PE文件结构详解(三)PE导出表
上篇文章 PE文件结构详解(二)可执行文件头 的结尾出现了一个大数组,这个数组中的每一项都是一个特定的结构,通过函数获取数组中的项可以用RtlImageDirectoryEntryToData函数,DataDirectory中的每一项都可以用这个函数获取,函数原型如下:
PVOID NTAPI RtlImageDirectoryEntryToData(PVOID Base, BOOLEAN MappedAsImage, USHORT Directory, PULONG Size);
Base:模块基地址。
MappedAsImage:是否映射为映象。
Directory:数据目录项的索引。
#define IMAGE_DIRECTORY_ENTRY_EXPORT 0 // Export Directory
#define IMAGE_DIRECTORY_ENTRY_IMPORT 1 // Import Directory
#define IMAGE_DIRECTORY_ENTRY_RESOURCE 2 // Resource Directory
#define IMAGE_DIRECTORY_ENTRY_EXCEPTION 3 // Exception Directory
#define IMAGE_DIRECTORY_ENTRY_SECURITY 4 // Security Directory
#define IMAGE_DIRECTORY_ENTRY_BASERELOC 5 // Base Relocation Table
#define IMAGE_DIRECTORY_ENTRY_DEBUG 6 // Debug Directory
// IMAGE_DIRECTORY_ENTRY_COPYRIGHT 7 // (X86 usage)
#define IMAGE_DIRECTORY_ENTRY_ARCHITECTURE 7 // Architecture Specific Data
#define IMAGE_DIRECTORY_ENTRY_GLOBALPTR 8 // RVA of GP
#define IMAGE_DIRECTORY_ENTRY_TLS 9 // TLS Directory
#define IMAGE_DIRECTORY_ENTRY_LOAD_CONFIG 10 // Load Configuration Directory
#define IMAGE_DIRECTORY_ENTRY_BOUND_IMPORT 11 // Bound Import Directory in headers
#define IMAGE_DIRECTORY_ENTRY_IAT 12 // Import Address Table
#define IMAGE_DIRECTORY_ENTRY_DELAY_IMPORT 13 // Delay Load Import Descriptors
#define IMAGE_DIRECTORY_ENTRY_COM_DESCRIPTOR 14 // COM Runtime descriptorSize:对应数据目录项的大小,比如Directory为0,则表示导出表的大小。
返回值表示数据目录项的起始地址。
这次来看看第一项:导出表。导出表是用来描述模块中的导出函数的结构,如果一个模块导出了函数,那么这个函数会被记录在导出表中,这样通过GetProcAddress函数就能动态获取到函数的地址。函数导出的方式有两种,一种是按名字导出,一种是按序号导出。这两种导出方式在导出表中的描述方式也不相同。模块的导出函数可以通过Dependency walker工具来查看:

上图中红框位置显示的就是模块的导出函数,有时候显示的导出函数名字中有一些符号,像 ??0CP2PDownloadUIInterface@@QAE@ABV0@@Z,这种是导出了C++的函数名,编译器将名字进行了修饰。
下面看一下导出表的定义吧:
typedef struct _IMAGE_EXPORT_DIRECTORY {
DWORD Characteristics;
DWORD TimeDateStamp;
WORD MajorVersion;
WORD MinorVersion;
DWORD Name;
DWORD Base;
DWORD NumberOfFunctions;
DWORD NumberOfNames;
DWORD AddressOfFunctions; // RVA from base of image
DWORD AddressOfNames; // RVA from base of image
DWORD AddressOfNameOrdinals; // RVA from base of image
} IMAGE_EXPORT_DIRECTORY, *PIMAGE_EXPORT_DIRECTORY;结构还算比较简单,具体每一项的含义如下:
Characteristics:现在没有用到,一般为0。
TimeDateStamp:导出表生成的时间戳,由连接器生成。
MajorVersion,MinorVersion:看名字是版本,实际貌似没有用,都是0。
Name:模块的名字。
Base:序号的基数,按序号导出函数的序号值从Base开始递增。
NumberOfFunctions:所有导出函数的数量。
NumberOfNames:按名字导出函数的数量。
AddressOfFunctions:一个RVA,指向一个DWORD数组,数组中的每一项是一个导出函数的RVA,顺序与导出序号相同。
AddressOfNames:一个RVA,依然指向一个DWORD数组,数组中的每一项仍然是一个RVA,指向一个表示函数名字。
AddressOfNameOrdinals:一个RVA,还是指向一个WORD数组,数组中的每一项与AddressOfNames中的每一项对应,表示该名字的函数在AddressOfFunctions中的序号。
第一次接触这个结构的童鞋被后面的5项搞晕了吧,理解这个结构比结构本身看上去要复杂一些,文字描述不管怎么说都显得晦涩,所谓一图胜千言,无图无真相,直接上图:
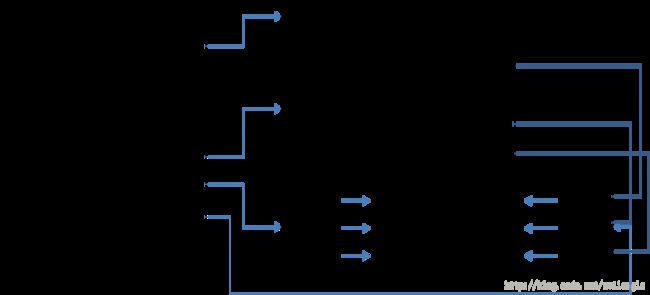
在上图中,AddressOfNames指向一个数组,数组里保存着一组RVA,每个RVA指向一个字符串,这个字符串即导出的函数名,与这个函数名对应的是AddressOfNameOrdinals中的对应项。获取导出函数地址时,先在AddressOfNames中找到对应的名字,比如Func2,他在AddressOfNames中是第二项,然后从AddressOfNameOrdinals中取出第二项的值,这里是2,表示函数入口保存在AddressOfFunctions这个数组中下标为2的项里,即第三项,取出其中的值,加上模块基地址便是导出函数的地址。如果函数是以序号导出的,那么查找的时候直接用序号减去Base,得到的值就是函数在AddressOfFunctions中的下标。
用代码实现如下:
DWORD* CEAT::SearchEAT( const char* szName)
{
if (IS_VALID_PTR(m_pTable))
{
bool bByOrdinal = HIWORD(szName) == 0;
DWORD* pProcs = (DWORD*)((char*)RVA2VA(m_pTable->AddressOfFunctions));
if (bByOrdinal)
{
DWORD dwOrdinal = (DWORD)szName;
if (dwOrdinal < m_pTable->NumberOfFunctions && dwOrdinal >= m_pTable->Base)
{
return &pProcs[dwOrdinal-m_pTable->Base];
}
}
else
{
WORD* pOrdinals = (WORD*)((char*)RVA2VA(m_pTable->AddressOfNameOrdinals));
DWORD* pNames = (DWORD*)((char*)RVA2VA(m_pTable->AddressOfNames));
for (unsigned int i=0; iNumberOfNames; ++i)
{
char* pNameVA = (char*)RVA2VA(pNames[i]);
if (strcmp(szName, pNameVA) != 0)
{
continue;
}
return &pProcs[pOrdinals[i]];
}
}
}
return NULL;
} by evil.eagle 转载请注明出处。
http://blog.csdn.net/evileagle/article/details/12176797