关于RNN的核心点理解
参考文献
1.非常棒的知乎回答,直观明确
2.RNN译文和理解,很详细
3.深度学习实战教程(五):循环神经网络
4.深度学习实战教程(六):长短时记忆网络(LSTM)
5.用「动图」和「举例子」讲讲 RNN
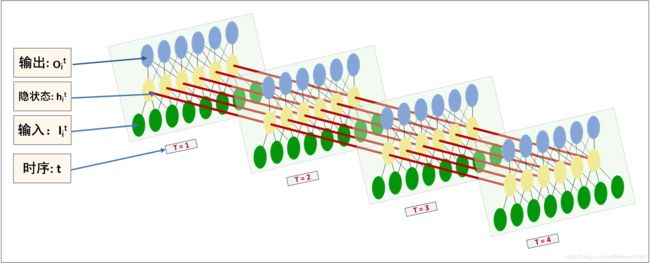
1.RNN说什么
首先,对于RNN基本的内容,这里不做介绍,因为现有博客都介绍的很好,从起源到发展,很好理解。
概括起来,相较于CNN中,各数据不相关的情况,RNN聚焦的是序列信息的处理,目的是更好刻画序列数据之间的相互关系。
2.RNN模型把握的关键性位置
【1】首先,提到RNN,头脑里要想到的是上面这张三维示意图!!!
这张图区别于常见博客中二维的示意图,很好地把握了RNN的结构特点;
【2】就单个time_step来说,其就是一个MLP,因为其有输入层,隐层、输出层这些基本结构,就类似下图所示。而在整个RNN结构中,把它立起来,就是上图的T=1的部分。

【3】关于权值共享,每一个time_step中的W全是相同的,U 和 V 也一样。这也就是说,实际上RNN是在复用同一个MLP结构。这一点根据 TensorFlow 中的 RNN 源码也可知, RNN 的一次dynamic_run即是将每个MLP的hidden cell的_call()函数在整个time_step上连续地调用L次,已达到时序传递计算的目的。
参数共享本质上就是说明该模块功能完全相同;在任何一个时间步上,细胞的功能是相同的;这样才能在不同步检测出相同内容。
【4】至于LSTM、RGU这些衍生内容,那就是在MLP的每个hidden cell(一个黄色circle)与下一个time_step 的hidden cell的传值机制的更复杂的技术。
3.通过一个具体例子来分析流程
如果我有一条长文本,我把这一长文本事先分割为句子,并且进行令牌化、词典化,接着再通过查找现有的词嵌入表查找到对应嵌入表示向量,将词语由嵌入向量表示,再对应到上图的输入。
流程如下:
step1. (原始文本是下面所示的多个句子):
接触LSTM模型不久,简单看了一些相关的论文,还没有动手实现过。然而至今仍然想不通LSTM神经网络究竟是怎么工作的。……
step2. tokenize (对每个句子进行中文分词):
sentence1: 接触 LSTM 模型 不久 ,简单 看了 一些 相关的 论文 , 还 没有 动手 实现过 。
sentence2: 然而 至今 仍然 想不通 LSTM 神经网络 究竟是 怎么 工作的。
……
step3. dictionarize(令牌化,有点像编码):
sentence1: 1 34 21 98 10 23 9 23
sentence2: 17 12 21 12 8 10 13 79 31 44 9 23
……
step4. padding every sentence to fixed length(一种填充0的操作,目的是使得每个句子的长度一致,便于处理):
sentence1: 1 34 21 98 10 23 9 23 0 0 0 0 0
sentence2: 17 12 21 12 8 10 13 79 31 44 9 23 0
……
step5. mapping token to an embeddings(把每个词对应到嵌入向量,在已有数据集的情况下,就是对应查找):

step6. feed into RNNs as input::
假设 一个RNN的time_step 确定为L ,则padded sentence length(step5中矩阵列数)固定为L。一次RNNs的run只处理一条sentence。每个sentence的每个token的embedding对应了每个时序 t 的输入 Iit 。一次RNNs的run,连续地将整个sentence处理完。
step6的关键注解:
(1)time_step为L,就是说RNN的整体结构长度是L,就是说 t 的取值最大就是L;
(2)这对应到输入数据,就是说:已知在步骤5里面,对每个句子,我们对每个词语进行了词嵌入操作,每个词对应了一个词向量,就是矩阵中的一列。这个矩阵是一个句子的表示,对这个矩阵,我们还进行了补0操作,使得该矩阵的列数保持一致,也就是使得每个句子的词的长度保持一致,这一操作的理由是便于处理,也就是便于输入。因为我们的time_step已经确定为了L,因此这个矩阵的列数也就是L。
(3)一次RNN的run只处理一个句子,这句话的意思就是说一次的输入是一个句子的矩阵,由于我们前面已经将time_step和矩阵的列数统一为L,因此,这个矩阵是和RNN的输入完全对应的,也就是相当于每一个列向量(实际就是一个词语)对应最上面图中每个时序 t 的It。
step7. get output(输出):
看图,每个time_step都是可以输出当前时序 t 的隐状态 hit ;但整体RNN的输出 oit 是在最后一个time_step t=L 时获取,才是完整的最终结果。
step8. further processing with the output(相关改进和衍生):
我们可以将output根据分类任务或回归拟合任务的不同,分别进一步处理。比如,传给cross_entropy&softmax进行分类……或者获取每个time_step对应的隐状态 ,做seq2seq 网络……或者搞创新……
4.对于具体实现的内容
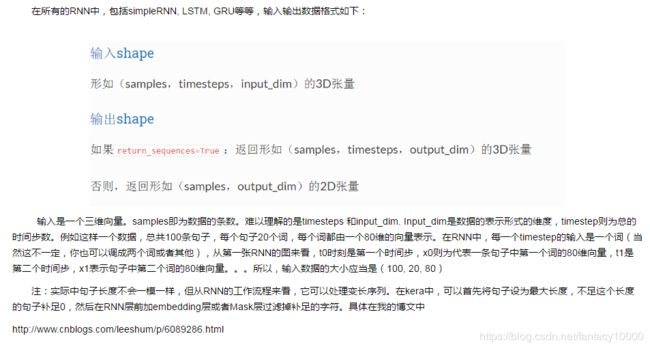
在通过Keras实现过程中,对于所有的RNN,包括simpleRNN, LSTM, GRU等,输入输出数据格式如下:
用「动图」和「举例子」讲讲 RNN
这一篇对于各维度的解释很直观。其中重点区分了time_step和batch。总的来说,time_step是神经网络的参数,网络建好了便不会改变;batch是训练参数,在训练时可根据效果随时调整。
5.对于BPTT推导的流程理解
BPTT算法是针对循环层的训练算法,它的基本原理和BP算法是一样的,也包含同样的三个步骤:
【step1】前向计算每个神经元的输出值;
【step2】反向计算每个神经元的误差项 δj 值,它是误差函数 E 对神经元 j 的加权输入 netj 的偏导数;
【step3】计算每个权重的梯度;
最后再用随机梯度下降算法更新权重。
需要注意的是:
BPTT算法将第 l 层 t 时刻的误差项 δlt 值沿两个方向传播!!
【1】一个方向是其传递到上一层网络,得到 δl−1t,这部分只和权重矩阵U有关;(纵向,单个MLP里的)
【2】另一个是方向是将其沿时间线传递到初始 t1 时刻,得到δl1,这部分只和权重矩阵W有关。(横向)
横向:


纵向:

最终具体到W矩阵的计算:

注:之所以误差对于W矩阵的梯度是t时刻前各个时刻梯度之和,是因为误差是从输出反馈到W的,考虑到各个time_step都是有输出的,因此对于每一个输出,W都是有相应梯度的,所以是t时刻前的各个时刻梯度之和。
需要注意的是,这里的各个时刻,指的是t之前的各个时刻,这是因为RNN是时序网络,同时权值W,U,V是共享的,这决定了到时刻t时,前面1~t-1的时刻间是有关联的,而且这些时刻间的权值是共享的,所以之和就很好理解了。
当然实际上是没有必要像上面那样分的那么细(实际上上面说的是具体的计算步骤),因为在实际实现中,每次处理的是一整个句子,这样一次完整的前向传播,是覆盖完整的T的,因此在这样的前向传播后,进行的反向传播误差计算,也就是从T时刻开始,因此对于W的梯度,也就是所有时刻的梯度之和。
6.由BPTT衍生出的梯度消失和梯度爆炸问题
本质上因为误差在 横向传递 时是连乘的,这使得误差项的增长或者缩小会非常快。

RNN的形象描述
RNN模仿了人的记忆功能,它把昨天的记忆传给今天,然后做个总结,把今天的总结又传给明天,这使得它能够记住之前的事情,但是由于它大脑容量有限,本身智商低,总结能力差,记忆力差,所以每天都传一些乱七八糟的给第二天,以至于时间长了,之前的很难记得清。