利用 python 分析基金,合理分析数据让赚钱赢在起跑线!
前言
本文的文字及图片来源于网络,仅供学习、交流使用,不具有任何商业用途,版权归原作者所有,如有问题请及时联系我们以作处理。
作者: 白玉无冰
PS:如有需要Python学习资料的小伙伴可以加点击下方链接自行获取
http://note.youdao.com/noteshare?id=3054cce4add8a909e784ad934f956cef
你不理财,财不理你!python 也能帮你理财?

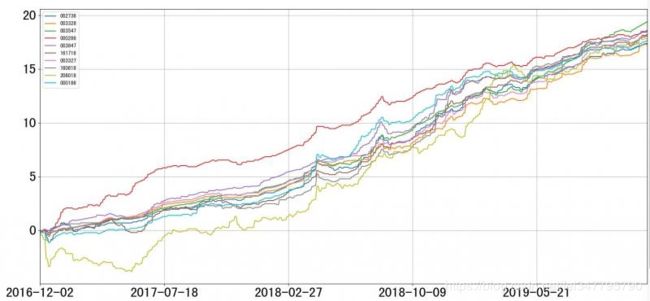
效果预览
累计收益率走势图
基本信息结果

如何使用:
python3 + 一些第三方库
import requests
import pandas
import numpy
import matplotlib
import lxml
配置 config.json 。code 配置基金代码, useCache 是否使用缓存。
{
"code":[
"002736",
"003328",
"003547",
],
"useCache":true
}
运行 fund_analysis.py
实现原理
数据获取:
从天天基金网里点开一个基金,在 chrome 开发者工具观察加载了的文件。依次查找发现了一个 js 文件,里面含有一些基金的基本信息。这是一个 js 文件。
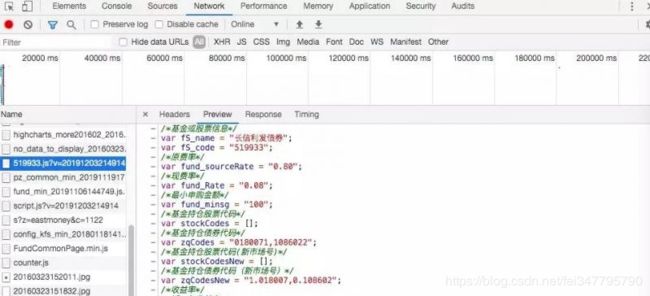
获取累计收益率信息需要在页面做些操作,点击累计收益里的3年,观察开发者工具的请求,很容易找到这个数据源是如何获取的。这是个 json 数据。

基金费率表在另一个页面,我们多找几次可以找到信息源地址。这是个 html 数据。

接着通过对 Hearders 的分析,用 request 模拟浏览器获取数据(这里不清楚的话可以参考之前的文章)。最后将其保存在本地作为缓冲使用。以累计收益率信息 json 为例子,主要代码如下。
filePath = f'./cache/{fundCode}.json'
requests_url='http://api.fund.eastmoney.com/pinzhong/LJSYLZS'
headers = {
'user-agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_14_4) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/78.0.3904.87 Safari/537.36',
'Accept': 'application/json' ,
'Referer': f'http://fund.eastmoney.com/{fundCode}.html',
}
params={
'fundCode': f'{fundCode}',
'indexcode': '000300',
'type': 'try',
}
requests_page=requests.get(requests_url,headers=headers,params=params)
with open(filePath, 'w') as f:
json.dump(requests_page.json(), f)
数据分析:
对于 基本信息的 js 文件,读取文件后作为字符串,通过正则表达式获取需要的数据。
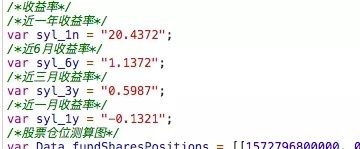
例如获取一年收益率可以用以下代码获取。
syl_1n=re.search(r'syl_1n\s?=\s?"([^\s]*)"',data).group(1);
对于 累计收益率 json 数据,直接用 json 解析,找到需要数据进行筛选加工处理。
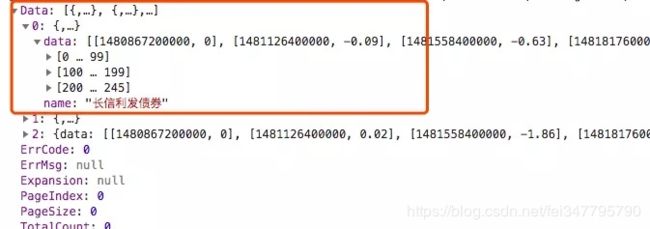
采用了 all_data[基金代码][时间] = 累计收益率 的格式存储,再通过 pandas 的 DataFrame 进行向上填充空数据。
df = DataFrame(all_data).sort_index().fillna(method='ffill')
对于 基金费率表 html 数据,采用 xpath 解析。xpath 路径可以直接用 chrome 获取。

对于管理费率可以参考以下代码。
selector = lxml.html.fromstring(data);
# 管理费率
mg_rate=selector.xpath('/html/body/div[1]/div[8]/div[3]/div[2]/div[3]/div/div[4]/div/table/tbody/tr/td[2]/text()')[0]
数据存储:
使用 DataFrame 中的 plot 可以快速画图,使用 to_excel 保存在 Excel 表中。可以参考以下代码。
# 保存数据
fig,axes = plt.subplots(2, 1)
# 处理基本信息
df2 = DataFrame(all_data_base)
df2.stack().unstack(0).to_excel(f'result_{time.time()}.xlsx',sheet_name='out')
df2.iloc[1:5,:].plot.barh(ax=axes[0],grid=True,fontsize=25)
# 处理收益
df=DataFrame(all_data).sort_index().fillna(method='ffill')
df.plot(ax=axes[1],grid=True,fontsize=25)
fig.savefig(f'result_{time.time()}.png')
小结
数据的获取主要采用了爬虫的基本方法,使用的是 requests 库。而数据的解析和保存主要运用的是正则表达式、xpath解析库以及 pandas 数据处理库。
对于一个基金的分析远远不止于这些数据(例如持仓分布,基金经理信息等),这里只是做个引子,希望能给大家一个思路,如果你有想法或者不懂的地方,欢迎留言或私信交流!