堆数据结构:Dijkstra算法的提速
堆的最后一个也是最高级的应用是单源最短路径问题的Dijkstra算法(第3章)的近似线性时间的实现。这个应用非常生动地体现了算法设计与数据结构设计之间的互动。
4.4.1 为什么要使用堆
我们在命题3.1中看到了Dijkstra算法的简单实现需要O(mn)的运行时间,其中m表示边的数量,n表示顶点的数量。如果只是处理中等规模的图(有数以千计的顶点和边),那么这个速度已经足够,但对于巨型的图,还是有点力不从心。我们能不能做得更好?堆能够实现具有令人惊讶的高速度,也就是近似线性时间的Dijkstra算法。
定理4.4(Dijkstra算法(基于堆)的运行时间) 对于有向图G = (V,E),起始顶点s并且所有边的长度均为非负值,Dijkstra算法基于堆的实现的运行时间是O((m+n)log n),其中m=|E|,n=|V |。
虽然O((m+n)log n)不如线性时间的搜索算法那么快速,但仍然是表现非常出色的运行时间,可以与更为出色的排序算法相提并论,基本上可以被认定为是零代价的基本算法。
让我们回忆一下Dijkstra算法的工作方式(3.2节)。这个算法维护一个顶点子集X⊆V,其中的顶点是它已经计算过最短路径长度的。在每次迭代中,它识别穿越边界的边中具有最低Dijkstra得分的边。边(v,w)的Dijkstra得分是指(已经计算的)从起始顶点到v的最短路径长度len(v)加上这条边的长度
![]()
。换句话说,主循环的每次迭代对所有跨越边界的边进行一次最小值计算。Dijkstra算法的简单实现使用穷举搜索完成这个最小值计算。把最小值计算的速度从线性时间提升为对数时间是堆的存在理由,这时我们的大脑里就会产生这样的想法:Dijkstra算法需要用到堆!
4.4.2 计划
我们应该在堆里存储什么?它们的键应该是什么?我们首先想到的是可以把输入图中的边存储在堆中,然后将目标定为把简单实现中的最小值计算(针对边)替换为ExtractMin调用。
这种思路是可行的,但是一种更取巧和快速的实现是把顶点存储在堆中。这可能会让人觉得奇怪,因为Dijkstra得分是根据边而不是顶点来定义的。但换个思路,我们之所以关注Dijkstra得分,是因为它可以指示我们接下来处理哪个顶点。我们能不能通过堆走个捷径,直接计算这个顶点呢?
具体的计划是把尚未处理的顶点(Dijkstra伪码中的V−X)存储在一个堆中,同时维护下面提到的不变性。
不变性
顶点w∈V−X的键是一条尾顶点为v∈X且头顶点为w的边的最低Dijkstra得分(如果不存在这样的边,则是+∞)。
也就是说,我们需要下面的等式

(4.1)
对于每个w∈V−X在所有时候都是成立的,其中len(v)表示在算法的一次早期迭代中所计算的v的最短路径的长度(图4.2)。

图4.2 顶点w∈V−X的键被定义为头顶点为w且尾顶点在X中的边的最低Dijkstra得分
这是怎么回事呢?想象一下,我们正在使用两轮的淘汰赛确定具有最低Dijkstra得分的边(v,w),其中v∈X,w∉X。第一轮是在每个顶点w∈V−X之间进行的本地锦标赛,参与者是边(v,w),其中v∈X且w是边的头顶点。第一轮的胜者就是最低Dijkstra得分竞赛的参与者(如果存在)。第一轮的胜者(每个顶点w∈V−X最多有1个胜者)继续进行第二轮的比赛,最终的冠军就是第一轮胜者中具有最低Dijkstra得分的那个。这条冠军边与穷举搜索所确认的边是同一条。
顶点w∈V−X的键值(式(4.1))就是w的本地锦标赛中的最低Dijkstra得分,因此,我们的不变性有效地实现了所有的第一轮竞赛。提取具有最小键值的顶点,然后开展第二轮锦标赛,闪闪发光的奖杯的持有者正是下一个需要处理的顶点,也就是跨越边界的边中具有最低Dijkstra得分的那条边的头顶点。关键在于,只要我们维持这个不变性,就可以用一个堆操作实现Dijkstra算法的每次迭代。
它的伪码如下:[14]
Dijkstra(基于堆的算法,第1部分)
输入:邻接列表表示形式的有向图G=(V, E),顶点s∈V,对于每个e∈E,其长
度e≥0。
完成状态:对于每个顶点v,len(v)的值等于真正的最短路径长度dist(s,v)。
// 初始化 1 X := 空集合, H := 空堆 2 key(s) := 0 3 for every v ≠ s do 4 key(v) := +∞ 5 for every v ∈ V do 6 把v插入到 H // 或使用Heapify // 主循环 7 while H 非空 do 8 w* := ExtractMin(H) 9 把w*加到X 10 len(w*) := key(w*) // 对堆进行更新以维持不变性 11 (待宣布)
但是,为了维持这个不变性,需要多大的工作量呢?
4.4.3 维持不变性
现在是付出“代价”的时候了。我们享受了这个不变性的成果,它把Dijkstra算法所需要的每个最小计算减少为一个堆操作。作为交换,我们必须解释怎样在不付出过多工作量的前提下维持这个不变性。
算法的每次迭代把一个顶点x从V−X移动到X,从而改变了它们之间的边界(图4.3)。从X的某个顶点出发到v的边现在完全处于X的内部,不再跨越边界。更成问题的是,从v到V−X的其他顶点的边不再完全处于V−X内部,而是从X跨越到V−X。为什么这会成为问题呢?因为我们的不变性式(4.1)表示,对于每个顶点w∈V−X,w的键等于一条终点在w的跨越边的最小Dijkstra得分。新的跨越边意味着出现了最小Dijkstra得分的新候选者,因此对于有些顶点w,式(4.1)的右边可能会变小。例如,当满足(v,w)∈E的顶点v第一次处于X的内部时,这个表达式就从+∞缩减为一个确定的数字了(即len(v)+
![]()
)。
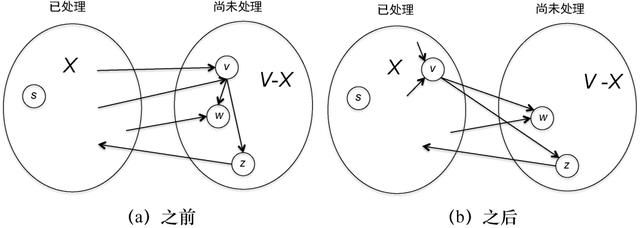
图4.3 当一个新顶点v从V−X移动到X时,从v出发的边可能成为跨越边界的边
每次当我们从堆中提取一个顶点w*并把它从V−X移动到X时,可能需要减小仍然位于V−X中的一些顶点的键值,以反映新的跨越边。由于所有的新跨越边都是从w*出发的,因此我们只需要对以w*为起点的边进行迭代,检查边(w*, y)的顶点y∈V−X。对于每个这样的顶点y,在y的本地锦标赛中,第一轮胜者有两个候选:要么与此前相同,要么就是新的参赛选手(w*, y)。因此,y的新键值要么是它的旧值,要么是新的跨越边的Dijkstra得分len(w*)+
![]()
,以更小的那个为准。
我们怎样减小堆中一个对象的键值呢?一个容易的方法是首先使用4.2.2节所描述的Delete操作将它删除,接着更新它的值,然后使用Insert操作把它添加回堆中。[15]这样,我们就完成了基于堆的Dijkstra算法的实现。
Dijkstra(基于堆的算法,第2部分)
// 对堆进行更新以维持不变性 12 for 每条边(w* ,y) do 13 从H中删除y 14 key(y) := min{ key(y), len(w*)+} 15 把y插入到H
4.4.4 运行时间
Dijkstra基于堆的实现的算法所完成的几乎所有工作都是由堆操作组成的(可以进行验证)。每个堆操作需要O(log n)的时间,其中n表示顶点的数量。(堆中对象的数量绝不可能超过n−1个。)
这个算法所执行的堆操作有多少个?基于堆的算法第1部分的第6~8行每一行都有n −1个操作,除起始顶点s之外的每个顶点均需要1个堆操作。那么基于堆的算法第2部分的第13行和第15行呢?
小测验4.2
Dijkstra将执行第13行和第15行多少次?选择适用的最小边界。(与往常一样,n和m分别表示顶点的数量和边的数量。)
(a)O(n)
(b)O(m)
(c)O(n2)
(d)O(mn)
(正确答案和详细解释如下。)
正确答案:(b)。第13行和第15行看上去可能有点奇怪。在主循环的一次迭代中,这两行被执行的次数可能多达n −1次,w*的每条外向边各执行1次。一共有n −1次迭代,看上去堆操作的数量是平方级的。对于稠密图,情况确实如此。但是一般而言,我们可以做得更好。为什么?因为我们把这些堆操作的责任交给边而不是顶点。图中的每条边(v,w)在第12行最多出现1次,也就是当v第一次从堆中被提取并从V−X转移到X时。[16]因此,第13行和第15行对于每条边最多只执行1次,总共是2m个操作,其中m是边的数量。
小测验4.2显示了Dijkstra算法基于堆的实现使用了O(m+n)的堆操作,每个操作需要O(log n)的时间。总体运行时间是O((m+n)log n),这是由定理4.4保证的。
本文摘自《算法详解(卷2)——图算法和数据结构》

本书涵盖的内容
本书介绍了下面3个主题的基础知识。
图的搜索和应用
图可用于对许多不同类型的网络,包括道路网、通信网络、社交网络,以及任务之间的依赖性网络进行建模。图可能非常复杂,但图存在一些运算速度非常快的基本算法。我们首先讨论对图进行搜索的线性算法,其应用范围极广,包括网络分析以及任务序列化等。
最短路径
在最短路径问题中,其目标是计算网络中从点A到点B的最佳路线。这个问题具有一些显而易见的应用,例如计算行车路线等。许多更为通用的规划问题的本质就是计算最短路径的问题。我们将对其中一种图搜索算法进行归纳,进而引出著名的Dijkstra最短路径算法。
数据结构
本书将帮助读者熟悉几种不同的数据结构,它们用于维护不断变化的具有键的对象集合。我们的基本目标是培养一种能力,也就是能够判断哪种数据结构比较适合自己的应用。选读的高级章节对如何从头实现这些数据结构提供了一些指导方针。
我们首先讨论堆,它可以快速识别它所存储对象中具有最小键值的对象,适用于排序、实现优先队列以及以线性时间实现Dijkstra算法。搜索树可以维护它所存储对象的整体键顺序,并支持更丰富的数组操作。散列表对超级快速的查找方式进行了优化,在现代程序中具有极其广泛的应用。我们还将讨论布隆过滤器,它是散列表的“近亲”。布隆过滤器的空间需求较散列表更低,但它偶尔会出现错误。
关于本书内容的更详细介绍,可以阅读每章的“本章要点”,它对每一章的内容,特别是那些重要的概念进行了总结。书中带星号的章节是难度较高的章节。时间较为紧张的读者在第一遍阅读时可以跳过这些章节,这并不会影响本书阅读的连续性。