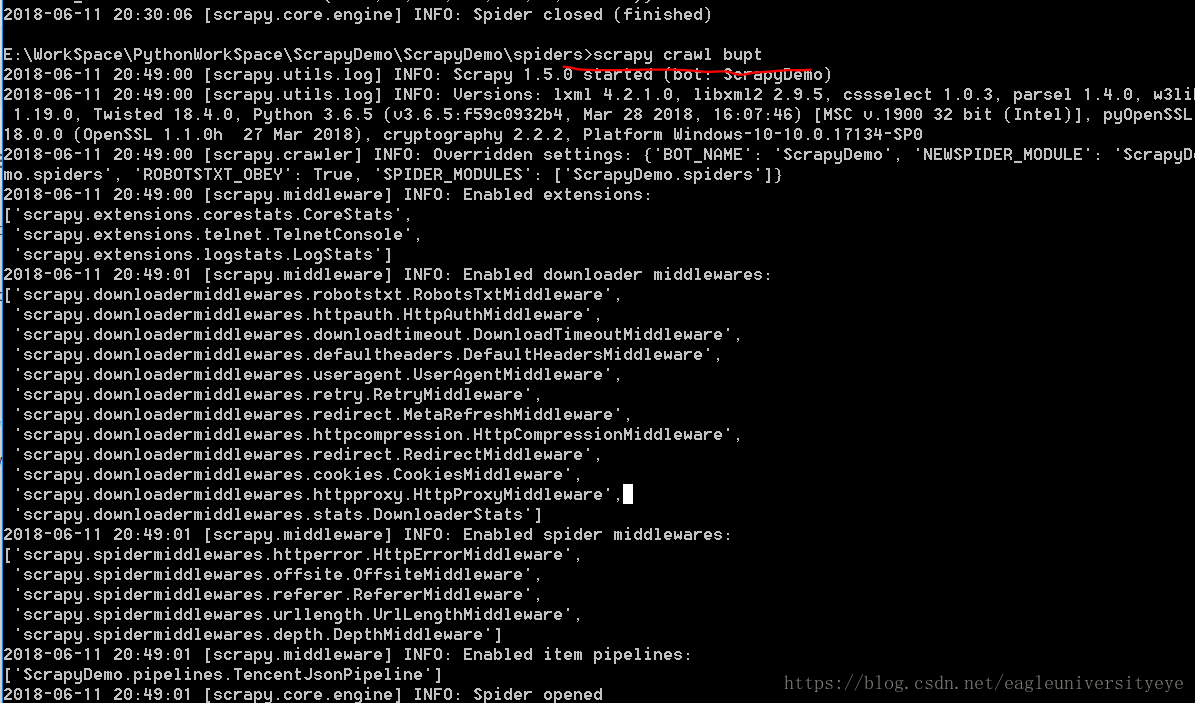
出现如图所示红圈中的200正确信号,说明爬虫爬取成功
生成了index.html文件